浏览器从输入URL后到出现页面,这个过程发生了啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器从输入URL后到出现页面,这个过程发生了啥?相关的知识,希望对你有一定的参考价值。
参考技术A 互联网发达的时代,当我们遇到什么问题时,总会习惯性的去网络上查找答案。本人也是一样,开发时遇到问题就会习惯性的打开"度娘"寻找我们的答案。哪有没有朋友像我们一样,也会好奇当前我们在浏览器输入网址之后,浏览器做了些什么呢?
URL 解析、缓存查询,DNS 解析、TCP 连接、处理请求、接受响应、渲染页面
首先判断你输入的是一个合法的 URL 还是一个待搜索的关键词,并且根据你输入的内容进行自动完成字符编码等操作。
DNS解析,把域名转化成IP地址后,服务器会对连接请求做出响应,表示同意建立连接。
服务器开始构建响应,创建一条http响应报文,把资源信息放到响应体里面开始返回
http请求响应,都有一个状态码返回,用来标记这次返回的状态。一般有以下几种状态码:200、302、404、500、504。浏览器会根据状态码,做出相应的动作,遇到200会接受正常返回信息,开始渲染页面。遇到302,则会根据http响应头的location字段,再次发起一次地址是location的网络请求,遇到4开头和5开头的错误,则不会正常渲染,会提示相应的错误。
三次握手(Three-way Handshake)其实就是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。实质上其实就是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号,交换TCP窗口大小信息。
刚开始客户端处于 Closed 的状态,服务端处于 Listen 状态。
建立一个连接需要三次握手,而终止一个连接要经过四次挥手(也有将四次挥手叫做四次握手的)。这由TCP的半关闭(half-close)造成的。所谓的半关闭,其实就是TCP提供了连接的一端在结束它的发送后还能接收来自另一端数据的能力。
TCP 的连接的拆除需要发送四个包,因此称为四次挥手(Four-way handshake),客户端或服务器均可主动发起挥手动作。
刚开始双方都处于 ESTABLISHED(建立) 状态
参考: https://zhuanlan.zhihu.com/p/86426969
参考: https://www.jianshu.com/p/546b2a175f89
从输入 URL 到页面加载显示完成的过程
前言:“一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?” 这个问题我想大多数人都不会陌生,好像是前端面试题经常会出现的,在此我也好好梳理梳理了一番,总结成这篇文章,希望能对和我一样在前端道路上奋进的小白们有所帮助,一起学习,交流。
我把这个问题拆解成两个过程:
1. 用户输入 url ---> 客户端(浏览器)拿到服务端的数据
2. 浏览器拿到数据 ---> 呈现页面(也就是浏览器工作过程)
搞清楚这两个过程后,我们也算是完整的回答了前言部分所提的问题了。
一. 输入网址到浏览器获得资源的过程
举个例子:
1. 输入网址: http://www.cnblogs.com/dinghuihua/p/6674719.html

把url分成协议、网络地址、资源路径三部分
- 协议:从该计算机获取资源的方式,有HTTP、HTTPS、FTP等,不同协议有不同的通讯内容格式
