第三方舆情收集与质量闭环建设
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三方舆情收集与质量闭环建设相关的知识,希望对你有一定的参考价值。
【案例背景】
软件研发过程经历了三个阶段,从瀑布式开发、至敏捷、至精益,不同研发理念背后对质量有着不同诉求。在硬件性能依据摩尔定律爆发式增长的八九十年代,高级语言面世,微机普及,软件需求爆发式增长。当时的实践发现,面临复杂大型软件工程,往往项目失败率高,因而有强烈的对软件工程理论的诉求,瀑布开发模式走上了历史舞台。这种模式下,对测试团队的诉求是交付完美吻合规格说明(specification)的软件产品,核心待解决的问题是用较低成本高效覆盖测试点,因而在这个时代各种测试设计方法得以长足的进步。
之后随着零零年前后互联网的起伏,互联网企业为了快速响应用户多变的诉求,软件工程的核心诉求发生了变化,从严格按图纸施工的瀑布式开发,转而追求质量与效率的平衡。在这个时期,“敏捷模式”大行其道,为了实现敏捷而持续集成,为了实习持续集成而自动化,多半测试团队在风风火火地进行自动化改造,各种工具平台应运而生,直至今日。
敏捷的基础上提出的精益理念,构建了从产品到用户的闭环,所谓小步快跑,产品需要第一时间被用户见到,收集用户的数据和观点,从而不断修正产品形态。一次境外会议上听到一句挺有意思的话:If you release a product that doesn’t embarrassed you, it only meansthat you could release sooner. (如果你发布的产品很完美,不令你感到尴尬,只能说明产品发布得太晚了)。精益模式在用户用脚投票的互联网行业中尤为适用,著名的Facebook即采用类似的方式研发产品。收集用户对新增功能的反馈,并将反馈融入产品迭代过程中,是一件对互联网产品越来越重要的事。
弯弯绕绕赘述了冗长的背景,让我们切入正题。获取用户反馈,除了从用户行为分析入手外,主动收集用户投诉(客服途径、产品的反馈表单)和被动获取用户反馈信息,都是协同产品迭代的重要补充。本次分享讲述了百度建立反馈体系与质量闭环的过程,详细讲述第三方舆情反馈的架构实践要点与细节。期望对有类似诉求的企业和团队,提供参考经验。
【解决方案综述】
整体工程架构,讲分为三个部分展开描述,分别是数据抓取、数据清洗、数据输出。数据抓取面临的困难是应对第三方数据源的格式变更与屏蔽策略,在多变的内外部环境下确保数据流时效性,是工程实践过程中较困难的方面。数据清洗主要解决抓取反馈数据的精粹提纯,怎样平衡时延、准召、成本,是这个部分需要讨论的话题。数据输出解决的问题是平衡好一个基础架构与业务之间的关系,我们看到不少同类系统,最终深陷于各种多样需求难以自拔,在这里我们会给出一些解答思路。整体架构见下图。
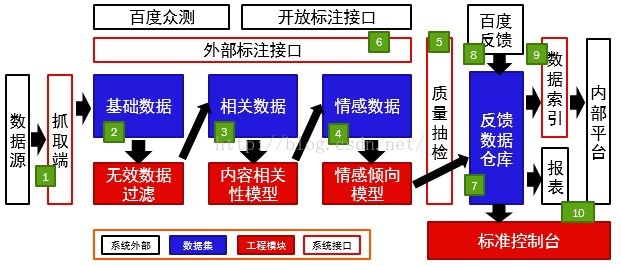
一、数据抓取
第三方舆情的数据源囊括:微博、百度贴吧、各大应用商店、新闻、搜索、论坛,主要设计考虑以下三方面需求。1)应对多数据源的格式变更,可低成本维护;2)应对突发事件与需求,可快速大量回溯;3)应对数据源的屏蔽策略,可自适应调整。
百度主打搜索引擎,有着深厚的数据抓取积累。我们利用大多数浏览器自带的节点定位功能,能便捷地获取一个网页中任意节点的DOM结构。单一抓取进程应能以该结构作为配置快速提取希望获得的元素信息,这样,我们就能以统一的程序,通过参数传入方式,抓取任意页面中的任意内容。每一个抓取进程将被“调度器(scheduler)”分配待抓取的链接列表与对应配置,独立工作,互不干扰,并自有延迟与异常处理。当一个抓取进程长时无返回,或返回失败时,调度端将相应任务分配于其它IP段的新起抓取进程再度重试,只至最终成功、或多次尝试后仍失败。外部数据源的屏蔽策略与网页结构升级经常会导致抓取失败,此时,系统应及时检测问题,由人工介入干预。由于采用了标准配置项,介入工作只需确定抓取失败的页面仍能打开,重新定位到变更后的元素节点,测试配置后重新抓取,这项工作可由无技术经验的产品人员、实习生、外包来担负,极大程度降低了维护成本。综上,是抓取逻辑的简要描述,也顺带回答了第一个问题,通过工程设计的解耦与隔离,大量新增和变更的数据源维护变得简单快捷。
