微软数据挖掘算法:Microsoft 时序算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微软数据挖掘算法:Microsoft 时序算法相关的知识,希望对你有一定的参考价值。
前言
本篇文章同样是继续微软系列挖掘算法总结,前几篇主要是基于状态离散值或连续值进行推测和预测,所用的算法主要是三种:Microsoft决策树分析算法、Microsoft聚类分析算法、Microsoft Naive Bayes 算法,当然后续还补充了一篇结果预测篇,所涉及的应用场景在前几篇文章中也有介绍,有兴趣的同学可以点击查看,本篇我们将总结的算法为Microsoft时序算法,此算法也是数据挖掘算法中比较重要的一款,因为所有的推算和预测都将利用于未来,而这所有的一切都将有一条时间线贯穿始终,而这将是时序算法的侧重点。
应用场景介绍
通过前几篇文章的介绍,我们已经能预测出影响某种行为的因素有哪些,并且根据这些因素综合挖掘出我们的最优客户群体(将会购买自行车),这也是上面介绍的几种算法的长项,但是会不会觉得从大数据中获取的信息太少了点,与很多问题仅仅通过上面几种算法是推算不出来的,但这些信息恰巧是上层领导关注的,比如说:
1、作为数据分析人员,你能不能根据以往的销售情况预测出明年的销售业绩?这样的问题怎么解决?有哥们会这么解决了,哈...我取去年一年的销售值做平均值,那如果不足一年呢?那要是预测明年一月份的呢?....
2、能不能根据以往的销售情况预测出销售的旺季,像房地产行业的“金九银十”说的就是这个,这些都是资深销售人员的经验总结,但是你能保证公司里面有这种人?即便有你能保证他说的正确?即便正确能保证他说的适合别的产品?即便适合能保证适合不同的地区?....我那个去...这些的这些稍后我们让数据来告诉你!
3、不同地区的销售规律是否一致?也就是说是否为同一种销售策略....哪一种销售策略更适合那一类产品的方式..各种产品之间的销售量是否会有影响、存不存在连带销售?是不适合我们做捆绑销售。
以上的这些问题我们通过Microsoft时序算法都可以解决,而这些问题也就是该算法的应用场景,闲言少叙,我们进入本篇的正题。
技术准备
(1)同样我们利用微软提供的案例数据仓库(AdventureWorksDW2008R2),这这里我们只需要用到一张表,确切的说是一张视图vTimeSeries,其实这里面就是记录的往年不同月份的销售汇总值,稍后我们将详细分析这部分数据。
(2)VS2008、SQL Server、 Analysis Services没啥可介绍的,安装数据库的时候全选就可以了,这里前段时间有人问我为什么他的vs工具没有新建数据挖掘工程的模板,这里提一下,其实vs作为微软的主打开发软件,所以它的更新速度是远远快于数据库更新版本,所以要选择开发数据挖掘解决方案的时候需要在开始菜单中找到SQL Server目录下的vs连接即可。
操作步骤
(1)新建解决方案,然后数据源,然后数据源视图,很简单的步骤,不明白的可以看我们前面几篇文章,我们直接看图
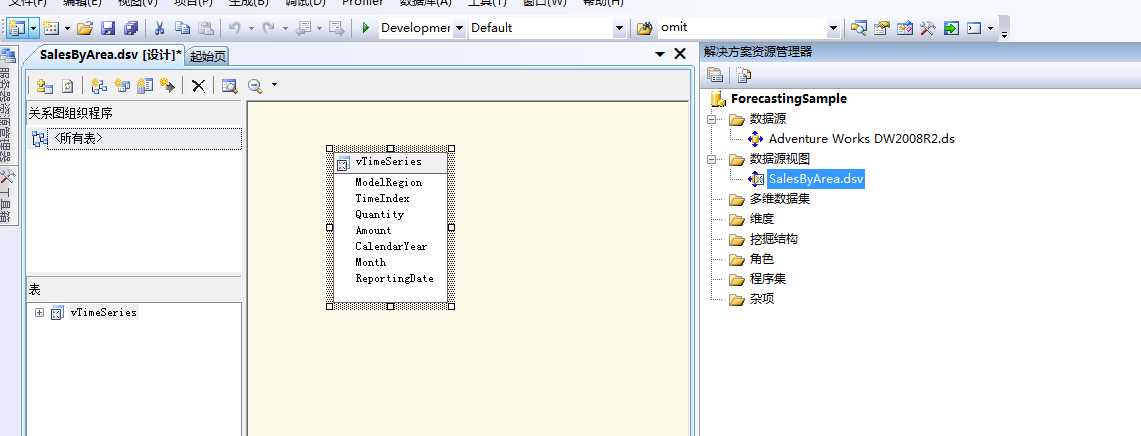
我们给解决方案取了个名字,然后从数据源中找到了我们需要挖掘的表,将我们需要的表创建好,取了个名字为:SalesByArea,可以看到这张表就是记录往年各个月份的销售记录和销售业绩,下面我们对这个表里面的数据进行粗略分析。
(2)预览数据,分析源数据结构内容
这里我们需要对要分析的数据进行分析,先看看里面有那些内容,是不是满足时序算法的数据要求条件。同样我们右键“浏览数据”,我们选择随机抽样,抽样数据为5000行。具体方法这里不赘述,具体方法可参考前篇文章,我们直接看图
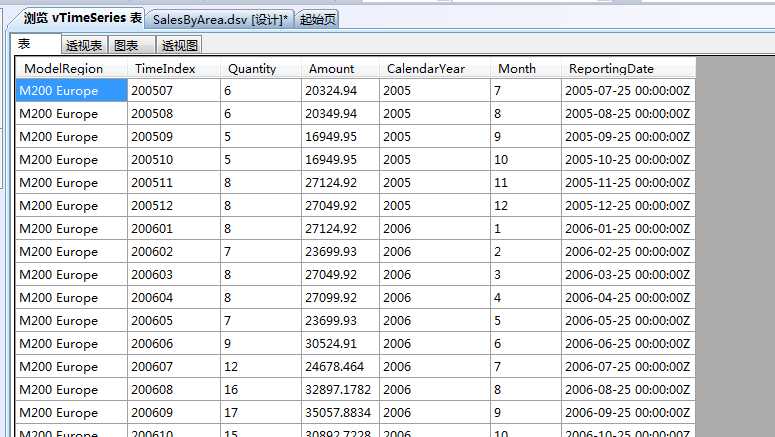
这里面有几列数据,其实内容挺简单的,我们来看,有自行车品牌和地区、时间线、销售数量、销售额度、年、月、报告日期。从报告日期来看基本上是每个月的25号形成报告,然后每个月生成一份,在利用Microsoft时序算法中对数据是有要求的:
1、要求分析数据序列必须含有时间序列,并且序列值为连续...这个可以理解...如果没有连续值就谈不上推测,因为数据本身他就没有规律可循....
