MPI学习6MPI并行程序设计模式:具有不连续数据发送的MPI程序设计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MPI学习6MPI并行程序设计模式:具有不连续数据发送的MPI程序设计相关的知识,希望对你有一定的参考价值。
基于都志辉老师《MPI并行程序设计模式》第14章内容。
前面接触到的MPI发送的数据类型都是连续型的数据。非连续类型的数据,MPI也可以发送,但是需要预先处理,大概有两类方法:
(1)用户自定义新的数据类型,又称派生类型(类似定义结构体类型,但是比结构体复杂,需要考虑<类型,偏移量>两方面的内容)
(2)数据的打包和解包(将不连续的数据给压缩打包到连续的区域,然后再发送;接受到打包数据后,先解包再使用)
这样做的好处,我猜一个是可以有效减少通信的次数,提高程序效率;另一方面可以减轻程序员设计程序的负担,降低维护成本。
下面记录学习中的一些注意的点:
1. 通用的数据类型描述方法——类型图。MPI自定义派生类型的变量,往往由一些不同类型(MPI_INT, MPI_FLOAT, MPI_DOUBLE等)的变量按一定组织形式(每个变量偏移量是多少)组合。因此,引入类型图来形象描述MPI的派生变量是由那些不同的基础类型,按照怎么样的偏移量组合在一起的。
类型图 = {<基类型0,偏移0>,<基类型0,偏移0>,...,<基类型0,偏移0>}
先看书理解好什么是类型图,为什么要有类型图,学习MPI派生类型就顺畅一些。
另外,与结构体类似,MPI派生的数据类型,需要考虑内存对齐的因素:不同基变量的偏移量设计是有内存对齐讲究的。具体有什么讲究,为什么要有讲究,可以复习之前的学习blog(http://www.cnblogs.com/xbf9xbf/p/5121748.html)
2. 几种常见的新类型数据的定义方法
可以直接看书上给的实际例子,看例子就懂了什么意思了。在看例子的时候,注意一下偏移量与内存对齐的关系就可以了。
另外,在定义好新类型之后,还需要在MPI中注册新定义好的数据类型。
直接看下面这个综合的例子。
代码实现的内容是测试MPI用不同的方式发送非连续数据的传输效率。其中用到了几种新类型数据的定义方法。
1 #include "mpi.h"
2 #include <stdio.h>
3 #include <stdlib.h>
4
5 #define NUMBER_OF_TEST 10
6
7 int main(int argc, char *argv[])
8 {
9 MPI_Datatype vec1, vec_n;
10 int blocklens[2];
11 MPI_Aint indices[2]; // A=array
12 MPI_Datatype old_types[2];
13 double *buf, *lbuf;
14 register double *in_p, *out_p;
15 int rank;
16 int n, stride;
17 double t1, t2, tmin;
18 int i,j,k,nloop;
19 MPI_Status status;
20
21 MPI_Init(&argc, &argv);
22 MPI_Comm_rank(MPI_COMM_WORLD, &rank);
23 n = 1000;
24 stride = 24;
25 nloop = 100000/n;
26 buf = (double*)malloc(n*stride*sizeof(double));
27 if (!buf) MPI_Abort(MPI_COMM_WORLD,1);
28 lbuf = (double*)malloc(n*sizeof(double));
29 if (!lbuf) MPI_Abort(MPI_COMM_WORLD,1);
30 if (0==rank) printf("Kind\\tn\\tstride\\ttime(sec)\\tRate(MB/sec)\\n");
31 // 1. Vector数据传输测试: Vector是大结构 里面包含n个vec1结构
32 // 构造一个double vector
33 MPI_Type_vector(n, 1, stride, MPI_DOUBLE, &vec1);
34 MPI_Type_commit(&vec1);
35 if (0==rank) {
36 MPI_Aint ext[1];
37 MPI_Type_extent(vec1, ext);
38 printf("extent of vec1 : %d\\n",(int)(*ext));
39 MPI_Type_extent(MPI_DOUBLE, ext);
40 printf("exten of MPI_DOUBLE : %d\\n",(int)(*ext));
41 }
42 tmin = 1000;
43 for (k=0; k<NUMBER_OF_TEST; k++) {
44 if (0==rank) {
45 // 保证通信双方都ready