设计中更值得注意的部分是应对两类异常,突增吞吐、数据源屏蔽。在很多情况下数据源的抓取任务会积压,可能是某一重要业务应老板要求要回溯半年来的数据,可能是某一产品在活动期间数据量突增,可能是系统故障或触发屏蔽导致大量抓取任务延迟。在这里,我们描述下“调度器”部分的工作原理。“调度器”在抓取系统的边界限制下,分配系统的资源,主要是带宽资源、IP资源、账号(某些抓取需登录状态)资源。在任务密集无法完全完成的前提下,优先让高优任务插队,并在插队完成后的间隙,填充次优任务,以此类推。例如某一高优任务需抓取某一数据源,但限于抓取频次,带宽仍有富余,这时会依据富余量填充剩余任务,使抓取吞吐尽量饱和。另,系统也应支持扩容,以便填补新增硬件资源,以及轮休被暂时屏蔽的IP段。
接着谈一下屏蔽策略相关内容,通常网站对某账号或IP封禁的主因无非是保护内容与防攻击。简单的禁封策略,只是一个计数归并,在一分钟、五分钟、十五分钟、一小时的时间窗内,同一账户或IP地址访问次数多过一定的阈值,往往被认为非用户行为,此时会引导手机号验证等动作,若抓取系统无容错仍坚持机械重试,会被永久禁封,需人工沟通后解禁。较复杂的策略主要是离线的异点分析,某个数值,可以是访问间隔的方差,可以是单位时间的访问次数的方差,可以是访问链接类型的分布,通过统计方法,识别出离群点,随机加以屏蔽认证。前者我们会做一个隔离的测试资源,对新数据源逐渐逼近上限,反解出策略配置,使得抓取变得高效;后者没有太好的办法,但所幸绝大多数数据源不会使用这种过于麻烦的方式。应对屏蔽策略的方案是,不熟悉的数据源需隔离测试一段时间,以免影响主系统抓取使用的IP段;发现被屏蔽及时停止抓取以免被进一步拉黑;提前准备多套备案,确保数据在各种情况下均能到位。
最后谈一下备案策略。我们会留出足够的闲置的IP段与账号,供屏蔽时及时更替。终极备案是利用众测,在用户客户端抓取后传回。“众测”提供客户端,用户可在使用个人电脑或手机时打开共享资源,并以资源使用情况获得付费。我们的抓取终端的某个版本是可以运行在任意用户设备,抓取频率与访问方式很难被屏蔽策略捕获,唯一的问题是这一方式获得的数据单条成本较高,但作为备案是合适的。回顾下最初的设计,抓取端和调度分离可独立工作,在这里显出了设计优势。
二、数据清洗
数据清洗分为三个阶段:数据过滤,数据相关性,数据情感标签。还有一个部分涉及到观点汇聚,因为较复杂,不在这里展开。
数据过滤主要针对各类营销文案进行屏蔽,尤其是不少产品或活动,会在设计中鼓励用户自动在“微博”等媒体上留下分享痕迹。这些痕迹不是自然的用户反馈,且数量较大,会干扰舆情分析。转化为算法问题,有一个很大的字符串列表,找到这次字符串中出现频次高于某阈值的子字符串。这个算法时间复杂度明显非一阶,不具备可扩展性,我们的优化方案是抽样聚类后提取出模板,然后用O(N)的方法对全文本进行过滤。另一种过滤相对很简单,过滤掉字数较少的“顶”、“赞”这类的灌水。
数据相关性主要是消除二义数据,例如百度糯米团购,简称糯米团,是百度的一个重要战略产品,但与小吃“糯米团”、以及某明星宝宝的昵称“糯米”,是重合的,需依据上下文进行分类。情感分析部分,主要涉及到反语识别与语境识别,这里举几个例子。“百度地图能靠谱点么?”,这明显是负面的情感,但可能因为产品名(百度地图)和关键字(靠谱)被识别成正面情感。“百度新闻上说,华东地区出现大面积机房故障”,这和百度新闻这个产品是无关的,但可能因关键字(机房故障)被误识别为负面信息。机器学习中的切词、分词、文本分类,原本就是一个独立领域,在这里不展开介绍算法和策略,而主要介绍支撑数据清洗的工程架构。
数据从抓取后以原始数据方式存储,系统自动进行处理,处理的中间数据,会随机抽出百分之一至五的样本数据,供人工抽检。每个数据源针对每个产品形态,均有一个“准召率”阈值。当数据质量高于阈值时,将直接进入下一环节直至最终供用户消费;而当数据质量较低时,触发另一分支,将发起全量数据的人工标注,并以人工标注的数据回馈到机器学习的模型训练中,以提升下一轮数据清洗的质量。业务线仅需设定接受的准确率下限,从数据生成到模型的自行优化训练,是一个自动的过程,从而极大程度降低了维护成本。
三、数据输出