2、要求分析数据序列存在唯一标示值,其实也就说传统意义上面的主键,这个在每个算法中都要用
从上面的数据中我们可以将报告日期和第一列自行车品牌和地区(ModelRegion)形成组合主键满足上面的第二点要求,因为同一个时间一个品牌在一个地区只能产生一个销售值。
我们来详细分析上面的时间看看能不能满足第一个条件,我们选择透视表,这个和Excel里面的透视表是一样的,用起来基本没啥问题,我们将明细数据拖入到区域中间,将列选择报告日期、行选择自行车品牌区域(ModelRegion),我们来看看数据:
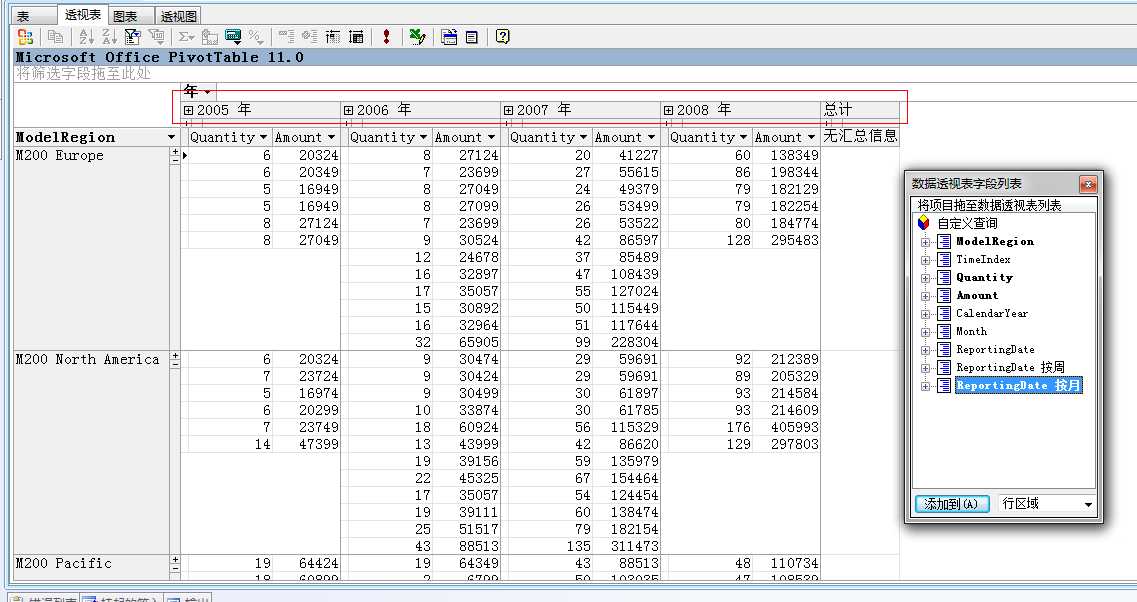
我们可以看到,这张往年销售记录表中包含了从2005年到2008年的销售记录,其中06年和07年都是全年每一个月份都会含有一个记录,而2005年、08年只有半年的数据,其实这里08年只有半年数据是正常的,因为微软案例数据库AdventureWorksDW2008R2产生的日期就是在这里,也就是说我们会预测这之后的销售记录,05年只有半年表示数据时从这里开始的,这个没啥问题...我们继续向下拖动
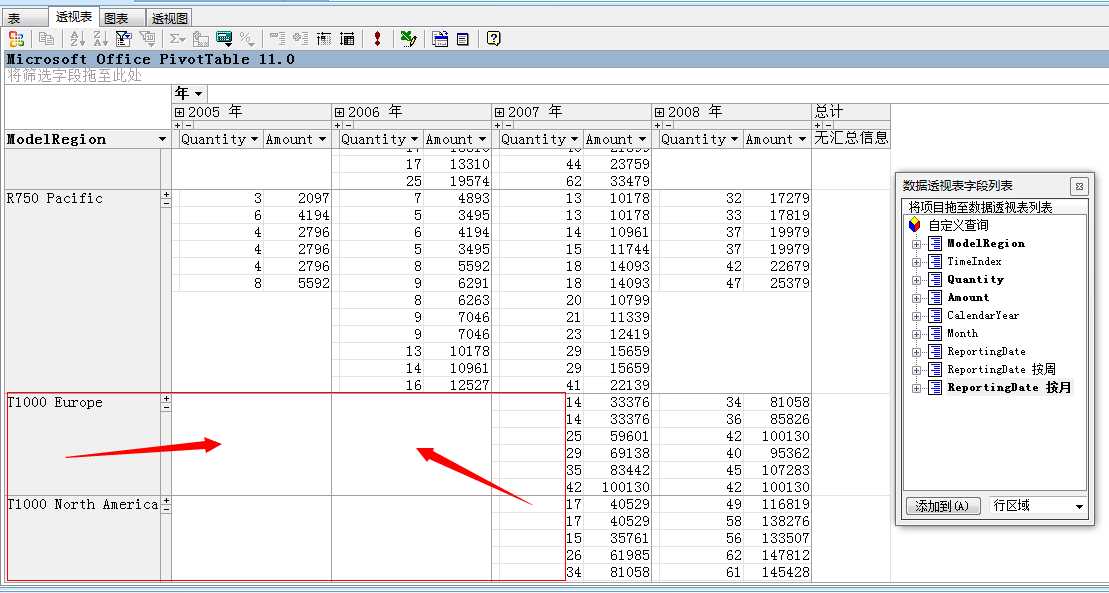
我去...这下面的几种产品在05年、06年就没有任何销售记录,这有两种可能,第一种是这两个产品从06年才开始引进销售的,所以之前的数据没有是正常的,当然还有一种极端的情况那就是这两年这个产品销售量就为0...对于这种情况我们要跟业务方确认做处理,对于我们分析人员而言...销售记录不存在空值,也就是说这地方没有销售显示值应为0,而非空!
