机器学习——树回归
Posted tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——树回归相关的知识,希望对你有一定的参考价值。
线性回归创建模型需要拟合所有的样本点(局部加权线性回归除外)。当数据拥有众多特征并且特征之间关系十分复杂的时候,构建全局模型的想法就显得太难了,也略显笨拙。而且,实际生活中很多问题都是非线性的,不可能使用全局限性模型来拟合任何数据。
一种可行的方法是将数据集切分成很多份易建模的数据,然后再利用线性回归技术来建模。如果首次切分之后仍然难以拟合线性模型就继续切分。
决策树是一种贪心算法,它要在给定时间内做出最佳选择,但是并不关心能否达到全局最优。
CART(classification and regression trees,分类回归树)
之前使用过的分类树构建算法是ID3,ID3决策树学习算法是以信息增益为准则来选择划分属性。ID3的做法是每次选取当前最佳的特征来分割数据,并按照该特征的所有可能取值来切分。也就是说,如果一个特征有4种取值,那么数据将被切成4份。一旦按某特征切分后,该特征在之后的算法执行过程中将不会再起作用,所以所以有观点认为这种切分方式过于迅速。另外一种方法是二元切分法,即每次把数据集切成两份。如果数据的某特征值等于切分所要求的值,那么这些数据就进入树的左子树,反之则进入树的右子树。
ID3算法还存在另一个问题,它不能直接处理连续性数据。只有事先将连续特征转换成离散型,才能在ID3算法中使用。
CART算法使用二元切分来处理连续型变量。对CART稍作修改就可以处理回归问题。CART决策树使用“基尼指数”来选择划分属性,基尼值是用来度量数据集的纯度。

from numpy import *
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split(\'\\t\')
fltLine = map(float,curLine) #map all elements to float()
dataMat.append(fltLine)
return dataMat
def plotBestFit(file): #画出数据集
import matplotlib.pyplot as plt
dataMat=loadDataSet(file) #数据矩阵和标签向量
dataArr = array(dataMat) #转换成数组
n = shape(dataArr)[0]
xcord1 = []; ycord1 = [] #声明两个不同颜色的点的坐标
#xcord2 = []; ycord2 = []
for i in range(n):
xcord1.append(dataArr[i,0]); ycord1.append(dataArr[i,1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c=\'green\', marker=\'s\')
#ax.scatter(xcord2, ycord2, s=30, c=\'green\')
plt.xlabel(\'X1\'); plt.ylabel(\'X2\');
plt.show()
def binSplitDataSet(dataSet, feature, value): #该函数通过数组过滤方式将数据集合切分得到两个子集并返回
mat0 = dataSet[nonzero(dataSet[:,feature] > value)[0],:][0]
mat1 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:][0]
return mat0,mat1
def regLeaf(dataSet): #建立叶节点函数,value为所有y的均值
return mean(dataSet[:,-1])
def regErr(dataSet): #平方误差计算函数
return var(dataSet[:,-1]) * shape(dataSet)[0] #y的方差×y的数量=平方误差
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)): #最佳二元切分方式
tolS = ops[0]; tolN = ops[1] #tolS是容许的误差下降值,tolN是切分的最少样本数
#如果剩余特征值的数量等于1,不需要再切分直接返回,(退出条件1)
if len(set(dataSet[:,-1].T.tolist()[0])) == 1:
return None, leafType(dataSet)
m,n = shape(dataSet)
#the choice of the best feature is driven by Reduction in RSS error from mean
S = errType(dataSet) #计算平方误差
bestS = inf; bestIndex = 0; bestValue = 0
for featIndex in range(n-1):
#循环整个集合
for splitVal in set(dataSet[:,featIndex]): #每次返回的集合中,元素的顺序都将不一样
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal) #将数据集合切分得到两个子集
#如果划分的集合的大小小于切分的最少样本数,重新划分
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continue
newS = errType(mat0) + errType(mat1) #计算两个集合的平方误差和
#平方误差和newS小于bestS,进行更新
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
#在循环了整个集合后,如果误差减少量(S - bestS)小于容许的误差下降值,则退出,(退出条件2)
if (S - bestS) < tolS:
return None, leafType(dataSet)
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue) #按照保存的最佳分割来划分集合
#如果切分出的数据集小于切分的最少样本数,则退出,(退出条件3)
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN):
return None, leafType(dataSet)
#返回最佳二元切割的bestIndex和bestValue
return bestIndex,bestValue
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):#assume dataSet is NumPy Mat so we can array filtering
feat, val = chooseBestSplit(dataSet, leafType, errType, ops) #采用最佳分割,将数据集分成两个部分
if feat == None: return val #递归结束条件
retTree = {} #建立返回的字典
retTree[\'spInd\'] = feat
retTree[\'spVal\'] = val
lSet, rSet = binSplitDataSet(dataSet, feat, val) #得到左子树集合和右子树集合
retTree[\'left\'] = createTree(lSet, leafType, errType, ops) #递归左子树
retTree[\'right\'] = createTree(rSet, leafType, errType, ops) #递归右子树
return retTree
mian.py
# coding:utf-8 # !/usr/bin/env python import regTrees import matplotlib.pyplot as plt from numpy import * if __name__ == \'__main__\': myDat = regTrees.loadDataSet(\'ex00.txt\') myMat = mat(myDat) print myMat.T Tree = regTrees.createTree(myMat) print Tree regTrees.plotBestFit(\'ex00.txt\')
结果只是切分成两个子树

