从浏览器输入一个地址到渲染出网页这个过程发生了什么???
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从浏览器输入一个地址到渲染出网页这个过程发生了什么???相关的知识,希望对你有一定的参考价值。
1. 了解URL:

其中:登录信息 查询字符串 服务器端口号 文件路径 片段标识符可选, 如果没有的就是默认配置。
2.DNS解析服务
计算机需要将域名理解为IP地址, 这个时候就需要DNS解析服务来提供帮助,主要遵循如下查找过程:
浏览器缓存-浏览器会保存DNS记录,每个
系统缓存-如果再浏览器缓存里面没有找到记录,则在系统缓存中获取。
路由器缓存
DNS服务器 递归搜索
3. 建立TCP连接
由DNS服务解析的IP地址之后,通过IP地址建立TCP连接,这里会有一个TCP三次握手的过程:
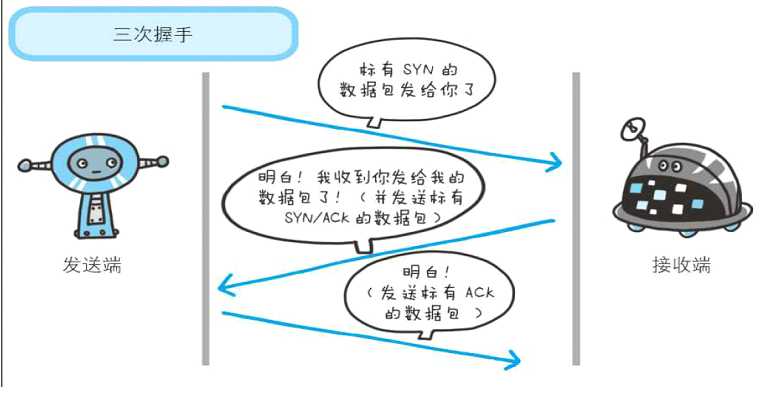
4. 生成HTTP报文
建立连接时,会生成HTTP报文, HTTP报文结构如下:
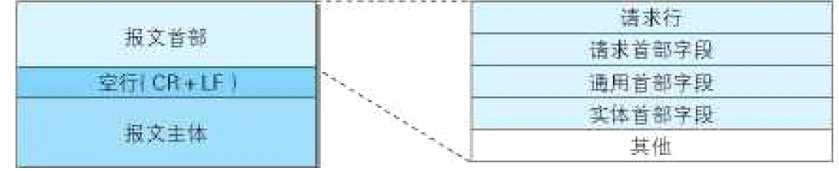
下面分别解释一下各个组成部分:
请求行:由 请求方法 请求URI 和 请求HTTP版本构成 形如:
PUT example.html HTTP1.1
请求方法包括: GET 获取资源, POST传输实体主体,PUT 传输文件等等
URI和HTTP版本没什么好说的
请求首部字段:(传递额外信息用,以下列举一些首部字段)
Accept:用于通知服务器,用户代理能够处理的媒体类型及媒体类型的相对优先级,
形如:Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 意思就是, 优先返回 text/html,application/xhtml+xml,application/xml 类型的文件q 表示权重,默认且最大值为1。
Accept-Charset :用来通知服务器用户代理支持的字符集及字符集的相对优先顺序。
Accept-Encoding :首部字段用来告知服务器用户代理支持的内容编码及内容编码的优先级顺序。
通用首部字段和实体首部字段都有各自的定义, 这里不再展开。
生成报文时,其中有一个概念是cookie:
HTTP是无状态协议,不对之前的请求和响应状态进行管理,也就是说,HTTP不保存个人登陆信息,那么这里就需要cookie来协助http协议来解决。
Cookie整个工作过程如下:
第一次http请求:
服务端会在响应中添加cookies来提示客户端保存cookie:Server: Apache <Set-Cookie: sid=1342077140226724; path=/; expires=10-Oct-12 07:12:20 GMT>
第二次http请求:
客户端在第二次请求时就会在报文中加入cookie:
Cookie: sid=1342077140226724
5.生成HTTP报文之后经过如下的过程:
一个HTTP报文经过各个层级的处理最后才被传输给服务端,下面描述一下各个层级的工作:
传输层:这里会加上TCP首部,主要包含端口号, 以及TCP的各种信息。同时, 他会将HTTP的报文请求分为多个报文段。
网络层:待发送的数据送到网络层,网络层再进行封装,这里面包含源目的地的ip地址。
链路层:将mac地址、链路层信息加到数据包里,形成以太网首部,在链路协议下完成节点间的数据传输。
6.服务器接收到HTTP请求
服务器接收到数据之后,会经过链路层,网络层,传输层逐层将该层对应的首部信息去掉,整个过程如下图所示:
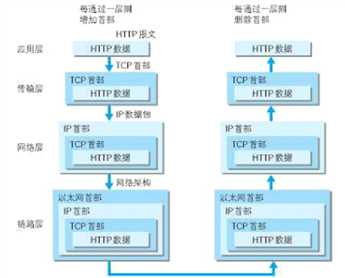
7. 服务器根据收到的HTTP数据,生成对应的响应报文,结构如下:
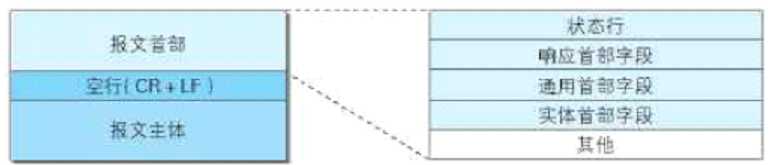
下面逐一介绍:
状态行:由HTTP 版本 状态码 原因短语构成
响应首部字段 通用首部字段 实体首部字段 都可以查手册得知其具体内容以及含义这里不再展开
8. 客户端接收到了响应报文之后,我们以一个html文件来讲述浏览器是如何渲染文档的
先介绍一些背景知识:
浏览器通常的主要组件分为以下几部分:
1.用户界面:如地址栏 书签菜单等等
2.浏览器引擎:在用户界面和呈现引擎之间传送之类
3.呈现引擎:负责显示请求的内容。例如HTMLhe CSS
4.javascript解释器:用于解释和执行JavaScript 代码
5.数据存储
渲染文档主要使用呈现引擎。
过程如下:
1.呈现引擎从网络层获取请求文档的内容HTML文件,内容大小一般在8000个块以内。
2.引擎解析HTML文档 将各个标记转化为内容树上的DOM 节点 ,同时解析CSS文件 样式数据
3.样式信息和 内容树共同构建成为 呈现树
4.呈现树构建完毕以后,进入布局阶段, 为每一个节点分配一个应该出现在屏幕上的确切坐标
5.呈现引擎遍历呈现树 由用户界面后端层将每个节点绘制出来。
以上是关于从浏览器输入一个地址到渲染出网页这个过程发生了什么???的主要内容,如果未能解决你的问题,请参考以下文章