我们点击年份进入月份,详细的看一下值。
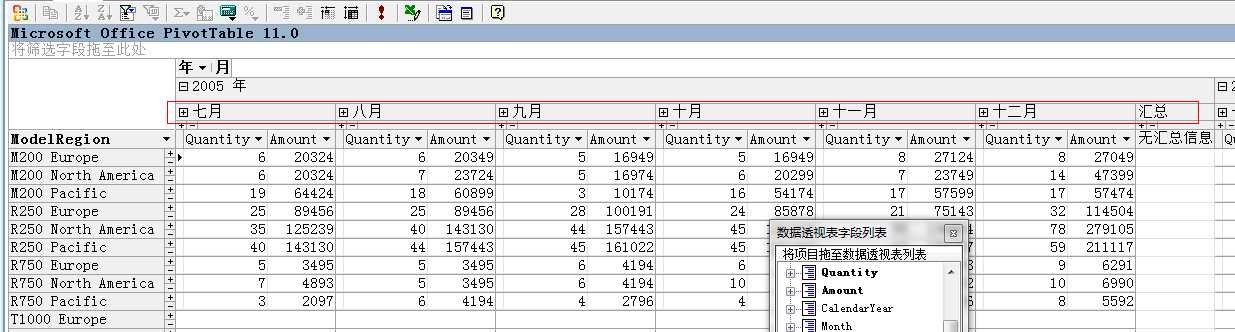
看来这些数据开始日期真是从05年7月份开始,然后到08年6月结束,而且这之间每个月份的数据都是连续的,也就是说从开始到结束连续的每个月都有值,我们向下面拖
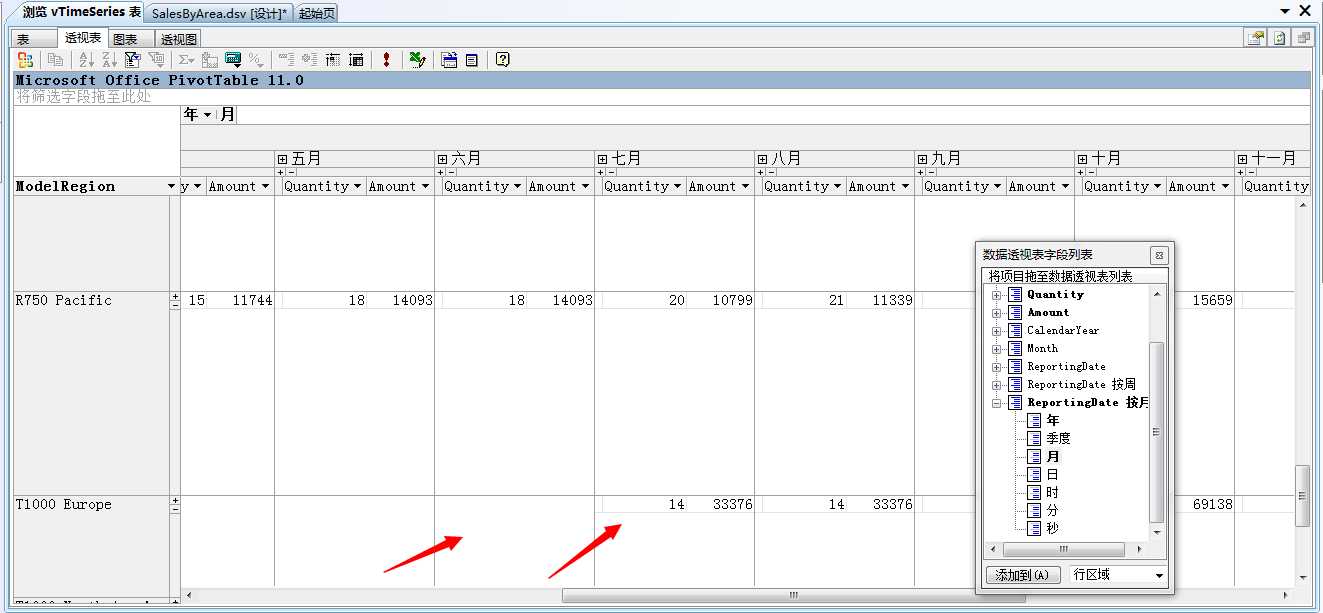
的确,下面的这几种商品是从07年7月份开始产生销售,结束日期都是到08年6月份结束。
经过上面的分析,其实这种表中的数据是满足我们Microsoft时序算法的数据要求的,其中存在连续的时间轴维度,只是有几种产品销售开始日期不是全部从开始日期开始的,对于这种情况时序算法是允许的,只要保证在我们时间轴维度中每一个序列都有统一的结束日期,并且区间时间为连续的既可以。
当然可以通过其它方式分析源数据,咱这里就不进行了。
(3)新建挖掘结构
在挖掘结构上右键,现在新建数据挖掘结构,然后下一步...继续然后下一步...这里不做赘述,不明白可以参考前几篇文章,我们选择Microsfoft时序算法,看图
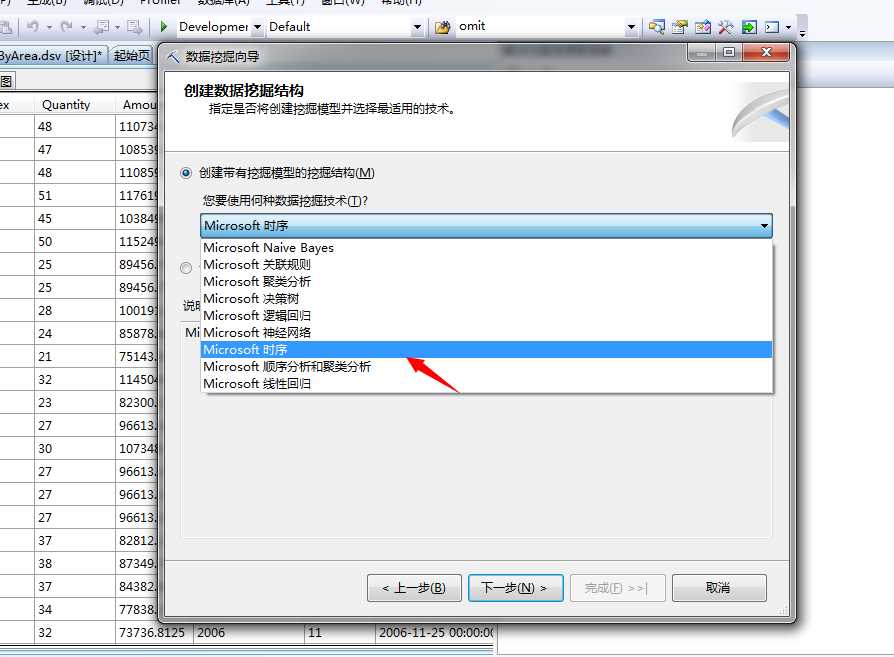
点击下一步,有几个关键点我们需要设置一下,我们来看图:
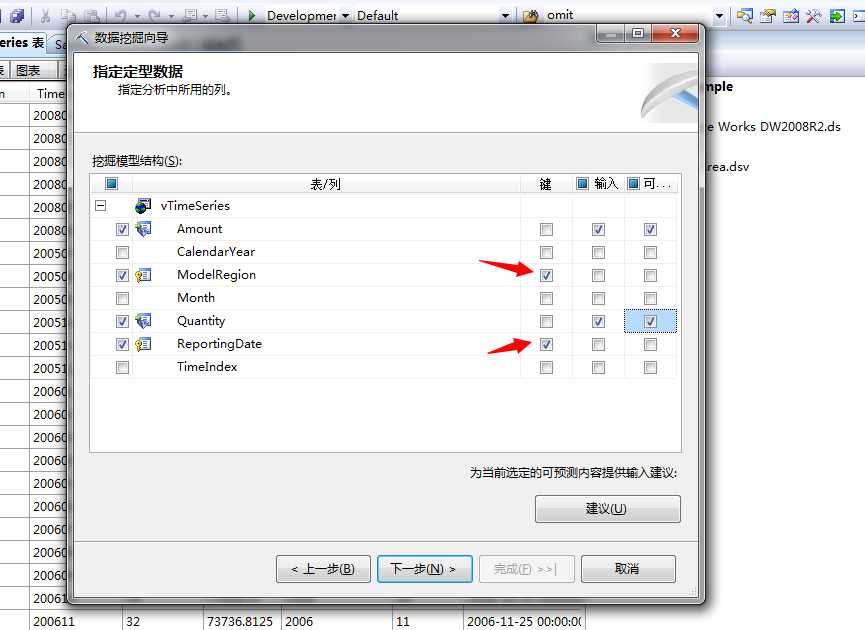