再查看原来的数据集的分布
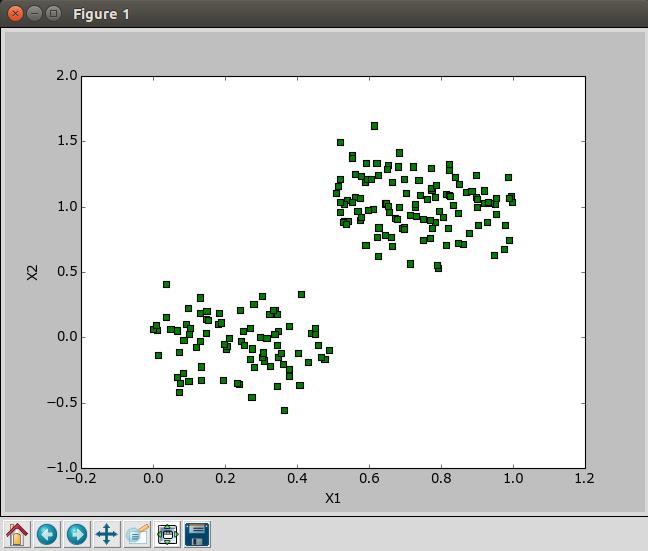
如果换一个数据集的话

则子树的数量变多,再查看原来数据集的分布

一棵树如果节点过多,表示该模型可能对数据进行了“过拟合”。通过降低决策树的复杂度来避免过拟合的过程称为剪枝(pruning)。
剪枝分为预剪枝(prepruning)和后剪枝(postpruning)。
预剪枝是指在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能的提升,则停止划分并将当前节点记为叶节点(上面的程序已经使用了预剪枝);
后剪枝则是先在训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶节点。
使用后剪枝方法需要将数据集分成测试集和训练集。首先指定参数,使得构建出的树足够大、足够复杂,便于剪枝。接下来从上而上找到叶节点,用测试集来判断将这些叶节点合并是够能降低测试误差。如果是的话就进行合并。
#####################回归树剪枝函数#####################
def isTree(obj): #该函数用于判断当前处理的是否是叶节点
return (type(obj).__name__==\'dict\')
def getMean(tree): #从上往下遍历树,寻找叶节点,并进行塌陷处理(用两个孩子节点的平均值代替父节点的值)
if isTree(tree[\'right\']): tree[\'right\'] = getMean(tree[\'right\'])
if isTree(tree[\'left\']): tree[\'left\'] = getMean(tree[\'left\'])
return (tree[\'left\']+tree[\'right\'])/2.0
def prune(tree, testData): #后剪枝,tree是待剪枝的树,testData是用于剪枝的测试参数
#如果测试集为空,进行塌陷处理,最后将会剩下两个叶节点
if shape(testData)[0] == 0:
return getMean(tree)
#如果测试集非空,按照保存的回归树对测试集进行切分
if (isTree(tree[\'right\']) or isTree(tree[\'left\'])):
lSet, rSet = binSplitDataSet(testData, tree[\'spInd\'], tree[\'spVal\'])
if isTree(tree[\'left\']):
tree[\'left\'] = prune(tree[\'left\'], lSet)
if isTree(tree[\'right\']):
tree[\'right\'] = prune(tree[\'right\'], rSet)
#左右子树都是叶子节点,对合并前后的误差进行比较,如果合并后的误差比不合并的误差小就进行合并操作,否则直接返回
if not isTree(tree[\'left\']) and not isTree(tree[\'right\']):
lSet, rSet = binSplitDataSet(testData, tree[\'spInd\'], tree[\'spVal\'])
errorNoMerge = sum(power(lSet[:,-1] - tree[\'left\'],2)) + sum(power(rSet[:,-1] - tree[\'right\'],2)) #不合并的误差
treeMean = (tree[\'left\']+tree[\'right\'])/2.0
errorMerge = sum(power(testData[:,-1] - treeMean,2)) #合并的误差
if errorMerge < errorNoMerge: #比较
print "merging"
return treeMean
else: return tree
else: return tree
大量的节点已经被剪枝掉了,但是并没有像预期的那样剪枝成两个部分,说明后剪枝可能不如预剪枝有效。一般地,为了寻求最佳模型可以同时使用两种剪枝技术。
以上是关于机器学习——树回归的主要内容,如果未能解决你的问题,请参考以下文章
机器学习之路: python 回归树 DecisionTreeRegressor 预测波士顿房价
实验三:CART回归决策树python实现(两个测试集)|机器学习