r-cnn学习:源码学习
Posted 牧马人夏峥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了r-cnn学习:源码学习相关的知识,希望对你有一定的参考价值。
论文看的云里雾里,希望通过阅读其代码来进一步了解。
参考:http://blog.csdn.net/sloanqin/article/details/51525692
首先是./tools/train_faster_rcnn_alt_opt.py,通过其main函数了解整个训练流程。
if __name__ == \'__main__\': #建议读者调试这个函数,进去看看每个变量是怎么回事
args = parse_args() #解析系统传入的argv参数,解析完放到args中返回
print(\'Called with args:\')
print(args)
if args.cfg_file is not None:
cfg_from_file(args.cfg_file) #如果输入了这个参数,就调用该函数,应该是做某些配置操作
if args.set_cfgs is not None:
cfg_from_list(args.set_cfgs)
cfg.GPU_ID = args.gpu_id # cfg是一个词典(edict)数据结构,从faster-rcnn.config引入的
# --------------------------------------------------------------------------
# Pycaffe doesn\'t reliably free GPU memory when instantiated nets are
# discarded (e.g. "del net" in Python code). To work around this issue, each
# training stage is executed in a separate process using
# multiprocessing.Process. #这里说的要使用多进程,因为在pycaffe中当某个网络被discard后,不能可靠保证释放内存资源;进程关闭后资源自然会释放
# --------------------------------------------------------------------------
# queue for communicated results between processes
mp_queue = mp.Queue() #mp指的是multiprocessing库,所以这里返回了一个用于多进程通信的队列对象
# solves, iters, etc. for each training stage
solvers, max_iters, rpn_test_prototxt = get_solvers(args.net_name) #这里返回了solvers的路径,maxiters的值,rpn_test_prototxt的路径
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
print \'Stage 1 RPN, init from ImageNet model\'
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
# 这一步是用imageNet的模型初始化,然后训练rpn网络(整个训练过程可以参考作者的论文)
cfg.TRAIN.SNAPSHOT_INFIX = \'stage1\'
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
init_model=args.pretrained_model,
solver=solvers[0],
max_iters=max_iters[0],
cfg=cfg) # 这里把该阶段需要的参数都放到这里来了,即函数train_rpn的输入参数
p = mp.Process(target=train_rpn, kwargs=mp_kwargs) # 显然,这里准备启动一个新进程,调用函数train_rpn,传入参数kwargs,所以我们进入train_rpn函数看看是如何工作的
p.start()
rpn_stage1_out = mp_queue.get()
p.join()
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
print \'Stage 1 RPN, generate proposals\'
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
# 这一步是利用上一步训练好的rpn网络,产生proposals供后面使用
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