这里我们将品牌和区域、报告日期联合形成键列,将销售量和销售业绩两列即作为输入又作为输出,因为这两列即使我们历史分析要用的输入值,也是我们以后将要推测的输出列,当然也可以通过建议进行分析,这里我们很明白要做的事情,我们点击下一步,
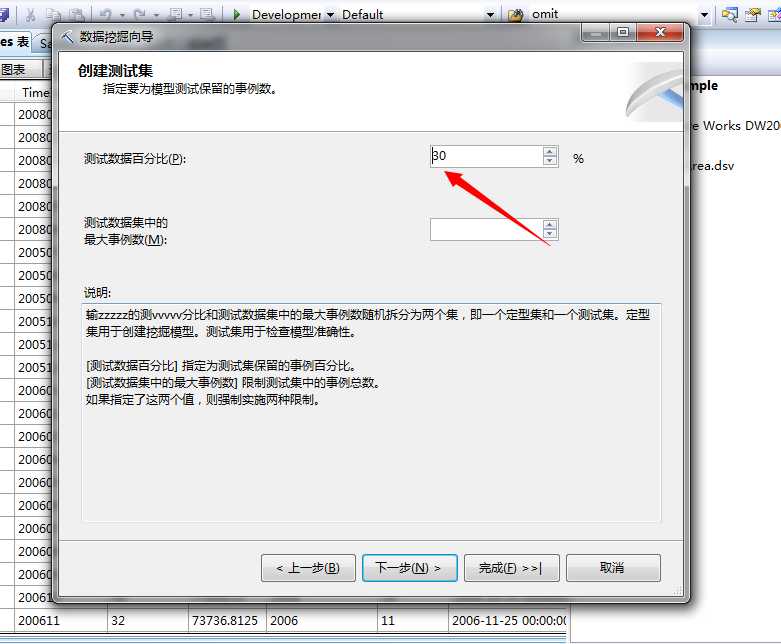
我们留下30%的事实,做后面的准确性验证测试,然后取个名字:Forecasting,然后选择下一步
(4)参数配置
对于Microsoft时序算法有几个参数比较重要,需要单独配置,这里我们介绍一下
PERIODICITY_HINT:该参数提供了有关数据模式重复频率的算法信息。简单点讲就是时间序列的重复迭代时间间隔,比如本篇文章中用到的时间轴就是为每个月更改一次,且周期为年为单位,所以我们将这个参数设置成12,意思是每十二个月重复一次。
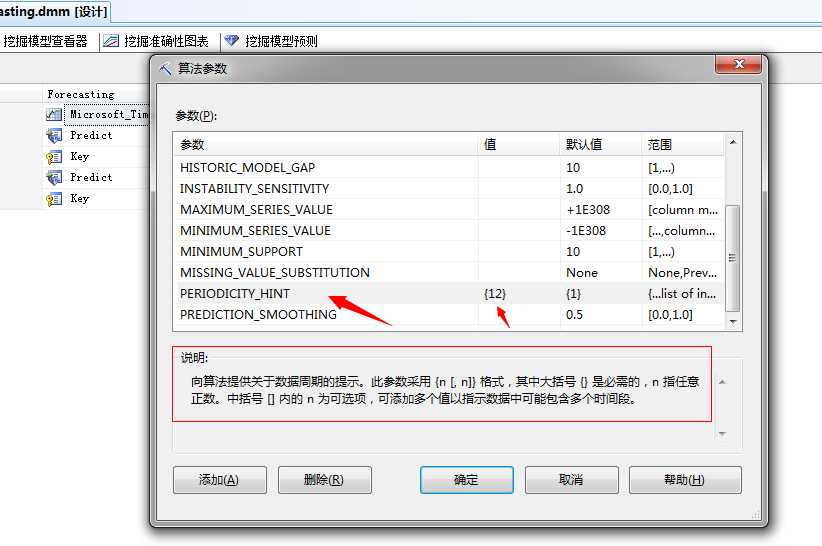
然后我们就需要部署、处理该挖掘模型了。然后下一步我们进行结果分析。
结果分析
部署完程序之后,我们通过“挖掘模型查看器”进行查看分析,不废话,我们直接看图:
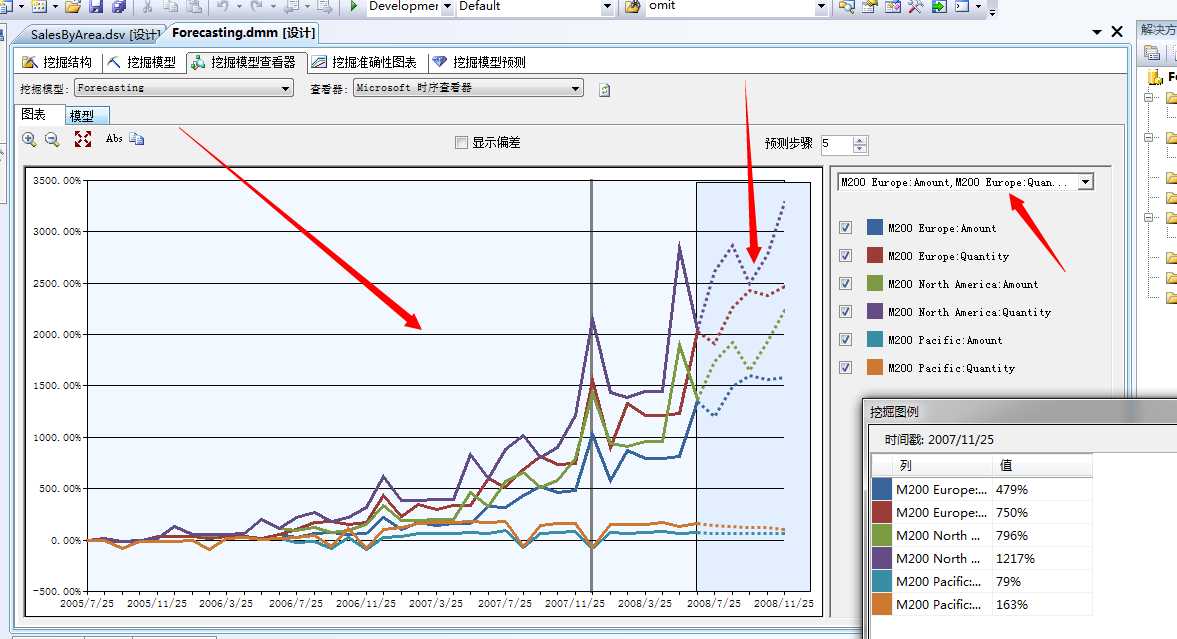
