MPI学习3MPI并行程序设计模式:不同通信模式MPI并行程序的设计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MPI学习3MPI并行程序设计模式:不同通信模式MPI并行程序的设计相关的知识,希望对你有一定的参考价值。
学习了MPI四种通信模式 及其函数用法:
(1)标准通信模式:MPI_SEND
(2)缓存通信模式:MPI_BSEND
(3)同步通信模式:MPI_SSEND
(4)就绪通信模式:MPI_RSEND
四种通信模式的区别都在消息发送端,而消息接收端的操作都是MPI_RECV。
1.标准通信模式
原理图如下
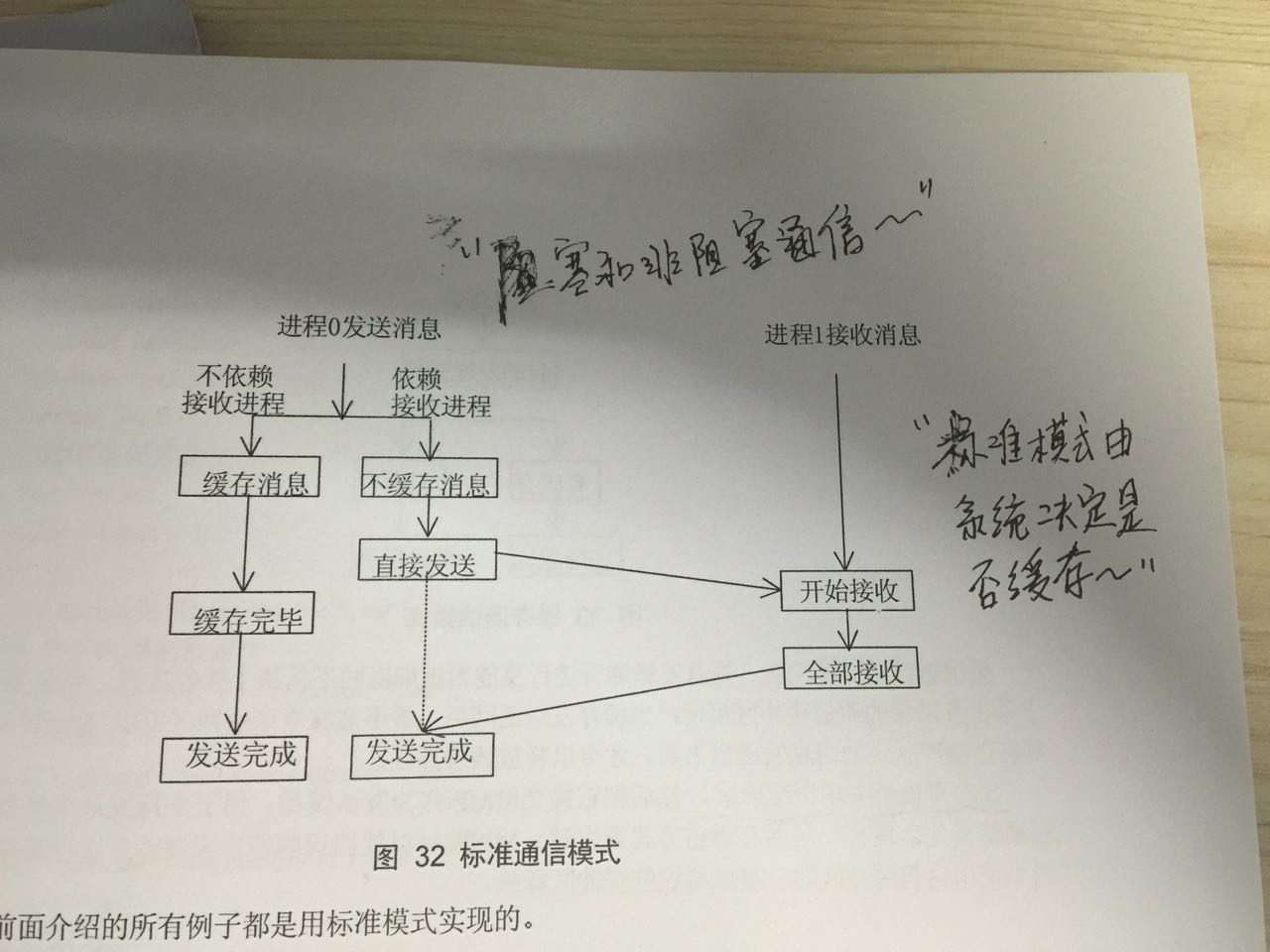
标准通信模式由MPI决定是否用缓存。
如果MPI决定缓存将要发出的数据:发送操作不管接受操作是否执行,都可以进行;而且缓存结束后发送操作就可以返回,不需要等待接受操作收到数据
如果MPI决定不缓存将要发送的数据:对于阻塞通信,则要求接受操作执行,并且数据都发送到接受缓冲区了,发送操作才能够返回;对于非阻塞通信,发送操作虽然没有完成,但是发送调用可以正确返回。
2.缓存通信模式
与标准通信的区别在于需要自己维护程序的缓冲区。
int MPI_Buffer_attach(void *buffer, int size)用于申请缓存
int MPI_Buffer_detach(void **buffer, int *size) 用于释放缓存 这是一个阻塞调用 函数返回表示缓冲区已经被释放
示例代码如下:
1 #include "mpi.h"
2 #include <stdio.h>
3 #include <stdlib.h>
4 #define SIZE 6
5 static int src = 0;
6 static int dest = 1;
7
8 void generate_data(double *, int);
9 void normal_recv(double *, int);
10 void buffered_send(double *, int);
11
12 void generate_data(double *buffer, int buff_size){
13 int i;
14 for (i=0; i<buff_size; i++) buffer[i]=(double)i+1;
15 }
16
17 void normal_recv(double *buffer, int buff_size){
18 int i,j;
19 MPI_Status status;
20 double *b;
21
22 b = buffer;
23
24 MPI_Recv(b,(buff_size-1),MPI_DOUBLE,src,2000,MPI_COMM_WORLD, &status);
25 fprintf(stderr, "standard receive a message of %d data\n", buff_size-1);
26 for(j=0; j<buff_size-1; j++) fprintf(stderr, "buf[%d]=%f\n",j,b[j]);
27
28 b+=buff_size-1;
29 MPI_Recv(b, 1, MPI_DOUBLE, src, 2000, MPI_COMM_WORLD, &status);
30 fprintf(stderr, "standard receive a message of one data\n");
31 fprintf(stderr, "buf[0]=%f\n",*b);