rpn_model_path=str(rpn_stage1_out[\'model_path\']),
cfg=cfg,
rpn_test_prototxt=rpn_test_prototxt)
p = mp.Process(target=rpn_generate, kwargs=mp_kwargs)
p.start()
rpn_stage1_out[\'proposal_path\'] = mp_queue.get()[\'proposal_path\']
p.join()
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
print \'Stage 1 Fast R-CNN using RPN proposals, init from ImageNet model\'
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
#这一步是再次用imageNet的模型初始化前5层卷积层,然后用上一步得到的proposals训练检测网络
cfg.TRAIN.SNAPSHOT_INFIX = \'stage1\'
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
init_model=args.pretrained_model,
solver=solvers[1],
max_iters=max_iters[1],
cfg=cfg,
rpn_file=rpn_stage1_out[\'proposal_path\'])
p = mp.Process(target=train_fast_rcnn, kwargs=mp_kwargs)
p.start()
fast_rcnn_stage1_out = mp_queue.get()
p.join()
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
print \'Stage 2 RPN, init from stage 1 Fast R-CNN model\'
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
#这一步固定上一步训练好的前五层卷积层,再次训练RPN,这样就得到最终RPN网络的参数了
cfg.TRAIN.SNAPSHOT_INFIX = \'stage2\'
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
init_model=str(fast_rcnn_stage1_out[\'model_path\']),
solver=solvers[2],
max_iters=max_iters[2],
cfg=cfg)
p = mp.Process(target=train_rpn, kwargs=mp_kwargs)
p.start()
rpn_stage2_out = mp_queue.get()#保留训练的权重
p.join()
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
print \'Stage 2 RPN, generate proposals\'
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
#利用最终确定的RPN网络产生proposals
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
rpn_model_path=str(rpn_stage2_out[\'model_path\']),
cfg=cfg,
rpn_test_prototxt=rpn_test_prototxt)
p = mp.Process(target=rpn_generate, kwargs=mp_kwargs)
p.start()
rpn_stage2_out[\'proposal_path\'] = mp_queue.get()[\'proposal_path\']
p.join()
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
print \'Stage 2 Fast R-CNN, init from stage 2 RPN R-CNN model\'
print \'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\'
#利用上一步产生的proposals,训练出最终的检测网络
cfg.TRAIN.SNAPSHOT_INFIX = \'stage2\'
mp_kwargs = dict(
queue=mp_queue,
imdb_name=args.imdb_name,
init_model=str(rpn_stage2_out[\'model_path\']),
solver=solvers[3],
max_iters=max_iters[3],