上面的图就是Microsoft时序算法出来的结果图了,挖掘模型查看器为这种算法提供了两个面板查看,一个是图表、另一个是模型,下面我们将以此详细分析,平常最常用的就是图表模型查看器,图标区分为两块,如上图,前半部分模型历史分析数据,后面模糊区为推测区域,右侧一个序列筛选的下拉选项框,从横轴中我们可以看到,时间区间为2005年7月25——2007年11月25折线以实线表示,后面的区域为预测区域,预测区间为2008年7月25日至2008年11月25,折线以虚线表示。
嘿嘿...看起来是不是很清爽。
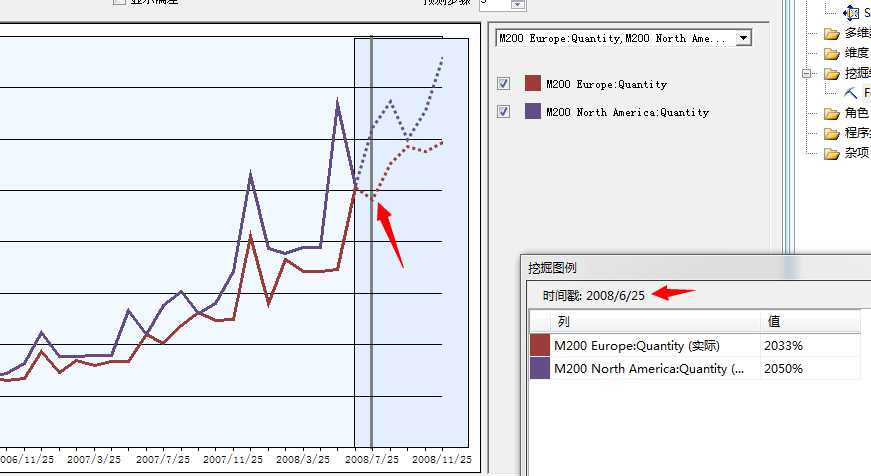
我们来选择一个产品来看看,我们选择M200 Europe、M200 NorthAmerica的销量情况,下面看图:
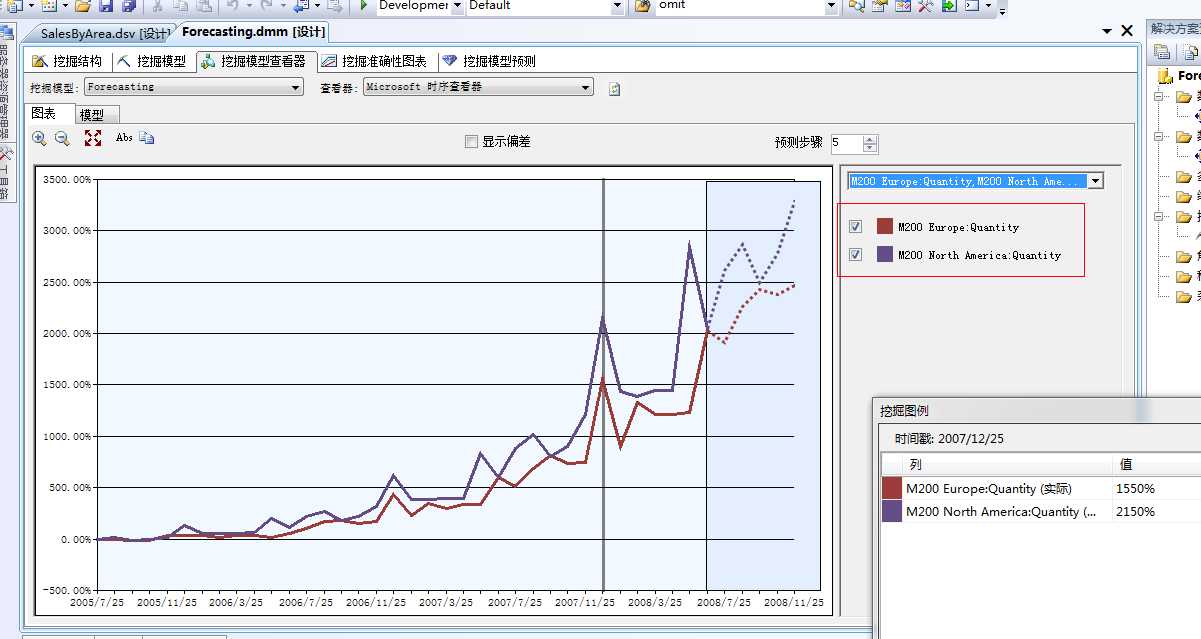
通过点击图表中间的点击线,我们可以分析这款自行车在这个两个地区一年中的销售峰值为5月和12月,也就是所谓的旺季...这没啥特别的对吧,5月大春天...嗯?米国五月应该也是春天...春天适合户外...自行车买的好也理所当然,这里其实我们更关心明年的旺季或者淡季是啥时候,因为根据此我们更能够采取相应的应对措施,比如旺季多增加库存,淡季减少库存等吧,我们来看M200这款产品在08年的旺季是那个月....