46 MPI_Sendrecv(MPI_BOTTOM, 0, MPI_INT, 1, 14, MPI_BOTTOM, 0, MPI_INT, 1, 14, MPI_COMM_WORLD, &status);
47 t1 = MPI_Wtime();
48 for (j=0; j<nloop; j++) {
49 MPI_Send(buf, 1, vec1, 1, k, MPI_COMM_WORLD);
50 MPI_Recv(buf, 1, vec1, 1, k, MPI_COMM_WORLD, &status);
51 }
52 t2 = (MPI_Wtime()-t1) / nloop;
53 tmin = tmin>t2 ? t2 : tmin;
54 }
55 else if (1==rank) {
56 // 保证通信双方都ready
57 MPI_Sendrecv(MPI_BOTTOM, 0, MPI_INT, 0, 14, MPI_BOTTOM, 0, MPI_INT, 0, 14, MPI_COMM_WORLD, &status);
58 for (j=0; j<nloop; j++) {
59 MPI_Recv(buf, 1, vec1, 0, k, MPI_COMM_WORLD, &status);
60 MPI_Send(buf, 1, vec1, 0, k, MPI_COMM_WORLD);
61 }
62 }
63 }
64 tmin = tmin / 2;
65 if (0==rank) printf("Vector\\t%d\\t%d\\t%f\\t%f\\n",n,stride,tmin,n*sizeof(double)*1.0e-6/tmin);
66 MPI_Type_free(&vec1);
67 // 2. 可变向量类型传输测试: Struct是小结构 每个struct由vec_n构成
68 blocklens[0] = 1;
69 blocklens[1] = 1;
70 indices[0] = 0;
71 indices[1] = stride*sizeof(double);
72 old_types[0] = MPI_DOUBLE;
73 old_types[1] = MPI_UB; // 上限区间占位符 不占大小 只占位置
74 MPI_Type_struct(2, blocklens, indices, old_types, &vec_n);
75 MPI_Type_commit(&vec_n);
76 if (0==rank) {
77 MPI_Aint ext[1];
78 MPI_Type_extent(vec_n, ext);
79 printf("extent of vec_n : %d\\n",(int)(*ext));
80 }
81 tmin = 1000;
82 for (k=0; k<NUMBER_OF_TEST; k++) {
83 if (0==rank) {
84 MPI_Sendrecv(MPI_BOTTOM, 0, MPI_INT, 1, 14, MPI_BOTTOM, 0, MPI_INT, 1, 14, MPI_COMM_WORLD, &status);
85 t1 = MPI_Wtime();
86 for (j=0; j<nloop; j++) {
87 MPI_Send(buf, n, vec_n, 1, k, MPI_COMM_WORLD);
88 MPI_Recv(buf, n, vec_n, 1, k, MPI_COMM_WORLD, &status);
89 }
90 t2 = (MPI_Wtime()-t1) / nloop;
91 tmin = tmin>t2 ? t2 : tmin;
92 }
93 else if (1==rank) {
94 MPI_Sendrecv(MPI_BOTTOM, 0, MPI_INT, 0, 14, MPI_BOTTOM, 0, MPI_INT, 0, 14, MPI_COMM_WORLD, &status);
95 for (j=0; j<nloop; j++) {
96 MPI_Recv(buf, n, vec_n, 0, k, MPI_COMM_WORLD, &status);
97 MPI_Send(buf, n, vec_n, 0, k, MPI_COMM_WORLD);
98 }
99 }
100 }
101 tmin = tmin / 2;
102 if (0==rank) printf("Struct\\t%d\\t%d\\t%f\\t%f\\n",n,stride,tmin,n*sizeof(double)*1.0e-6/tmin);
103 MPI_Type_free(&vec_n);
104 // 3.User
105 tmin = 1000;
106 for (k=0; k<NUMBER_OF_TEST; k++) {
107 if (0==rank) {
108 MPI_Sendrecv(MPI_BOTTOM, 0, MPI_INT, 1, 14, MPI_BOTTOM, 0, MPI_INT, 1, 14, MPI_COMM_WORLD, &status);
109 t1 = MPI_Wtime();
