大数据Lambda架构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Lambda架构相关的知识,希望对你有一定的参考价值。
1 Lambda架构介绍
Lambda架构划分为三层。各自是批处理层,服务层,和加速层。
终于实现的效果,能够使用以下的表达式来说明。
query = function(alldata)
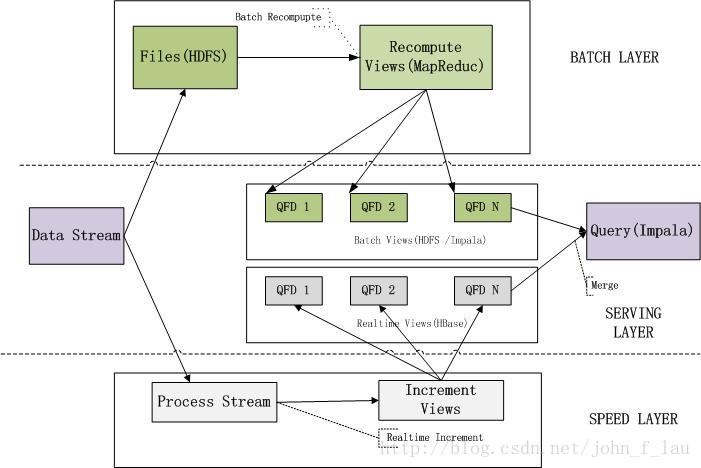
1.1 批处理层(Batch Layer, Apache Hadoop)
批处理层主用由Hadoop来实现,负责数据的存储和产生随意的视图数据。
计算视图数据是一个连续的操作,因此。当新数据到达时,使用MapReduce迭代地将数据聚集到视图中。
将数据集中计算得到的视图,这使得它不会被频繁地更新。依据你的数据集的大小和集群的规模,不论什么迭代转换计算的时间大约须要几小时。
1.2 服务层(Serving layer ,Cloudera Impala)
服务层是由Cloudera Impala框架来实现的,总体而言,使用了Impala的主要特性。从批处理输出的是一系列包括估计算视图的原始文件。服务层负责建立索引和呈现视图。以便于它们可以被非常好被查询到。
因为批处理视图是静态的,服务层只须要提供批量地更新和随机读,而Cloudera Impala正好符合我们的要求。为了使用Impala呈现视图。全部的服务层就是在Hive元数据中创建一个表。这些元数据都指向HDFS中的文件。随后,用户立马可以使用Impala查询到视图。
Hadoop和Impala是批处理层和服务层极好的工具。
Hadoop可以存储和处理千兆字节(petabytes)数据,而Impala可以查询高速且交互地查询到这个数据。但是。批处理和服务层单独存在,无法满足实时性需求。原因是MapReduce在设计上存在非常高的延迟,它须要花费几小时的时间来将新数据展现给视图。然后通过媒介传递给服务层。
这就是为什么我们须要加速层的原因。
1.3 加速层 (Speed layer, Storm, Apache HBase)
在本质上,加速层与批处理层是一样的,都是从它接受到的数据上计算而得到视图。加速层就是为了弥补批处理层的高延迟性问题,它通过Strom框架计算实时视图来解决问题。实时视图只包括数据结果去供应批处理视图。同一时候,批处理的设计就是连续反复从获取的数据中计算批处理视图,而加速层使用的是增量模型,这是鉴于实时视图是增量的。加速层的高明之处在于实时视图作为暂时量。只要数据传播到批处理中,服务层中对应的实时视图结果就会被丢掉。这个被称作为“全然隔离”,意味着架构中的复杂部分被推送到结构层次中。而结构层的结果为暂时的,大慷慨便了连续处理视图。
令人疑惑的那部分就是呈现实时视图。以便于它们可以被查询到。以及使用批处理视图合并来获得所有的结果。
因为实时视图是增量的。加速层须要同一时候随机的读和写。为此,我将使用Apache HBase数据库。
HBase提供了对Storm连续地增量化实时视图的能力。同一时候,为Impala提供查询经批处理视图合并后得到的结果。Impala查询存储在HDFS中批处理视图和存储在HBase中的实时视图,这使得Impala成为相当完美的工具。

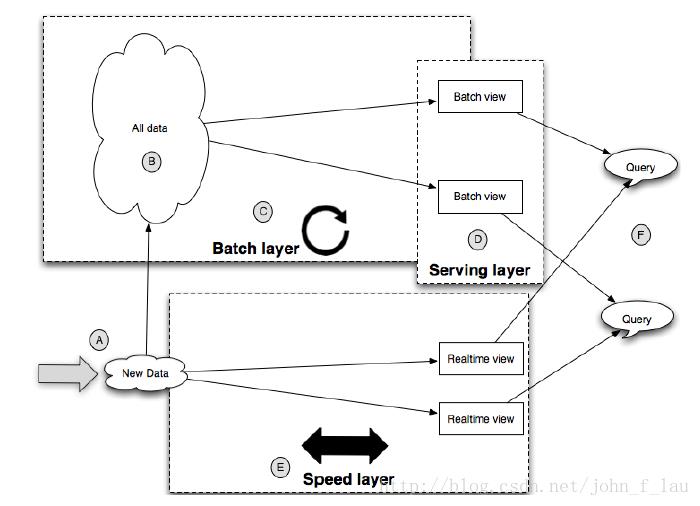
Lambda抽象架构也能够这样来描写叙述:
以上是关于大数据Lambda架构的主要内容,如果未能解决你的问题,请参考以下文章