再聊线程池
Posted 他山之石头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了再聊线程池相关的知识,希望对你有一定的参考价值。
引言
最近恰好在组内分享线程池,又看了看四年前自己写的线程池文章,一是感叹时光荏苒,二是感叹当时的理解太浅薄了,三是感叹自己这么多年依然停留在浅薄的理解当中,没有探究其实现,羞愧难当。遂把分享的内容整理出来,希望能够让读者对线程池有一个全新的认识。
池化
这里池化并不是深度学习中的池化,而是将资源交给池来管理的这一过程。我们在开发中经常回接触到池化资源的技术,最常见的当然是数据库连接池,以及我们今天要讲的线程池,那这种池化资源的特点和好处是什么呢?
特点
- 通常管理昂贵的资源,如连接、线程等
- 资源的创建和销毁交给池,调用者不需要关心
好处
- 资源重复利用,提高响应速度
- 资源可管理,可监控
线程池使用
如何使用不再赘述,请看之前的文章线程池。
线程池分析
类结构
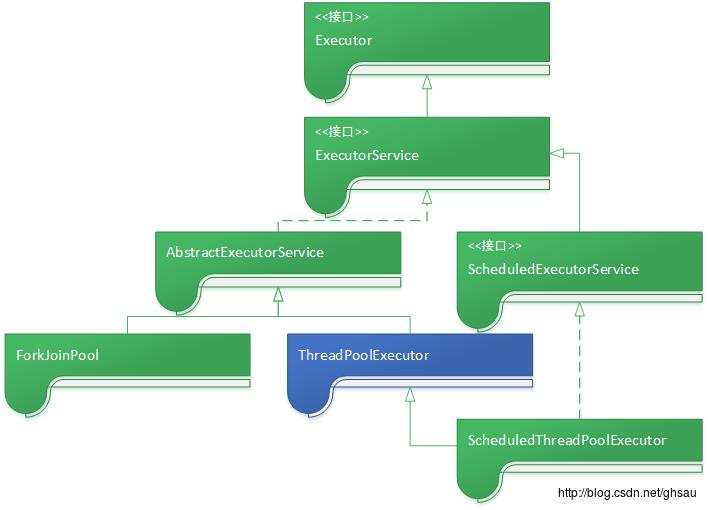
这里面的实现类涉及到三个:
- ForkJoinPool:一个类似于Map/Reduce模型的框架,线程级的,详细可有去看我之前写的文章Fork/Join-Java并行计算框架。
- ThreadPoolExecutor:这是Java线程池的实现,也是本文的主角,Executors提供的几种线程池主要使用该类。
- ScheduledThreadPoolExecutor:继承自ThreadPoolExecutor,添加了调度功能。
ThreadPoolExecutor参数
- int corePoolSize
- 线程池基本大小
- int maximumPoolSize
- 线程池最大大小
- long keepAliveTime
- 保持活动时间
- TimeUnit unit
- 保持活动时间单位
- BlockingQueue workQueue
- 工作队列
- ThreadFactory threadFactory
- 线程工厂
- RejectedExecutionHandler handler
- 驳回回调
这些参数这样描述起来很空洞,下面结合执行任务的流程来看一下。
ThreadPoolExecutor执行任务流程
当我们调用execute方法时,这个流程就开始了,请看下图:
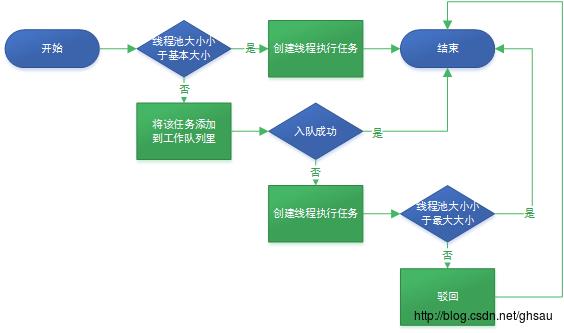
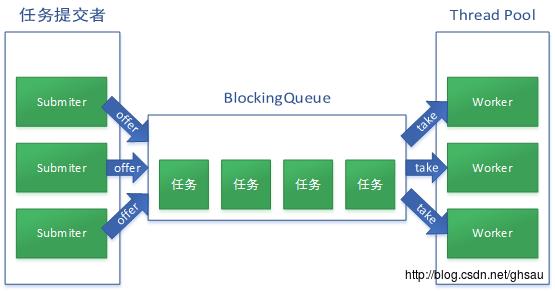
当线程池大小 >= corePoolSize 且 队列未满时,这时线程池使用者与线程池之间构成了一个生产者-消费者模型。线程池使用者生产任务,线程池消费任务,任务存储在BlockingQueue中,注意这里入队使用的是offer,当队列满的时候,直接返回false,而不会等待,有关BlockingQueue可以看我之前写的文章阻塞队列BlockingQueue。
keepAliveTime
当线程处于空闲状态时,线程池需要对它们进行回收,避免浪费资源。但空闲多长时间回收呢,keepAliveTime就是用来设置这个时间的。默认情况下,最终会保留corePoolSize个线程避免回收,即使它们是空闲的,以备不时之需。但我们也可以改变这种行为,通过设置allowCoreThreadTimeOut(true)。
RejectedExecutionHandler
当队列满 且 线程池大小 >= maximumPoolSize时会触发驳回,因为这时线程池已经不能响应新提交的任务,驳回时就会回调这个接口rejectedExecution方法,JDK默认提供了4种驳回策略,代码比较简单,直接上代码分析,具体使用何种策略,应该根据业务场景来选择,线程池的默认策略是AbortPolicy。
ThreadPoolExecutor.AbortPolicy
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 直接抛出运行时异常
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}ThreadPoolExecutor.CallerRunsPolicy