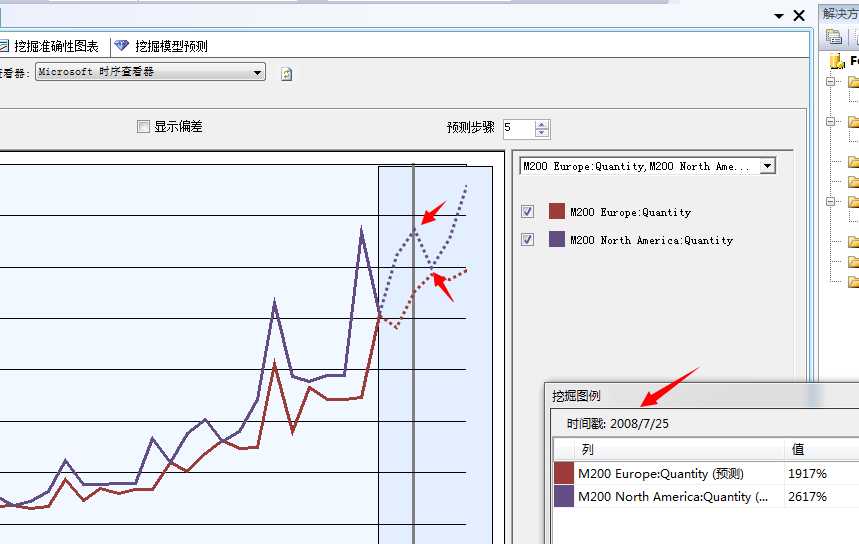
看到了吧,08年的7月份将是这款产品的旺季,同样淡季为九月份
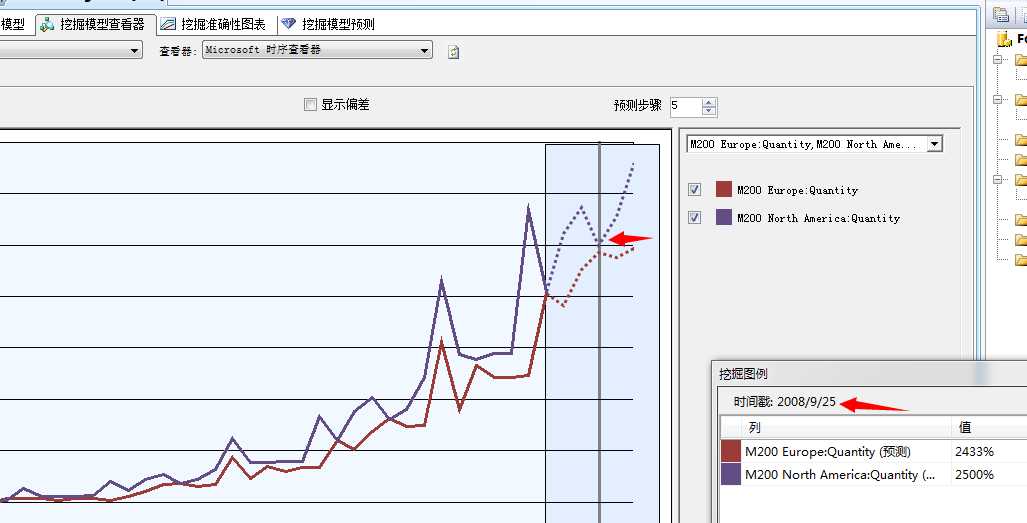
而这是在欧洲的销量,但是在北美就不一样了,它反而是在08年的9月份为旺季,是吧,上图中可以看到,说明这两个区域的销售量还会有蛮大区别的,仅仅凭靠经验是分析不出来的对吧。同样它的淡季反而提前到来了,看下图:
同样从上面的所有的这两款产品的产品图中可以看到,这两款产品的销量是蒸蒸日上,也就是所谓的朝阳好卖的产品,所带来的利润肯定也在未来将会更好,我们可以点击推测出他们在08年的营业额度是多少。我们来看图:
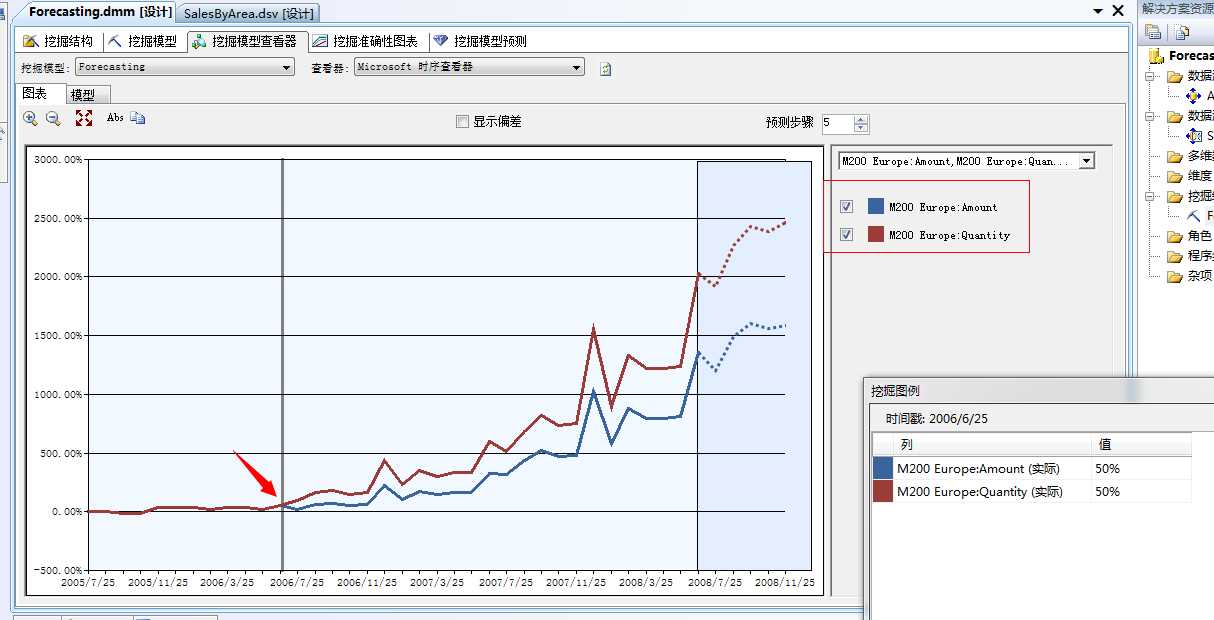
从上面图可以看出,根据折线图规律可以看出销售额度和销售量是相关的,汗...废话!当销售量增加的时候,销售额度也跟着增加,但是从上图中可以看到一个有趣的信息,那就是在2006年6月25号以前销售额度和销售量是一条线,但是之后就分开了...对吧?这说明什么?...