cfg=cfg,
rpn_file=rpn_stage2_out[\'proposal_path\'])
p = mp.Process(target=train_fast_rcnn, kwargs=mp_kwargs)
p.start()
fast_rcnn_stage2_out = mp_queue.get()
p.join()
# Create final model (just a copy of the last stage)
final_path = os.path.join(
os.path.dirname(fast_rcnn_stage2_out[\'model_path\']),
args.net_name + \'_faster_rcnn_final.caffemodel\')
print \'cp {} -> {}\'.format(
fast_rcnn_stage2_out[\'model_path\'], final_path)
shutil.copy(fast_rcnn_stage2_out[\'model_path\'], final_path)
print \'Final model: {}\'.format(final_path)
通过上面的代码可以看出,整个迭代过程分为四步(参考论文)。其中后面两步固定共享卷积
层,只对RPN和fc层进行微调。
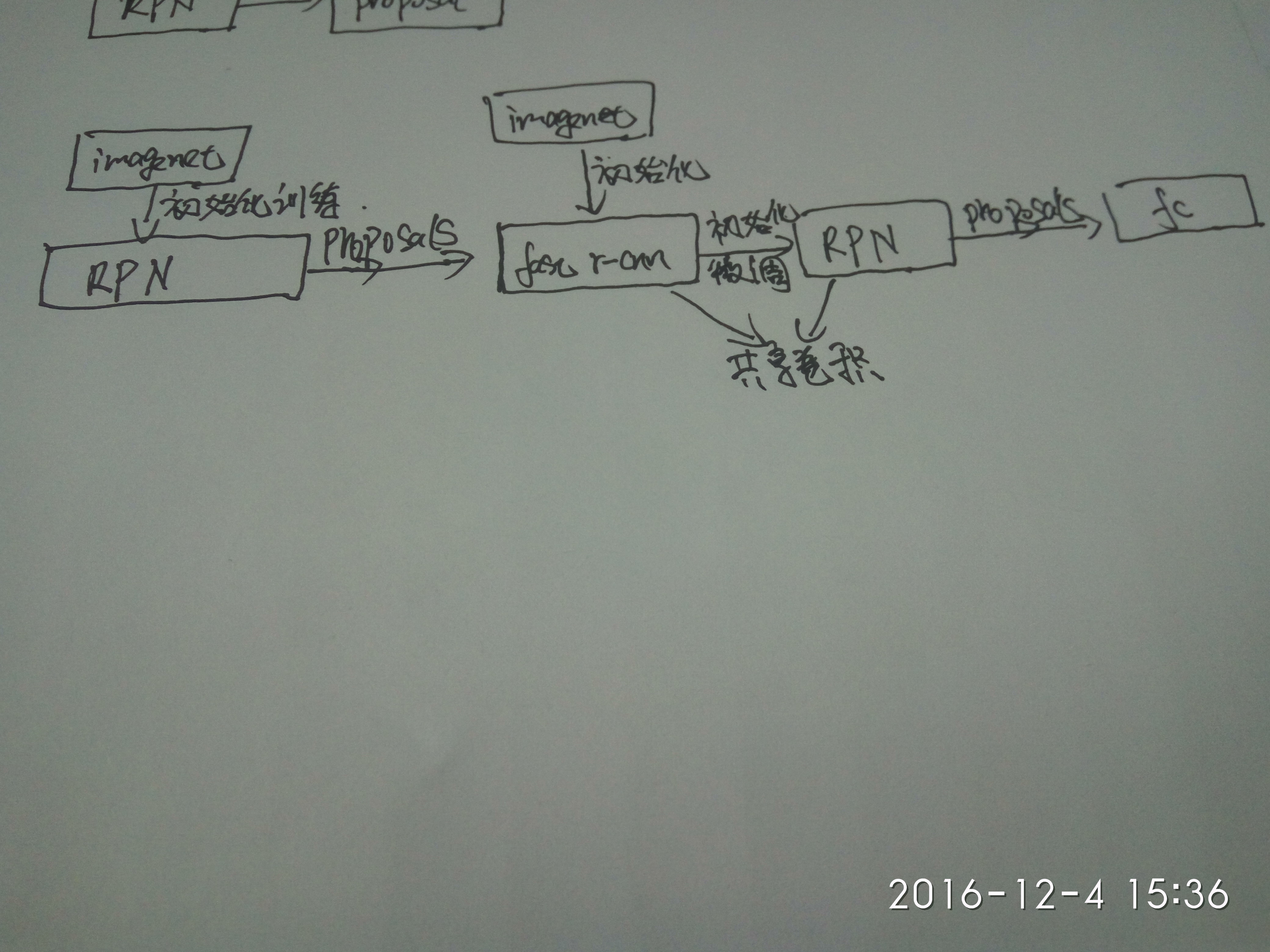
接着看看每一步是怎样的。
首先是train_rpn。从代码看出,这个函数的主要任务是,配置参数,准备数据集,
传入第一阶段的solver,调用train_net训练模型并将结果返回。
def train_rpn(queue=None, imdb_name=None, init_model=None, solver=None, max_iters=None, cfg=None): """Train a Region Proposal Network in a separate training process. """ #首先进来后继续配置了一些cfg这个对象的一些参数 # Not using any proposals, just ground-truth boxes cfg.TRAIN.HAS_RPN = True cfg.TRAIN.BBOX_REG = False # applies only to Fast R-CNN bbox regression cfg.TRAIN.PROPOSAL_METHOD = \'gt\' cfg.TRAIN.IMS_PER_BATCH = 1 print \'Init model: {}\'.format(init_model) #格式化输出字符串 print(\'Using config:\') pprint.pprint(cfg) import caffe _init_caffe(cfg) #这里是关键,准备数据集,我们在debug的时候可以发现,imdb是一个类,而roidb是该类的一个成员 roidb, imdb = get_roidb(imdb_name)#我们进入这个数据准备的函数看看 print \'roidb len: {}\'.format(len(roidb)) output_dir = get_output_dir(imdb) print \'Output will be saved to `{:s}`\'.format(output_dir) #这个solver传入的是./models/pascal_voc/ZF/faster_rcnn_alt_opt/stage1_rpn_solver60k80k.pt model_paths = train_net(solver, roidb, output_dir, pretrained_model=init_model, max_iters=max_iters) #进入train_net函数,看训练如何实现的 # Cleanup all but the final model for i in model_paths[:-1]: #把训练过程中保存的中间结果的模型删掉,只返回最终模型的结果 os.remove(i) rpn_model_path = model_paths[-1] # Send final model path through the multiprocessing queue queue.put({\'model_path\': rpn_model_path}) #通过队列将该进程运行的模型结果的路径返回
顺着train_rpn,查看train_net函数,该函数位于:./lib/fast_rcnn/train.py文件中
调用该文件中定义的类SolverWrapper的构造函数,返回该类的一个对象sw,然后调用了sw的train_model方法进行训练,
传入参数,搭建caffe的网络结构,用预训练模型完成初始化,整个过程在构造函数中完成。
"""Train a Fast R-CNN network."""