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
// 转成同步调用
r.run();
}
}ThreadPoolExecutor.DiscardPolicy
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 空实现,意味着直接丢弃了
}ThreadPoolExecutor.DiscardOldestPolicy
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
// 取出队首,丢弃
e.getQueue().poll();
// 重新提交
e.execute(r);
}
}Hook methods
ThreadPoolExecutor预留了以下三个方法,我们可以通过继承该类来做一些扩展,比如监控、日志等等。
protected void beforeExecute(Thread t, Runnable r) { }
protected void afterExecute(Thread t, Runnable r) { }
protected void terminated() { }ThreadPoolExecutor状态
线程池的工作流程我们应该大致清楚了,其内部同时维护了一个状态,现在来看一下每种状态对于任务会造成什么影响以及状态之间的流转。
RUNNING
初始状态,接受新任务并且处理已经在队列中的任务。
SHUTDOWN
不接受新任务,但处理队列中的任务。
STOP
不接受新任务,不处理排队的任务,并中断正在进行的任务。
TIDYING
所有任务已终止,workerCount为零,线程转换到状态TIDYING,这时回调terminate()方法。
TERMINATED
终态,terminated()执行完成。

上图是这5种状态间的流转,可以看到它们是单向的、不可逆的。
扩展
- Tomcat线程池
- Dubbo线程池
这两种线程池都是使用ThreadPoolExecutor来实现的,去看它们是如何使用的,有助于我们更好的理解线程池。
总结
现在我们在回过头来去看Executors中提供的几种线程池(fixed、cached、single),如果你能回答出下面几个问题,说明你明白了线程池。
- 为什么newFixedThreadPool中要将corePoolSize和maximumPoolSize设置成一样?
- 为什么newFixedThreadPool中队列使用LinkedBlockingQueue?
- 为什么newFixedThreadPool中keepAliveTime会设置成0?
- 为什么newCachedThreadPool中要将corePoolSize设置成0?
- 为什么newCachedThreadPool中队列使用SynchronousQueue?
- 为什么newSingleThreadExecutor中使用DelegatedExecutorService去包装ThreadPoolExecutor?
可能到这里会有人问,讲了这么多,我应该如何去选择线程池?线程池应该设置多大?没有固定的答案,只有适合的答案,下面说一下我的理解:
- 关于线程池大小问题,可以参考这个公式,仅仅是参考而已。
启动线程数 = [ 任务执行时间 / ( 任务执行时间 - IO等待时间 ) ] x CPU内核数
- 在控制线程池大小的基础上,尽量使用有界队列并且设置大小,避免OOM。
- 设置合理的驳回策略,适用于你的业务。
版权声明
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者高爽和本文原始地址:http://blog.csdn.net/ghsau/article/details/53538303。
以上是关于再聊线程池的主要内容,如果未能解决你的问题,请参考以下文章
newCacheThreadPool()newFixedThreadPool()newScheduledThreadPool()newSingleThreadExecutor()自定义线程池(代码片段