深入剖析神经网络的运行机理及实现
Posted 火贪三刀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入剖析神经网络的运行机理及实现相关的知识,希望对你有一定的参考价值。
随着大数据和机器硬件水平的提升,神经网络特别是深度神经网络现在是大火特火。因为目前的深度学习模型都是基于神经网络进行的改进和加深,所以要想对深度学习有一些较深入的研究,先熟悉和了解人工神经网络是非常有帮助的。
本文基于神经网络实现一个手写体数字识别模型,此处使用的数据集为sklearn自带的digit数据,只要装了sklearn就可以直接获得。
1、手写体人工神经网络模型
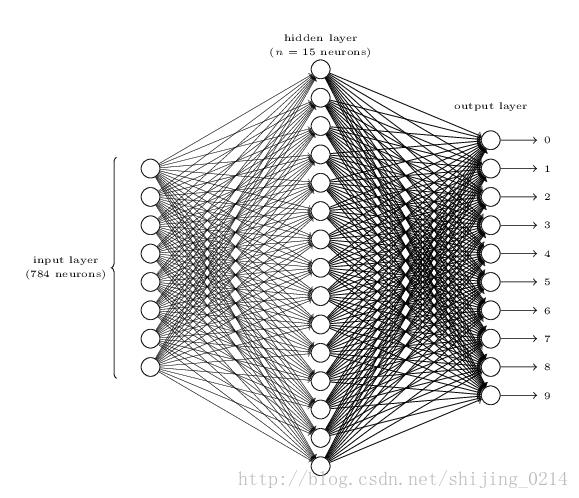
图(一),mnist手写体数字识别网络结构,见【参考一】
神经网络是一个判别模型,它会利用训练集学到一个从输入到输出的映射关系,结构上可以分为输入层、隐藏层和输出层,如上图。输入层用于接收数据的输入,通过隐藏层的处理,最后经输出层转换得到输出。
上图为基于mnist数据集画的一个神经网络模型,因为mnist一张图片为28*28=784,故输入层有784个神经元。而digit的图片为8*8=64,故digit数据集的输入层有64个神经元,也就是说我们将要实现的神经网络输入层有64个神经元,要简单很多。
神经网络的性能如何,隐层的设计非常关键,隐藏层是设计用来自动学习特征的,通过这些学到的特征来进行最后一层的分类任务,那它会学到什么东西呢?在手写体数字识别中,大概会学到这样的特征:
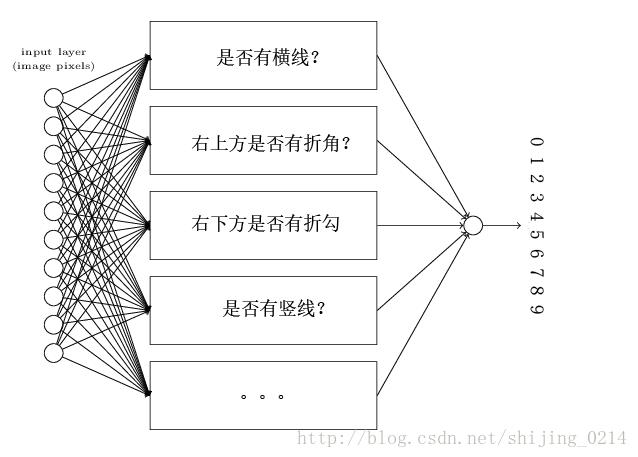
图(二)
再具体一点就是,该图中的隐层我们共设置了15个神经元,每一个神经元存储的都是学来的特征,假设前四个神经元是用来考察手写数字是否满足以下这四个特征,


图(三)
有了隐层学到的这些东西,那么对它进行组合判断就很容易得到输出了,例如发现上面的四个特征均被激活,则如我们所知,其有很大的概率表示数字0。
2、运行机理及实现
在有监督学习中,模型会分为训练阶段和预测阶段,在训练阶段将模型中的待定参数学习出来,然后用在预测阶段,就好像我们初中求解带参方程
ax+b=y
一样,首先通过已知条件把方程中的参数给求解出来,然后再利用求出来的参数计算给定
x
下的
在神经网络的训练阶段,主要包括以下几步:
(1)加载训练集;
(2)前向传导,将信息传递给输出层;
(3)利用标注信息和代价函数来计算代价;
(4)通过反向传播代价函数梯度来更新每一层中的参数
其简单实现的整体代码如下:
#coding=utf-8
'''
Created on Jul 20, 2016
'''
import numpy as np
import random
from sklearn import datasets
class Network(object):
def __init__(self,sizes):
'''
parameters:
sizes中保存了神经网络各层神经元个数
functions:
对神经网络层与层之间的连接参数进行初始化
'''
#权重矩阵
self.weights = [np.random.randn(y,x) for x,y in zip(sizes[:-1],sizes[1:])]
#偏置矩阵
self.biases = [np.random.randn(x) for x in sizes[1:]]
def init_parameters(self,parameters):
'''
functions:初始化模型参数
parameters主要包括:
epochs:迭代次数
mini_batch_size:批处理大小
eta:学习率
nnLayers_size:神经网络层数
'''
self.epochs = parameters.get("epochs")
self.mini_batch_size = parameters.get("mini_batch_size")
self.eta = parameters.get("eta")
self.nnLayers_size = parameters.get("nnLayers_size")
def load_data(self):
'''
functions:加载数据集,这里使用的是sklearn自带的digit手写体数据集
'''
digits = datasets.load_digits()
return digits.data, digits.target
def feed_forword(self,data):
'''
parameters:
data:输入的图片表示数据,是一个一维向量
functions:前向传导,将输入传递给输出,y = w*x + b
return:传递到输出层的结果
'''
for w, b in zip(self.weights, self.biases):
z = np.dot(w,data) + b
data = self.sigmoid(z)
return data
def sigmoid(self,z):
'''
functions:sigmoid函数
'''
return 1.0/(1.0+np.exp(-z))
def crossEntrop(self,a, y):
'''
parameters:
a:预测值
y:真实值
functions:交叉熵代价函数f=sigma(y*log(1/a))
'''
return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