32 }
33
34 void buffered_send(double *buffer, int buff_size){
35 int i,j;
36 void *bbuffer;
37 int size;
38
39 fprintf(stderr, "buffered send message of %d data\n", buff_size-1);
40 for(j=0; j<buff_size-1; j++) fprintf(stderr, "buf[%d]=%f\n",j,buffer[j]);
41 MPI_Bsend(buffer, (buff_size-1), MPI_DOUBLE, dest, 2000, MPI_COMM_WORLD);
42
43 buffer+=buff_size-1;
44 fprintf(stderr, "bufferred send message of one data\n");
45 fprintf(stderr, "buf[0]=%f\n", *buffer);
46 MPI_Bsend(buffer, 1, MPI_DOUBLE, dest, 2000, MPI_COMM_WORLD);
47
48 MPI_Buffer_detach(&buffer, &size);
49 MPI_Buffer_attach(bbuffer, size);
50 }
51
52 int main(int argc, char *argv[])
53 {
54 int rank;
55 double buffer[SIZE], *tmpbuffer, *tmpbuf;
56 int tsize, bsize;
57 char *test = NULL;
58
59 MPI_Init(&argc, &argv);
60 MPI_Comm_rank(MPI_COMM_WORLD, &rank);
61
62 if (rank==src) { // 发送消息进程
63 generate_data(buffer, SIZE);
64 MPI_Pack_size(SIZE, MPI_DOUBLE, MPI_COMM_WORLD, &bsize);
65 tmpbuffer = (double*)malloc(bsize+2*MPI_BSEND_OVERHEAD);
66 if (!tmpbuffer) {
67 MPI_Abort(MPI_COMM_WORLD, 1);
68 }
69 // 告诉系统MPI_Bsend用到buffer就去tmpbuffer那里去找
70 MPI_Buffer_attach(tmpbuffer, bsize+2*MPI_BSEND_OVERHEAD);
71 buffered_send(buffer, SIZE);
72 MPI_Buffer_detach(&tmpbuf, &tsize);
73 printf("tsize detach from tmpbuf is : %d\n", tsize);
74 }
75 else if (rank==dest) {
76 normal_recv(buffer, SIZE);
77 }
78 else {
79 MPI_Abort(MPI_COMM_WORLD, 1);
80 }
81 MPI_Finalize();
82 }
代码输出结果是:
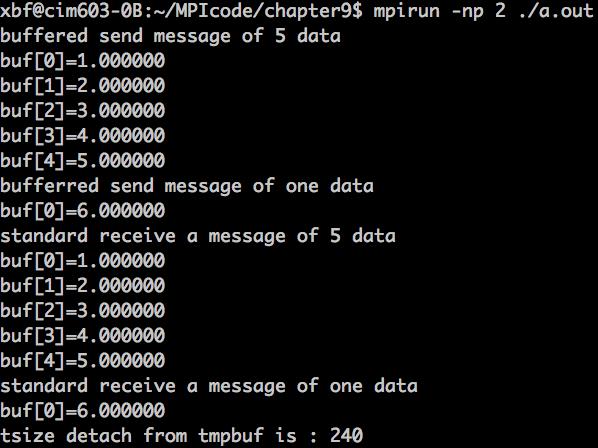
总共需要发送5个double类型,每个类型占8个字节;MPI通信其他附属信息占200个字节;因此总共缓冲区的大小的240个字节。
3.同步通信模式