- 网络地址:指连接网络上的哪一台计算机,可以是域名、IP地址,可以包括端口号。如:“www.cnblogs.com”、“192.168.0.91:8080”
- 资源路径:指从服务器上获取哪一项资源。如 “/dinghuihua/p/6674719.html”
2. 通过DNS解析获得网址的对应IP地址
当发送一个url请求时,不管这个url是web页面的url还是web页面上的每个资源的url,浏览器都会开启一个线程处理该请求,同时在远程DNS服务器上启动一个DNS查询,这能使浏览器获得请求对应的IP地址
PS: 脑补为啥有DNS这玩意...因为要人类记住辣么多计算机能记住的IP地址怎么可能嘛...它就是起到域名解析的作用的
dns是将域名和IP进行绑定的,通过域名找到互联网上实际的物理地址的服务器,找到这个服务器后,服务器会把请求解析,找到该文件(上下文)后将其推送给浏览器, 浏览器就会把这个html文件通过它自己的浏览器内核定义好的规范解析渲染出来(渲染:呈现元素)
这一步包括DNS的具体查找过程
- 浏览器缓存 – 浏览器会缓存DNS记录一段时间。 有趣的是,操作系统没有告诉浏览器储存DNS记录的时间,这样不同浏览器会储存个自固定的一个时间(2分钟到30分钟不等)。
- 系统缓存 – 如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调用(windows里是gethostbyname)。这样便可获得系统缓存中的记录。
- 路由器缓存 – 接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。
- ISP DNS 缓存 – 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。
- 递归搜索 – 你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会有.com域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。
3. 浏览器与远程web服务器 通过TCP三次握手协商来建立一个 TCP/IP 连接
该握手包括一个“同步报文”,一个“同步-应答报文”和一个“应答报文”,这三个报文在 浏览器和服务器之间传递。该握手首先由客户端尝试建立起通信,而后服务器应答并接受客户端的请求,最后由客户端发出该请求已经被接受的报文。
4. 浏览器 通过TCP/IP连接 向web服务器 发送一个 HTTP 请求
5. 服务器的永久重定向响应(从 http://example.com 到 http://www.example.com)
6. 浏览器跟踪重定向地址
7. 服务器处理请求
8. 服务器返回一个 HTTP 响应
远程服务器找到要请求的资源并使用 HTTP 响应返回该资源,值为 200 的 HTTP 响应状态表示一个正确的响应。
9. 到这里便是浏览器的工作过程了。。。
浏览器显示 HTML
浏览器发送请求获取嵌入在 HTML 中的资源(如图片、音频、视频、CSS、JS等等)
浏览器发送异步请求
二. 浏览器获得资源后到呈现页面的过程
常用的浏览器有很多,有IE、Firefox、Safari、Chrome以及Opera,还有很多国产浏览器,像360浏览器啊这些,它们的存在共同点都是为了让用户看到各种各样的网站,它们不同的是内核的不同,因此可能会给前端工程师们带来一些浏览器的差异性兼容性问题。