之后的销售数量开始慢慢的比销售额度增高了...啥意思?也就是说这款产品卖得多了,他的销售额度反而少了...汗...啥原因?原因很简单....产品降价了!..产品降价了所以它的销量上去了,同比这里我说的是同比他的销售额度反而降下来。
不管怎么着这款产品随着时间的增长慢慢的开始大卖了..而且营业额也在增加,尤其在2007年底的时候有了一个大面积的跳跃,我估计是采取了比较好的措施。从图中我们还可以看到将在2008年8月份有一个很大的销售额度...推测出来的销售额为2267%。当你拿着这份预测成绩单给BOSS...BOSS会不会睡梦中都能把自己笑醒...
是不是所有的产品都这么叫卖呢,我们来展开其它的几款看看:
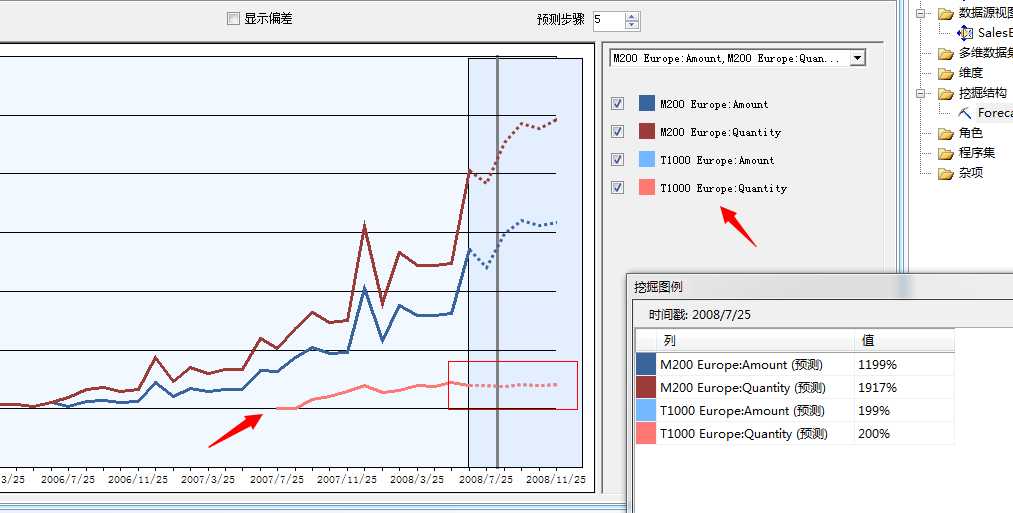
嘿嘿...我们找到了一款比较不叫座的产品...T1000,从图中可以看到,这款产品是2007年8月份才上市的,并且已经上市销量开始提升,但是以后开始慢慢萎缩...我去...经预测到08年的时候这款产品销售额平平,还有大跌的趋势!如果你作为领导层看到这种业绩该咋办?想法子?还是直接退市?