同步发送进程的特点是:发送操作可以不依赖接受进程的相应接受操作是否已经启动,但是必须等着接受操作开始执行后才能返回;这意味着一旦同步发送返回后,发送缓冲区中的数据已经全部被系统缓冲区缓存。“发送缓冲区”表示MPI的缓冲区,“系统缓冲区”指的是操作系统的写缓冲区,注意二者的区别。这意味着同步发送缓冲区中的数据可以被释放或重新利用。
示例代码如下:
1 #include "mpi.h"
2 #include <stdio.h>
3
4 #define SIZE 10
5
6 static int src = 0;
7 static int dest = 1;
8
9 int main(int argc, char *argv[])
10 {
11 int rank;
12 int act_size = 0;
13 int flag, np, rval, i;
14 int buffer[SIZE];
15 MPI_Status status, status1, status2;
16 int count1, count2;
17 MPI_Init(&argc, &argv);
18 MPI_Comm_rank(MPI_COMM_WORLD, &rank);
19 MPI_Comm_size(MPI_COMM_WORLD, &np);
20
21 if (np!=2) {
22 MPI_Abort(MPI_COMM_WORLD, 1);
23 }
24 act_size = 5; /*最大消息长度*/
25 if (rank==src) {
26 MPI_Ssend(buffer, act_size, MPI_INT, dest, 1, MPI_COMM_WORLD);
27 fprintf(stderr, "MPI_Ssend %d data,tag=1\n", act_size);
28 act_size = 4;
29 MPI_Ssend(buffer, act_size, MPI_INT, dest, 2, MPI_COMM_WORLD);
30 fprintf(stderr, "MPI_Ssend %d data,tag=2\n", act_size);
31 }
32 else if (rank=dest) {
33 MPI_Recv(buffer, act_size, MPI_INT, src, 1, MPI_COMM_WORLD, &status1);
34 MPI_Recv(buffer, act_size, MPI_INT, src, 2, MPI_COMM_WORLD, &status2);
35 MPI_Get_count(&status1, MPI_INT, &count1);
36 fprintf(stderr, "receive %d data,tag=%d\n",count1, status1.MPI_TAG);
37 MPI_Get_count(&status2, MPI_INT, &count2);
38 fprintf(stderr, "receive %d data,tag=%d\n",count2, status2.MPI_TAG);
39 }
40 MPI_Finalize();
41 }
代码执行结果如下:
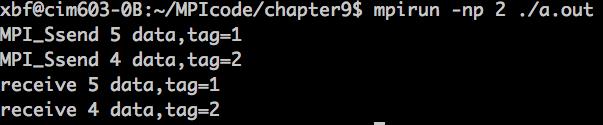
如果将33 34行代码互换位置,则程序陷入了deadlock:一方面发送进程中tag=1的MPI_Ssend操作一直处于阻塞状态;另一方面接受进程中的tag=2的MPI_Recv操作处于阻塞状态;两个进程互相等着对方,陷入了死锁。
4. 就绪通信模式
与前几种通信模式不同,只有当接受进程的接受操作已经启动时,才可以在发送端启动发送进程。