* 浏览器主要的功能:通过向服务器请求,来获取你所想要的网络资源,并将它渲染到浏览器窗口中。而资源类型通常是html文件,但也可能是PDF,图片或者是其他类型的资源。
* 浏览器的内核(渲染引擎)有:
user agent : 代表浏览器内核,不特指哪个浏览器
| 浏览器内核 | 厂商前缀 | 代表浏览器 | 内核背景 |
| Trident | -ms- | IE浏览器系列 | 该内核程序在1997年的IE4中首次被采用,是微软在Mosaic代码的基础之上修改而来的,并沿用到IE11,也被普遍称作”IE内核”。Trident实际上是一款开放的内核,其接口内核设计的相当成熟,因此才有许多采用IE内核而非IE的浏览器(壳浏览器)涌现。 |
| Gecko | -moz- | Firefox | Netscape6开始采用的内核,后来的Mozilla FireFox(火狐浏览器)也采用了该内核,Gecko的特点是代码完全公开 |
| Webkit | -webkit- | Safari | Safari内核,Chrome内核原型,开源,包含了来自KDE项目和苹果公司的一些组件,主要用于Mac OS系统,它的特点在于源码解构清晰、渲染速度极快,缺点是网页代码的兼容性不高,导致一些编写不标准的网页无法正常显示 |
| Blink | -webkit- | Chrome、opera等除IE、Firefox、Safari之外的几乎所有浏览器(几乎所有国产双内核浏览器(Trident/Blink)如360、猎豹、qq、百度等) | Blink是一个由Google和Opera Software开发的浏览器排版引擎,是基于Webkit内核的子项目 |
| Presto | -o- | Opera前内核[现已废弃] | Opera12.17及更早版本曾经采用的内核,现已停止开发并废弃 |
其实浏览器拿到资源数据后,便开始浏览器渲染引擎的基本渲染流程

渲染引擎开始解析HTML文档,并把标签转化成内容树中的DOM节点。同时它也开始解析样式数据,外链的css文件以及style标签内的样式。所有这些样式数据以及HTML中的可见性指令都是用来创建另一棵树--render 树。
现在页面就呈现在我们面前了。。。
我看到有其他关于这个问题的解释,也挺完善的,截个图补充补充。。。


扩展:因为有这么个过程,所以我们就可以在不同时期干不同事情。页面加载完成有两种事件:

执行顺序
- ready,表示文档结构(DOM结构)已经加载完成(不包含图片等非文字媒体文件),
- onload,指示页面包含图片等文件在内的所有元素都加载完成
$(function(){ // do something }); // 其实这个就是jQuery ready()的简写,他等价于: $(document).ready(function(){ //do something }) // 或者如下的写法,因为jQuery 的默认参数是:“document”; $().ready(function(){ //do something })
多函数加载的问题
因为js没有重载,所以后面的函数会覆盖前面的同名函数
<body onload="a();b()"> </body>
(1). body中声明的onload事件(DOM0级别)会被后面的window.onlad()(DOM0级别)覆盖
<body onload="a();b()"> </body> <script> window.onload = function(){
