初见spark-02(RDD及其简单算子)
Posted 蜗牛不爱海绵宝宝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初见spark-02(RDD及其简单算子)相关的知识,希望对你有一定的参考价值。
今天,我们来进入spark学习的第二章,发现有很多事都已经开始变化,生活没有简单的朝自己想去的方向,但是还是需要努力呀,不说鸡汤之类的话了,
开始我们今天的spark的旅程
一.RDD是什么
rdd的中文解释为弹性分布式数据集,全称Resilient Distributed Datases,即内存中的数据集,
RDD只读,可分区,这个数据集的全部或部分可以缓存到内存之中,在多次时间间重用,所谓
弹性,是指内存不够是可以与磁盘进行互换
二.spark算子
spark算子一共分为两类,一类叫做Transformation(转换),一类叫做Action(动作)
Transformation延迟执行,Transformation会记录元数据信息,当计算任务触犯Action才开始真正的执行(这个上一个章节也介绍过)
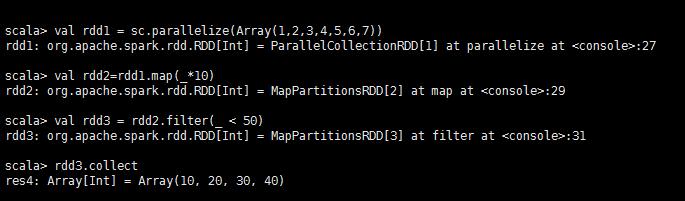
这个里面起前面无论是map还是filter的方法,都是transform方法,所以这个值并没有真正的别改变,直到collect,这个是Action,则它真正的值才会被调用
三.创建RDD的两种方式
1.通过HDFS支持的文件系统创建RDD,RDD里面没有真正要计算的数据,只记录一下元数据
2.通过scala集合或数组以并行化的方式创建RDD
看一下内部实现对于RDD的概括(5个特点)
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- Alist of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block · locations an HDFS file)
四.spark在IDEA上的第一个程序
1.首先我们先在idea上写一个spark程序,然后package
object WordCount {
def main(args: Array[String]): Unit = {
//非常重要,通向spark集群的入口
val conf = new SparkConf().setAppName("WC")
val sc = new SparkContext(conf)
sc.textFile(args(0)).flatMap(_.split(" ")).map(((_,1))).reduceByKey(_+_).sortBy(_._2).saveAsTextFile(args(1))
sc.stop()
}
}
首先先要澄清一点,这个里面我们的spark是采用maven的形式来创建的,所以我们的pom文件加上上对spark的支持
我们在package的时候,会在target中生成两个jar包,我们选容量大的,应为可能要包括其他的库
2.上传到Linux上面,并提交(这个里面和在hadoop上面执行jar包很相似)
./spark-submit --master spark://192.168.109.136:7077 --class cn.wj.spark.WordCount --executor-memory 512m --total-executor-cores 2 /tmp/hello-spark-1.0.jar hdfs://192.168.109.136:9000/wc/* hdfs://192.168.109.136:9000/wc/out
即可,这个时候我们可以通过192.168.109.136:8080可以查看当前spark的项目执行情况
五.Master与Worker的关系
Master管理所有的Worker,进而进行资源的调度,Worker管理当前的节点,Worker会启动Executor来完成真正的计算
以上是关于初见spark-02(RDD及其简单算子)的主要内容,如果未能解决你的问题,请参考以下文章