HDFS体系结构
Posted Evil_XJZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS体系结构相关的知识,希望对你有一定的参考价值。
1.数据块:适合大文件的存储
好处:可以存储比单一磁盘大的文件、简化了存储管理(将管理块和管理文件的功能区分开)、方便容错(数据块进行)
为什么块的大小比磁盘块大的多?减少管理数据块的开销、同时在对文件进行读写时较少寻址开销、可以减少名字节点管理文件与数据块的关系的开销
2.名字节点与第二名字节点(都只有一个)
1).名字节点是HDFS中主从结构中的主节点上运行的主要进程,它知道主从结构中的从节点,数据节点执行底层的IO任务
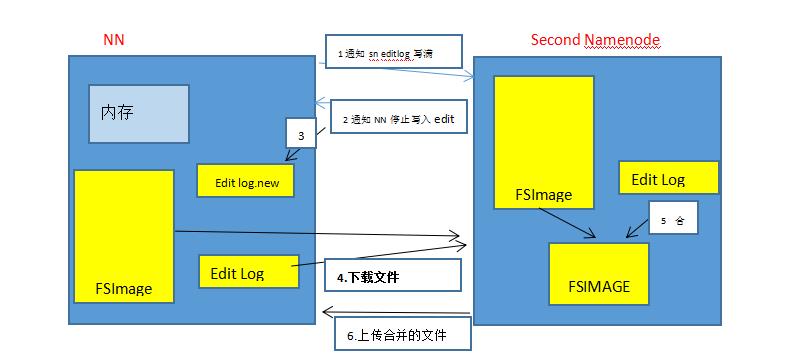
名字节点维护整个文件系统的文件目录树、文件和目录的元信息、文件的数据块索引(每个文件对应的数据块列表)。这些信息以两种形式存储:命名空间镜像FSImage、命名空间镜像的编辑日志EditLog。
第二命名节点:定期合并命名空间镜像与命名空间镜像的编辑日志的辅助守护进程。
客户端写入数据时:
1).写入数据时,先向NN询问是否可以写入(已存在等情况),NN将元数据写入EditLog文件中
2) NN通知客户端可写入,客户端写入结束后,通知NN写入完毕,NN将editLog的元数据写入内存
3)当Edit Log写满时,进行FSImage与Edit Log合并,在secondary namenode上进行。并通知NN停止写入Edit Log,此时会创建一个新的Edit Log.new,当合并结束后,将合并后的文件上传到NN,并删除之前的Edit Log,将Edit Lod.new改名为EditLog
注意:在写入时,只要写入了一个块就算写入成功,第二个块由第一个块去写,一次类推,若副本写入失败,通知NN,重新再指定位置写入副本
2).第二名字节点(只有一个)
第二名字节点与名字节点的区别:他不接受或记录与HDFS相关的任何实时变化,只是进行合并得到一个新的命名空间。该命名空间会上传到名字节点,替换原有的命名空间,并清空上述日志文件。
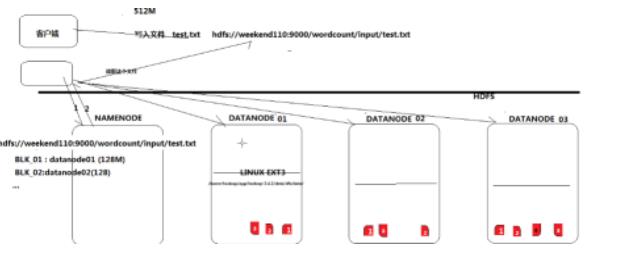
读文件:客户端在进行读文件时,首先会向namenode询问文件的每个数据块的位置信息,然后由客户端和数据节点进行通信。在写入文件时,当写入一个副本时,即返回成功。由成功写入的数据节点与其他数据节点通信,复制数据块。
3.数据节点
在数据节点上,HDFS文件是以Linux系统上的普通文件进行存储
4.客户端
HDFS提供了与客户端交互的手段
DistributedFileSystem继承自FileSystem,实现了HDFS文件系统界面。DFSDataInputStream与DFSDataOutputStream分别继承自FSDataInputStream FSDataOutputStream提供了读写HDFS文件的输入输出流
以上是关于HDFS体系结构的主要内容,如果未能解决你的问题,请参考以下文章