alert(\'world\');
} </script>
结果只弹出“world”
(2). 可以在body的onload中实现多函数执行
<body onload="a();b()"> </body> <srcipt> function a(){alert(\'a\');} function b(){alert(\'b\');} </script>
结果分别弹出“a”和“b”
(3). 多个window.onload()会产生覆盖
window.onload = function(){alert(\'hello\');} window.onload = function(){alert(\'world\');}
结果只会弹出“world”
(4). 用jQuery的话,可以用多个load函数实现,它们会按顺序依次执行
$(window).load(function() { alert("hello"); }); $(window).load(function() { alert("world"); });
相关知识补充:
1. http状态码有哪些?
- 1xx 【消息】服务器收到请求,需要请求者继续执行操作
- 2xx 【成功】请求已成功被服务器接收、理解、并接受。
- 3xx 【重定向】客户端需要采取进一步的操作以完成请求
- 4xx 【客户端请求错误】客户端错误,请求包含语法错误或无法完成请求
- 5xx 【服务器错误】服务器在处理请求的过程中发生了错误
常见的有:
- 200 OK //客户端请求成功
- 304 Not Modified // 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源
- 400 Bad Request //客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized // 当前请求要求用户的身份认证
- 403 Forbidden // 服务器理解请求客户端的请求,但是拒绝执行此请求
- 404 Not Found //请求资源不存在,输入了错误的URL
- 500 Internal Server Error //服务器发生不可预期的错误
- 503 Server Unavailable // 由于超载或系统维护,服务器暂时的无法处理客户端的请求。一段时间后可能恢复正常
更多可见:http://www.webmasterhome.cn/httpstatus/
2. TCP三次握手:

3. TCP/IP协议族
- 这个协议族是规定我们浏览器和服务器之间的通信规则的。
- 网络的分层:
(1).应用层 应用层指的是浏览器和服务器
协议:HTTP协议
(2).传输层 将发送的数据拆包
协议:TCP协议、 UPD协议
(3).网络层 负责发送文件
协议:IP协议
(4).数据链路层 网路中接口,硬件层
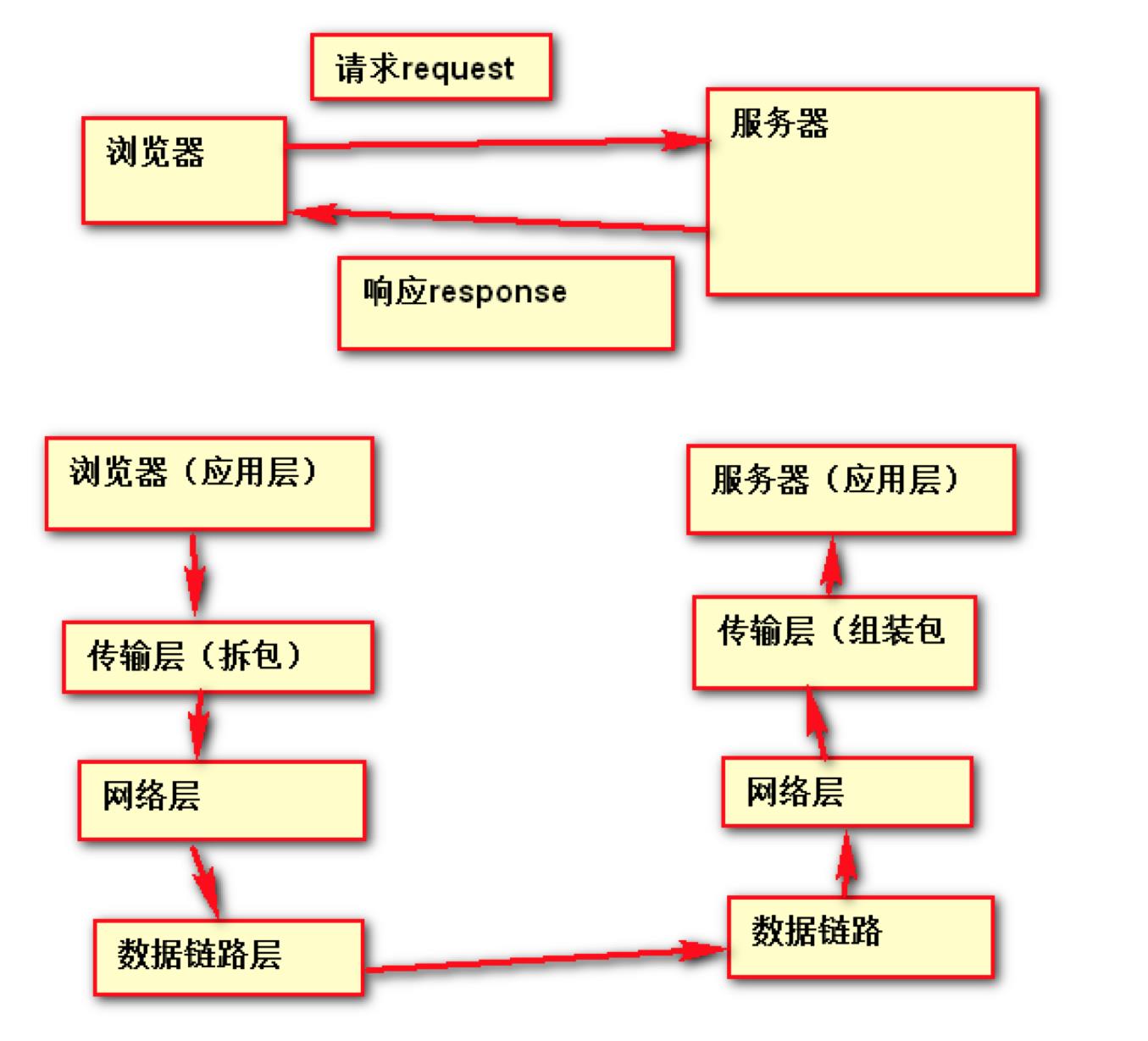
4. HTTP协议 ---> 超文本传输协议
- HTTP协议就是规定浏览器和服务器之间通信的报文的格式。
- 报文的整体格式:
报文首部 - 首部又分成了两个部分: 1.报文首行 2.报文头
空行
报文体

以上是关于浏览器从输入URL后到出现页面,这个过程发生了啥?的主要内容,如果未能解决你的问题,请参考以下文章
当用户输入一个url地址后,到看到页面的过程,期间发生了啥?