import caffe
from fast_rcnn.config import cfg
import roi_data_layer.roidb as rdl_roidb
from utils.timer import Timer
import numpy as np
import os
from caffe.proto import caffe_pb2
import google.protobuf as pb2
class SolverWrapper(object):
"""A simple wrapper around Caffe\'s solver.
This wrapper gives us control over he snapshotting process, which we
use to unnormalize the learned bounding-box regression weights.
"""
#这就是SolverWrapper的构造函数
def __init__(self, solver_prototxt, roidb, output_dir,
pretrained_model=None):
"""Initialize the SolverWrapper."""
self.output_dir = output_dir
if (cfg.TRAIN.HAS_RPN and cfg.TRAIN.BBOX_REG and
cfg.TRAIN.BBOX_NORMALIZE_TARGETS):
# RPN can only use precomputed normalization because there are no
# fixed statistics to compute a priori
assert cfg.TRAIN.BBOX_NORMALIZE_TARGETS_PRECOMPUTED
if cfg.TRAIN.BBOX_REG:
print \'Computing bounding-box regression targets...\'
self.bbox_means, self.bbox_stds = \\
rdl_roidb.add_bbox_regression_targets(roidb)
print \'done\'
# 这句话调用了caffe的SGDSolver,这个是caffe在C++中实现的一个类,用来进行随机梯度下降优化,该类根据solver_prototxt中定义的网络和求解参数,完成网络
# 初始化,然后返回类SGDSolver的一个实例,关于该类的设计可以参考caffe的网站:http://caffe.berkeleyvision.org/doxygen/classcaffe_1_1SGDSolver.html
# 然后作者把该对象作为SolverWrapper的一个成员,命名为solver
self.solver = caffe.SGDSolver(solver_prototxt)
if pretrained_model is not None:
print (\'Loading pretrained model \'
\'weights from {:s}\').format(pretrained_model)
self.solver.net.copy_from(pretrained_model)#这句话完成对网络的初始化
self.solver_param = caffe_pb2.SolverParameter()
with open(solver_prototxt, \'rt\') as f:
pb2.text_format.Merge(f.read(), self.solver_param)#这句话应该是设置了self.solver_param这个成员的参数
self.solver.net.layers[0].set_roidb(roidb)#这句话传入训练的数据:roidb
def snapshot(self):
"""Take a snapshot of the network after unnormalizing the learned
bounding-box regression weights. This enables easy use at test-time.
"""
net = self.solver.net
scale_bbox_params = (cfg.TRAIN.BBOX_REG and
cfg.TRAIN.BBOX_NORMALIZE_TARGETS and
net.params.has_key(\'bbox_pred\'))
if scale_bbox_params:
# save original values
orig_0 = net.params[\'bbox_pred\'][0].data.copy()
orig_1 = net.params[\'bbox_pred\'][1].data.copy()
# scale and shift with bbox reg unnormalization; then save snapshot
net.params[\'bbox_pred\'][0].data[...] = \\
(net.params[\'bbox_pred\'][0].data *
self.bbox_stds[:, np.newaxis])
net.params[\'bbox_pred\'][1].data[...] = \\
(net.params[\'bbox_pred\'][1].data *
self.bbox_stds + self.bbox_means)
infix = (\'_\' + cfg.TRAIN.SNAPSHOT_INFIX
if cfg.TRAIN.SNAPSHOT_INFIX != \'\' else \'\')
filename = (self.solver_param.snapshot_prefix + infix +
\'_iter_{:d}\'.format(self.solver.iter) + \'.caffemodel\')
filename = os.path.join(self.output_dir, filename)
net.save(str(filename))
print \'Wrote snapshot to: {:s}\'.format(filename)
if scale_bbox_params:
# restore net to original state
net.params[\'bbox_pred\'][0].data[...] = orig_0
net.params[\'bbox_pred\'][1].data[...] = orig_1
return filename
def train_model(self, max_iters):
"""Network training loop."""