def delta_crossEntrop(self,z,a,y):
'''
parameters:
z:激活函数变量
a:预测值
y:真实值
'''
return self.sigmoid(z) - y
def SGD(self,data):
'''
function:随即梯度下降算法来对参数进行更新
parameters:
data:数据集
'''
#数据集大小
data_len = len(list(data))
for _ in range(self.epochs):
#将数据集按照指定大小划分成小的batch进行梯度训练,mini_batchs中的每个元素相当于一个小的样本集
mini_batchs = [data[k:k+self.mini_batch_size] for k in range(0,data_len,self.mini_batch_size)]
for mini_batch in mini_batchs:
#batch中的每个样本都会被用来更新参数
self.update_parameter_by_mini_batch(mini_batch)
def update_parameter_by_mini_batch(self,mini_batch):
'''
functions:按照梯度下降法批量对参数更新
'''
#首先初始化每个参数的偏导数
nabla_w = [np.zeros(w.shape) for w in self.weights]
nabla_b = [np.zeros(b.shape) for b in self.biases]
#将每个样本计算得到的参数偏导数进行累加
for mini_x, mini_y in mini_batch:
#每个样本通过后向传播得到两个导数张量,表示对w,b的导数
delta_nabla_w,delta_nabla_b = self.derivative_by_backpropagate(mini_x, mini_y)
nabla_w = [nw+dnw for nw,dnw in zip(nabla_w,delta_nabla_w)]
nabla_b = [nb+dnb for nb,dnb in zip(nabla_b,delta_nabla_b)]
self.weights = [w - self.eta * nw for w,nw in zip(self.weights,nabla_w)]
self.biases = [b - self.eta * nb for b,nb in zip(self.biases,nabla_b)]
def derivative_by_backpropagate(self,x,y):
'''
functions:通过后向传播算法来计算每个参数的梯度值
'''
#首先初始化每个参数的偏导数
nabla_w = [np.zeros(w.shape) for w in self.weights]
nabla_b = [np.zeros(b.shape) for b in self.biases]
#激活值列表,元素为经过神经元后的激活输出,也即下一层的输入,此处记录下来用于计算梯度
activations = [x]
#线性组合值列表,元素为未经过神经元前的线性组合,z=w*x+b
zs = []
#初始输入
activation = x
#首先通过循环得到求导所需要的中间值
for w, b in zip(self.weights,self.biases):
z = np.dot(w,activation) + b
zs.append(z)
activation = self.sigmoid(z)
activations.append(activation)
#倒数第一层的导数计算,有交叉熵求导得来
delta = self.delta_crossEntrop(zs[-1],activations[-1], y)
nabla_w[-1] = np.dot(delta.reshape(len(delta),1), activations[-2].reshape(1,len(activations[-2])))
nabla_b[-1] = delta
#倒数第二层至正数第一层间的导数计算,有sigmoid函数求导得来
for i in range(2,self.nnLayers_size):
z = zs[-i]
delta = np.dot(self.weights[-i+1].transpose(),delta.reshape(len(delta),1))
delta_z = self.derivative_sigmoid(z)
delta = np.multiply(delta, delta_z.reshape(len(delta_z),1))
nabla_w[-i] = np.dot(np.transpose(delta),activations[-i].reshape(len(activations[-i]),1))
delta = delta.reshape(len(delta))
nabla_b[-i] = delta
return (nabla_w,nabla_b)
def derivative_sigmoid(self,z):
'''
functions:对sigmoid求导的结果
'''
return self.sigmoid(z) *(1-self.sigmoid(z))
def evaluation(self,data):
'''