数据经由清洗,进入“反馈数据仓库”。数据仓库是一个逻辑上multi-key-multi-value的存储,主要用来筛选的条件有时间,产品线,数据源,是否相关,有无情感倾向,是否经过清洗。这些条件作为key,任意组合下,能实时地获取反馈内容。仓库中的数据除了来自第三方数据源,也有一部分来自产品内嵌的反馈,产品通过调用API或SDK嵌入该功能后,将在支线流程中与用户交互,主动获取用户的反馈。
之所以在清洗后用数据仓库的形态桥接,是出于以下设计考虑。一方面,我们构建的系统应当停留在基础架构或工具(infrastructure)的角度服务业务,而不应深入为某些业务定制开发,这需要在技术能力构建与业务需求之间清晰地划出一条界限。仓库中的数据充分结构化便于二次加工,且兼顾灵活性,是针对各业务个性化需求的架构选择。另一方面,数据仓库的技术选型有利于充分整合公司现有数据和技术资源。例如为了估算流失损益,希望挖掘负面反馈的用户的流失率,这需要与产品自有的用户行为日志合并,数据仓库是满足此类需求的最为便利的工具。且仓库背后有完善的监控、运维、BI、Ad-Hoc查询等成熟工具体系,便于复用。
仓库基础上,我们建设了实时索引,将标记完成清洗的数据增量发布。下游用户可通过标准API形式访问,指定返回条目、时间窗口、产品线、数据源、情感、标签、关键字等信息,可获得相应反馈。由于对反馈的内容文本进行倒排索引,用户可以方便地以“百度图片”+“色情”的搜索组合,获得用户在一定时间内在微博、贴吧、论坛等各渠道的相关反馈,非常方便。基于这一便利的访问形式,除了我们提供的标准平台外,公司内还出现了不少基于这份数据二次开发的平台,形成了以反馈数据为核心的质量闭环生态。部分应用场景,见下一章节介绍。
【应用场景简述】
第三方舆情系统主要针对三类场景:舆情监控、竞品分析、问题召回。这三类场景是层层递进关系,针对这几类场景分别举例说明。
舆情监控是最容易理解的应用场景,例如今年夏季频发的百度搜索流量劫持,这类问题当影响流量比较较低时很难在服务器端发现。当用户针对该问题的负面反馈显著增高时,我们是能通过第三方反馈数据发现这一问题的。此外,舆情监控常用于了解产品阶段性状态,例如糯米在砸200亿开拓市场时做了几次贴现活动,由于是一次性活动无历史数据比对,舆情反馈是衡量效果的有力手段。
竞品分析是为了辨识产品与市场主线产品的竞争优势劣势,这也是第三方舆情收集的优势;毕竟,内嵌在产品线的反馈数据无法覆盖第三方产品。例如,通过用户负面反馈比例,我们发现和美团、点评相比,百度糯米团购的退款流程存在更高比例的负面问题。这些结论对产品决策非常重要。
最后,继上一章节,我们产出的数据支撑了很多业务线的质量问题闭环。经常会发现用户快速传播一些错误的搜索结果,例如搜索“就不上图了”,会出现大量色情图片结果,这些问题很难在测试与监控环节发现,反馈是应对的有利武器。在这些问题散布之前,我们的系统就能及时捕获,并提供给产品线进行处理。由用户扩散、发现、处理的流程,可以短至小时级别。百度有专职的风控、市场、品牌类部门,每个业务线也有负责运营的产品经理。我们的数据为这些岗位提供了有力的技术保障。
【总结】
测试团队首要关注的是质量。我们听到的大多数实践与分享,集中在协助团队提升研发过程质量与程序质量,对“产品质量提升”这一环节,很多团队未开始介入。采集第三方舆情,提供分析,促成相应迭代,构建质量闭环这条路,是测试团队值得尝试的一个新方向。希望分享能抛砖引玉,引发更多的碰撞与思考。
百度将于近期推出技术类图书《如何高效地开发一款高质量的移动APP》(名称待定),这将是百度首次技术输出,选题聚焦在移动互联网领域,内容覆盖APP开发、部署、测试、分发、变现、监控和数据分析的全过程。帮助移动APP开发者,更好的了解百度的领先技术、项目经验以及自主研发工具等。
作为业界领先的移动应用一站式测试服务平台,百度MTC覆盖移动应用从开发、测试到上线、运营的整个生命周期,为广大开发者在移动应用开发测试过程中面临的成本、技术和效率问题提供解决方案。本次出书稿件将陆续在MTC学院发表(http://mtc.baidu.com/academy/article),同步覆盖其他技术论坛,并将在今年上半年集结成册,正式出版发行,敬请期待吧!
以上是关于第三方舆情收集与质量闭环建设的主要内容,如果未能解决你的问题,请参考以下文章