last_snapshot_iter = -1
timer = Timer()
model_paths = []
while self.solver.iter < max_iters:
# Make one SGD update
timer.tic()#作者测量一次迭代花的时间
self.solver.step(1)# 做一次梯度下降优化
timer.toc()
if self.solver.iter % (10 * self.solver_param.display) == 0:
print \'speed: {:.3f}s / iter\'.format(timer.average_time)
if self.solver.iter % cfg.TRAIN.SNAPSHOT_ITERS == 0:
last_snapshot_iter = self.solver.iter
model_paths.append(self.snapshot())
if last_snapshot_iter != self.solver.iter:
model_paths.append(self.snapshot())
return model_paths
def get_training_roidb(imdb):
"""Returns a roidb (Region of Interest database) for use in training."""
if cfg.TRAIN.USE_FLIPPED:
print \'Appending horizontally-flipped training examples...\'
imdb.append_flipped_images()
print \'done\'
print \'Preparing training data...\'
rdl_roidb.prepare_roidb(imdb)
print \'done\'
return imdb.roidb
def filter_roidb(roidb):
"""Remove roidb entries that have no usable RoIs."""
#判断是否是有效roidb
def is_valid(entry):
# Valid images have:
# (1) At least one foreground RoI OR
# (2) At least one background RoI
overlaps = entry[\'max_overlaps\']
# find boxes with sufficient overlap
fg_inds = np.where(overlaps >= cfg.TRAIN.FG_THRESH)[0]#大于某个阈值为前景
# Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)
bg_inds = np.where((overlaps < cfg.TRAIN.BG_THRESH_HI) & #在某两个阈值之间为背景
(overlaps >= cfg.TRAIN.BG_THRESH_LO))[0]
# image is only valid if such boxes exist
valid = len(fg_inds) > 0 or len(bg_inds) > 0#要么为前景,要么为背景,则为有效roidb
return valid
num = len(roidb)
filtered_roidb = [entry for entry in roidb if is_valid(entry)]
num_after = len(filtered_roidb)
print \'Filtered {} roidb entries: {} -> {}\'.format(num - num_after,
num, num_after)
return filtered_roidb
# 该函数先是调用了该文件中定义的类SolverWrapper的构造函数,返回了该类的一个对象sw,然后调用了sw的train_model方法进行训练
# 传入参数,搭建caffe的网络结构,用预训练模型完成初始化,这些过程就是在该构造函数中实现的,进入这个构造函数看看
def train_net(solver_prototxt, roidb, output_dir,
pretrained_model=None, max_iters=40000):
"""Train a Fast R-CNN network."""
roidb = filter_roidb(roidb)#删除一些不满足要求的输入图片
sw = SolverWrapper(solver_prototxt, roidb, output_dir,
pretrained_model=pretrained_model)#调用构造函数
print \'Solving...\'
model_paths = sw.train_model(max_iters)#开始训练模型
print \'done solving\'
return model_paths
以上是关于r-cnn学习:源码学习的主要内容,如果未能解决你的问题,请参考以下文章
TensorFlow2深度学习实战(十七):目标检测算法 Faster R-CNN 实战
TensorFlow2深度学习实战(十六):目标检测算法Faster R-CNN解析
TensorFlow2深度学习实战(十六):目标检测算法Faster R-CNN解析