functions:性能评估函数
'''
result=[]
right = 0
for (x,y) in data:
output = self.feed_forword(x)
result.append((np.argmax(output),np.argmax(y)))
for i,j in result:
if(i == j):
right += 1
print("test data's size:",len(data))
print("count of right prediction",right)
print("the accuracy:",right/len(result))
return right/len(result)
def suffle(self,data):
'''
parameters:
data:元组数据
functions:对数据进行打乱重组
'''
new_data = list(data)
random.shuffle(new_data)
return np.array(new_data)
def transLabelToList(self,data_y):
'''
functions:将digit数据集中的标签转换成一个10维的列表,方便做交叉熵求导的计算
'''
data = []
for y in data_y:
item = [0,0,0,0,0,0,0,0,0,0]
item[y] = 1
data.append(item)
return data
if __name__=="__main__":
#神经网络的层数及各层神经元
nnLayers = [64,15,10]
nn=Network(nnLayers)
parameters = {"epochs":50,"mini_batch_size":10,"eta":0.01,"nnLayers_size":len(nnLayers)}
nn.init_parameters(parameters)
#加载数据集
data_x,data_y=nn.load_data()
#将标签转换成一个10维列表表示,如1表示成[0,1,0,0,0,0,0,0,0,0]
data_y = nn.transLabelToList(data_y)
#将数据打包成元组形式
data = zip(data_x,data_y)
#将有序数据打乱
data = nn.suffle(data)
#将数据集划分为训练集和测试集
train_data = data[:1500]
test_data = data[1500:]
nn.SGD(train_data)
print(nn.evaluation(test_data))
接下来,我们会按照神经网络的实现过程来对神经网络进行分析。
第一步,初始化一个神经网络模型
#nnLayers表示神经网络有三层结构,每层的神经元个数分别为64,15,10
nnLayers = [64,15,10]
nn=Network(nnLayers)
#参数词典
parameters = {"epochs":50,"mini_batch_size":10,"eta":0.01,"nnLayers_size":len(nnLayers)}
#初始化参数函数
nn.init_parameters(parameters)def init_parameters(self,parameters):
'''
functions:初始化模型参数
parameters主要包括:
epochs:迭代次数
mini_batch_size:批处理大小
eta:学习率
nnLayers_size:神经网络层数
'''
self.epochs = parameters.get("epochs")
self.mini_batch_size = parameters.get("mini_batch_size")
self.eta = parameters.get("eta")
self.nnLayers_size = parameters.get("nnLayers_size")我们还要对神经网络中所有的边的权值进行初始化,如下:
def __init__(self,sizes):
'''
parameters:
sizes中保存了神经网络各层神经元个数
functions:
对神经网络层与层之间的连接参数进行初始化
'''
#权重矩阵
self.weights = [np.random.randn(y,x) for x,y in zip(sizes[:-1],sizes[1:])]
#偏置矩阵
self.biases = [np.random.randn(x) for x in sizes[1:]]第二步,加载数据集
要想训练一个模型,数据集是肯定少不了的。手写体数字识别最出名的数据集当属Lecun提供的mnist数据集,但其数据集不能直接拿来用,且我们只是打算训练一个最简单的三层神经网络,所以使用sklearn自带的digit数据集就非常合适。
加载数据集函数如下:
#加载数据集
data_x,data_y=nn.load_data()
#将标签转换成一个10维列表表示,如1表示成[0,1,0,0,0,0,0,0,0,0]
data_y = nn.transLabelToList(data_y)
#将数据打包成元组形式
data = zip(data_x,data_y)
#将有序数据打乱
data = nn.suffle(data)
#将数据集划分为训练集和测试集
train_data = data[:1500]
test_data = data[1500:] def load_data(self):