如果此曲线显示不够直观,我们可以通过更改预测步骤数,更改折线的平滑程度,来对未来的预测显示的更直观一点。当然调整这个参数也可以更改预测区间
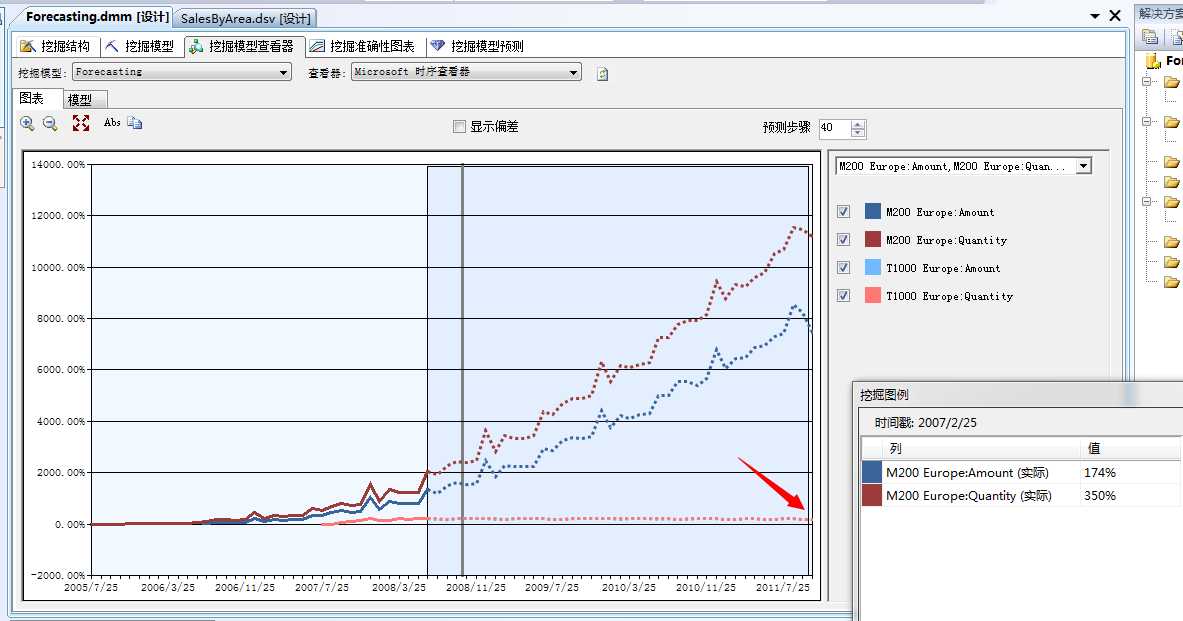
是吧...这个T1000产品到2011年的时候估计就埋没了...看样子还有可能成负数...也就是会出现赔本赚吆喝的境地,当然预测的时间区间越远,该算法的准确度将更低,毕竟嘛谁也不能预测太久未来的事情,因为很多因素都在变化着。
下面我们来看看VS为我们提供的另一个面板“模型”,该面板提供了每一个序列类型根据数据内容形成决策树算法,推测每个序列随着时间轴的进展所影响该序列的因素值,详细信息可以参照我前面的文章:Microsoft决策树算法。
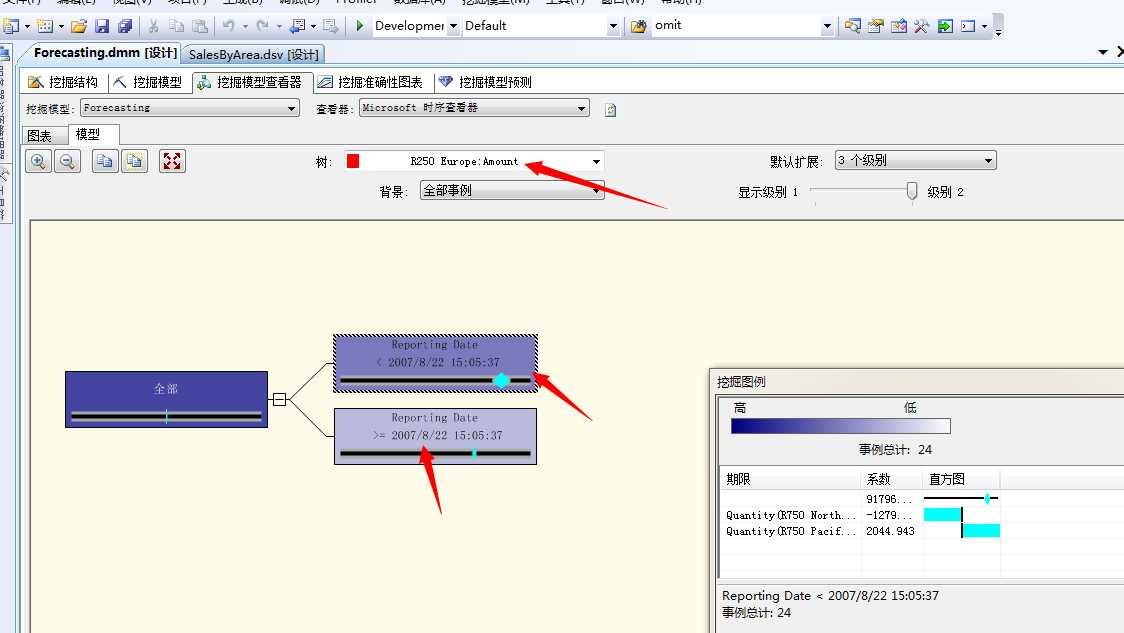
上图中可以看到R250这款产品将以2007年8月22日这天为分界线,在这之前销量值远远大于这之后的销量,神马原因?怎么回事?这些的就需要去咨询业务部分了,我们从数据中可以看到这个状况,这些情况的发生都一般都会有巨大的原因因素来促成,举个例子:比如今年9月30,国内发布了新的房贷政策...如果该曲线是房价预测线,这个因素就能体现在那天、再比如上一周北京持续雾霾...如果该曲线是口罩的销售量预测线,这个因素就是促成这个节点的原因.....
这个面板展示结果我们就不详细分析了,它的展示方式就是决策树的分析方法,有兴趣的同学可以参照我以前的文章。
上面的过程中我们只分析了整个挖掘的过程,根据折线图分析了部分产品的趋势和销售问题,其实还缺少了最重要的一个步骤,那就是告诉我明年一年月份销售的业绩和销售额度是多少,在我们以数据说话的时代,刚给我们产生一个趋势图用处有限,毕竟市面上随便找一款图表软件我都能搞的出来,甚至搞的比你这个更好看!
我们后面的文章将解决这个问题,通过预测我能明确地预测出明年甚至后年每个月份的销售业绩和销售额度是多少!拿着这份报告你就可以理直气壮的去找BOSS,剩下的事就是他去做了....
结语
结语...该写什么呢?我们来总结下,数据挖掘的含义,其实整个流程都是在利用数据加上数学来推测和预知未知的事情,而当前的我们所利用的数学已经可以来产生预测,同样随着IT行业互联网近乎十年的蓬勃发展所积累的数据也可以满足数据要求,并且随着数据存储成本的降低,结构化和非结构化数据的转变成本降低,我们所身处的就是一个数据的海洋,而当前迫切需要转变的是我们,或者说是一个观念的转变,一个思维进步的过程,这就是大数据时代的意义所在!
文章的最后我们给出前几篇算法的文章连接:
微软数据挖掘算法:Microsoft Naive Bayes 算法(3)
原文地址:(原创)大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 时序算法)
以上是关于微软数据挖掘算法:Microsoft 时序算法的主要内容,如果未能解决你的问题,请参考以下文章
基于微软案例数据库数据挖掘知识点总结(Microsoft 时序算法——结果预算+下期彩票预测篇)
大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 时序算法)