一种可能的就绪通信模式实现方法如下图:

上图保证的目标是①要先于④执行;方法是插入②和③;①一定先于②执行,③一定等②成功后才能执行,③成功后④才能执行。
由此一定保证①先于④执行,就保证了就绪通信。
示例代码如下:
1 #include "mpi.h"
2 #include <stdio.h>
3 #include <stdlib.h>
4
5 #define TEST_SIZE 2000
6
7 void test_rsend();
8
9 int main(int argc, char *argv[])
10 {
11 MPI_Init(&argc, &argv);
12 test_rsend();
13 MPI_Finalize();
14 }
15
16 void test_rsend()
17 {
18 int rank, size;
19 int next, prev;
20 int tag;
21 int count;
22 float send_buf[TEST_SIZE], recv_buf[TEST_SIZE];
23 MPI_Status status;
24 MPI_Request request;
25
26 MPI_Comm_rank(MPI_COMM_WORLD, &rank);
27 MPI_Comm_size(MPI_COMM_WORLD, &size);
28
29 if (2!=size) {
30 MPI_Abort(MPI_COMM_WORLD, 1);
31 }
32 next = rank + 1;
33 if (next >= size) next = 0;
34 prev = rank - 1;
35 if (prev <0) prev = size-1;
36
37 if (0==rank) {
38 fprintf(stderr, " Rsend Test\n");
39 }
40 tag = 1456;
41 count = TEST_SIZE/3;
42 if (0==rank) {
43 MPI_Recv(MPI_BOTTOM,0,MPI_INT,next,tag,MPI_COMM_WORLD, &status);
44 fprintf(stderr, " Process %d post Ready send\n", rank);
45 MPI_Rsend(send_buf,count,MPI_FLOAT,next,tag,MPI_COMM_WORLD);
46 }
47 else {
48 fprintf(stderr, " process %d post a receive call\n", rank);
49 MPI_Irecv(recv_buf, TEST_SIZE, MPI_FLOAT,MPI_ANY_SOURCE,MPI_ANY_TAG,MPI_COMM_WORLD,&request);
50 MPI_Send(MPI_BOTTOM,0,MPI_INT,next,tag,MPI_COMM_WORLD);
51 MPI_Wait(&request, &status);
52 fprintf(stderr, " Process %d Receive Rsend message from %d\n",rank, status.MPI_SOURCE);
53 }
54 }
代码执行结果如下:
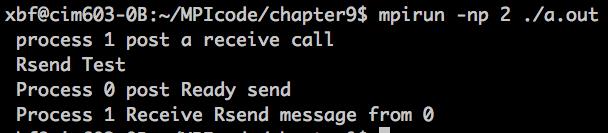
以上是关于MPI学习3MPI并行程序设计模式:不同通信模式MPI并行程序的设计的主要内容,如果未能解决你的问题,请参考以下文章