'''
functions:加载数据集,这里使用的是sklearn自带的digit手写体数据集
'''
digits = datasets.load_digits()
return digits.data, digits.target该函数返回两个list,分别保存每张手写体的数字化表示和对应的标签。
def transLabelToList(self,data_y):
'''
functions:将digit数据集中的标签转换成一个10维的列表,方便做交叉熵求导的计算
'''
data = []
for y in data_y:
item = [0,0,0,0,0,0,0,0,0,0]
item[y] = 1
data.append(item)
return data该函数把原数据集中的标签进行了改写,以方便后续使用。
def suffle(self,data):
'''
parameters:
data:元组数据
functions:对数据进行打乱重组
'''
new_data = list(data)
random.shuffle(new_data)
return np.array(new_data)因为直接加载后的数据集是按照0-9顺序存放的,我们要通过suffle函数将数据集打乱,并划分为训练集和测试集。
第三步,训练模型参数
这一步是模型的关键,我们需要通过训练集把模型中的参数训练出来,因为里面夹杂了很多矩阵运算和求导运算,为方便说明,这里给出一个简单的三层神经网络,并将里面的参数和变量标注出来,该图如下:
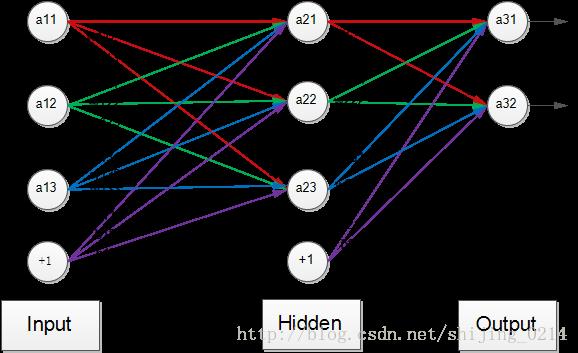
图(四)
训练直接从调用SGD函数开始,
nn.SGD(train_data) def SGD(self,data):
'''
function:随即梯度下降算法来对参数进行更新
parameters:
data:数据集
'''
#数据集大小
data_len = len(list(data))
for _ in range(self.epochs):
#将数据集按照指定大小划分成小的batch进行梯度训练,mini_batchs中的每个元素相当于一个小的样本集
mini_batchs = [data[k:k+self.mini_batch_size] for k in range(0,data_len,self.mini_batch_size)]
for mini_batch in mini_batchs:
#batch中的每个样本都会被用来更新参数
self.update_parameter_by_mini_batch(mini_batch)
为了加快训练速度,在神经网络中并不是一次将全部数据都拿来训练,而是通过批处理进行逐步更新参数的。所以在SGD函数中,首先将训练数据集划分成小块数据送update_parameter_by_mini_batch函数进行参数更新操作。
def update_parameter_by_mini_batch(self,mini_batch):
'''
functions:按照梯度下降法批量对参数更新
'''
#首先初始化每个参数的偏导数
nabla_w = [np.zeros(w.shape) for w in self.weights]
nabla_b = [np.zeros(b.shape) for b in self.biases]
#将每个样本计算得到的参数偏导数进行累加
for mini_x, mini_y in mini_batch:
#每个样本通过后向传播得到两个导数张量,表示对w,b的导数
delta_nabla_w,delta_nabla_b = self.derivative_by_backpropagate(mini_x, mini_y)
nabla_w = [nw+dnw for nw,dnw in zip(nabla_w,delta_nabla_w)]
nabla_b = [nb+dnb for nb,dnb in zip(nabla_b,delta_nabla_b)]
#梯度下降法更新参数
self.weights = [w - self.eta * nw for w,nw in zip(self.weights,nabla_w)]
self.biases = [b - self.eta * nb for b,nb in zip(self.biases,nabla_b)]在该函数中,我们会通过反向传播代价来更新参数,在mini_batch中,我们会把batch中每对样本对各参数的偏导数进行累加作为梯度下降法中的梯度,它不需要每个样本过来都要使用梯度下降法计算一次,这也是使用mini_batch速度能够加快速度的原因。
在上面的函数中,用到了derivative_by_backpropagate来进行反向传播,这个函数是整个模型的关键。
def derivative_by_backpropagate(self,x,y):
'''
functions:通过后向传播算法来计算每个参数的梯度值
'''
#首先初始化每个参数的偏导数
nabla_w = [np.zeros(w.shape) for w in self.weights]
nabla_b = [np.zeros(b.shape) for b in self.biases]
#激活值列表,元素为经过神经元后的激活输出,也即下一层的输入,此处记录下来用于计算梯度
activations = [x]
#线性组合值列表,元素为未经过神经元前的线性组合,z=w*x+b
zs = []
#初始输入
activation = x
#首先通过循环得到求导所需要的中间值
for w, b in zip(self.weights,self.biases):
z = np.dot(w,activation) + b
zs.append(z)
activation = self.sigmoid(z)
activations.append(activation)
#倒数第一层的导数计算,有交叉熵求导得来
delta = self.delta_crossEntrop(activations[-1], y)
nabla_w[-1] = np.dot(delta.reshape(len(delta),1), activations[-2].reshape(1,len(activations[-2])))
nabla_b[-1] = delta
#倒数第二层至正数第一层间的导数计算,有sigmoid函数求导得来
for i in range(2,self.nnLayers_size):
z = zs[-i]
delta = np.dot(self.weights[-i+1].transpose(),delta.reshape(len(delta),1))
delta_z = self.derivative_sigmoid(z)
delta = np.multiply(delta, delta_z.reshape(len(delta_z),1))
nabla_w[-i] = np.dot(np.transpose(delta),activations[-i].reshape(len(activations[-i]),1))
delta = delta.reshape(len(delta))
nabla_b[-i] = delta
return (nabla_w,nabla_b)
def test():
#nothing在该函数中,我们定义两个列表分别来存储前向传导过程中计算的中间变量,它在后向传播计算偏导的时候会被用到,其中,zs列表保存的是图(四)神经元左侧的变量z, zt+1=wt∗at+bt ,activations列表保存的是图(四)神经元右侧的变量a, at=sigmoid(zt)
前向传导到输出层,这里我们用交叉熵来作为模型的代价函数,交叉熵求导过程如下(见【参考二】):
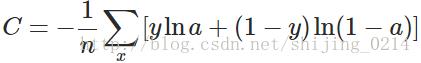
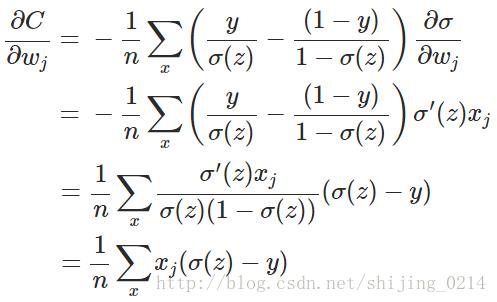
其中倒数第二行的变换用到了:
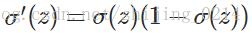
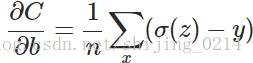
因为我们在mini_batch中是一个样本一个样本进行反向传播计算的,所以上面公式中的求和求平均都可以去掉,且对w和b的求导项中均包括 (σ(z)−y) ,我们可以定义交叉熵的求导函数为:
def delta_crossEntrop(self,z,a,y):
'''
parameters:
z:激活函数变量
a:预测值
y:真实值
'''
return self.sigmoid(z) - y对最后一层的参数求导与其他层的参数求导过程不一样,因此要分两步来计算,但均属于求导的链式法则,如 at+1 对 wt 求导,则先会对 zt+1 求导,再乘以 zt+1 对 wt 的求导。对每个样本通过反向传播计算完偏导后返回给mini_batch,最后统一通过梯度下降法来对参数进行一次更新,然后进入下一次mini_batch的计算。
第四步,测试模型的分类能力
这里使用前面划分的测试集对已经训练好的神经网络进行测试,
def evaluation(self,data):
'''
functions:性能评估函数
'''
result=[]
right = 0
for (x,y) in data:
output = self.feed_forword(x)
result.append((np.argmax(output),np.argmax(y)))
for i,j in result:
if(i == j):
right += 1
print("test data's size:",len(data))
print("count of right prediction",right)
print("the accuracy:",right/len(result))
return right/len(result) def feed_forword(self,data):
'''
parameters:
data:输入的图片表示数据,是一个一维向量
functions:前向传导,将输入传递给输出,y = w*x + b
return:传递到输出层的结果
'''
for w, b in zip(self.weights, self.biases):
z = np.dot(w,data) + b
data = self.sigmoid(z)
return data训练好模型后,参数w,b就可以拿来使用了,通过前向传导得到输出,然后计算预测准确率,使用以上代码跑的一个结果如下:
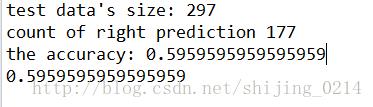
3、参考
以上是关于深入剖析神经网络的运行机理及实现的主要内容,如果未能解决你的问题,请参考以下文章
精华推荐 | 深入浅出 RocketMQ原理及实战「底层源码挖掘系列」透彻剖析贯穿RocketMQ的消费者端的运行核心的流程(上篇)