110 for(j=0; j<nloop; j++)
111 {
112 for (i=0; i<n; i++) {
113 lbuf[i] = buf[i*stride];
114 }
115 MPI_Send(lbuf, n, MPI_DOUBLE, 1, k, MPI_COMM_WORLD);
116 MPI_Recv(lbuf, n, MPI_DOUBLE, 1, k, MPI_COMM_WORLD, &status);
117 for (i=0; i<n; i++) {
118 buf[i*stride] = lbuf[i];
119 }
120 }
121 t2 = (MPI_Wtime()-t1) / nloop;
122 tmin = tmin>t2 ? t2 : tmin;
123 }
124 else if (1==rank) {
125 MPI_Sendrecv(MPI_BOTTOM, 0, MPI_INT, 0, 14, MPI_BOTTOM, 0, MPI_INT, 0, 14, MPI_COMM_WORLD, &status);
126 for (j=0; j<nloop; j++) {
127 MPI_Recv(lbuf, n, MPI_DOUBLE, 0, k, MPI_COMM_WORLD, &status);
128 for (i=0; i<n; i++) {
129 buf[i*stride] = lbuf[i];
130 }
131 for (i=0; i<n; i++) {
132 lbuf[i] = buf[i*stride];
133 }
134 MPI_Send(lbuf, n, MPI_DOUBLE, 0, k, MPI_COMM_WORLD);
135 }
136 }
137 }
138 tmin = tmin / 2.0;
139 if (0==rank) printf("User(1)\\t%d\\t%d\\t%f\\t%f\\n",n,stride,tmin,n*sizeof(double)*1.0e-6/tmin);
140 // 4. user-packing
141 tmin = 1000;
142 for (k=0; k<NUMBER_OF_TEST; k++) {
143 if (0==rank) {
144 MPI_Sendrecv(MPI_BOTTOM, 0, MPI_INT, 1, 14, MPI_BOTTOM, 0, MPI_INT, 1, 14, MPI_COMM_WORLD, &status);
145 t1 = MPI_Wtime();
146 for(j=0; j<nloop; j++){
147 in_p = buf;
148 out_p = lbuf;
149 for(i=0; i<n; i++){
150 out_p[i] = *in_p;
151 in_p += stride;
152 }
153 MPI_Send(lbuf, n, MPI_DOUBLE, 1, k, MPI_COMM_WORLD);
154 MPI_Recv(lbuf, n, MPI_DOUBLE, 1, k, MPI_COMM_WORLD, &status);
155 out_p = buf;
156 in_p = lbuf;
157 for (i=0; i<n; i++) {
158 *out_p = in_p[i];
159 out_p += stride;
160 }
161 }
162 t2 = (MPI_Wtime()-t1) / nloop;
163 tmin = tmin>t2 ? t2 : tmin;
164 }
165 else if (1==rank) {
166 MPI_Sendrecv(MPI_BOTTOM, 0, MPI_INT, 0, 14, MPI_BOTTOM, 0, MPI_INT, 0, 14, MPI_COMM_WORLD, &status);
167 for(j=0; j<nloop; j++)
168 {
169 MPI_Recv(lbuf, n, MPI_DOUBLE, 0, k, MPI_COMM_WORLD, &status);
170 in_p = lbuf;
171 out_p = buf;
172 for (i=0; i<n; i++) {
173 *out_p = in_p[i];
174 out_p += stride;
175 }
176 out_p = lbuf;
177 in_p = buf;
178 for (i=0; i<n; i++) {
179 out_p[i] = *in_p;
180 in_p += stride;
181 }
182 MPI_Send(lbuf, n, MPI_DOUBLE, 0, k, MPI_COMM_WORLD);
183 }
184 }
185 }
186 tmin = tmin / 2;
187 if (0==rank) printf("User(2)\\t%d\\t%d\\t%f\\t%f\\n",n,stride,tmin,n*sizeof(double)*1.0e-6/tmin);
188 MPI_Finalize();
189 }
代码执行结果如下:
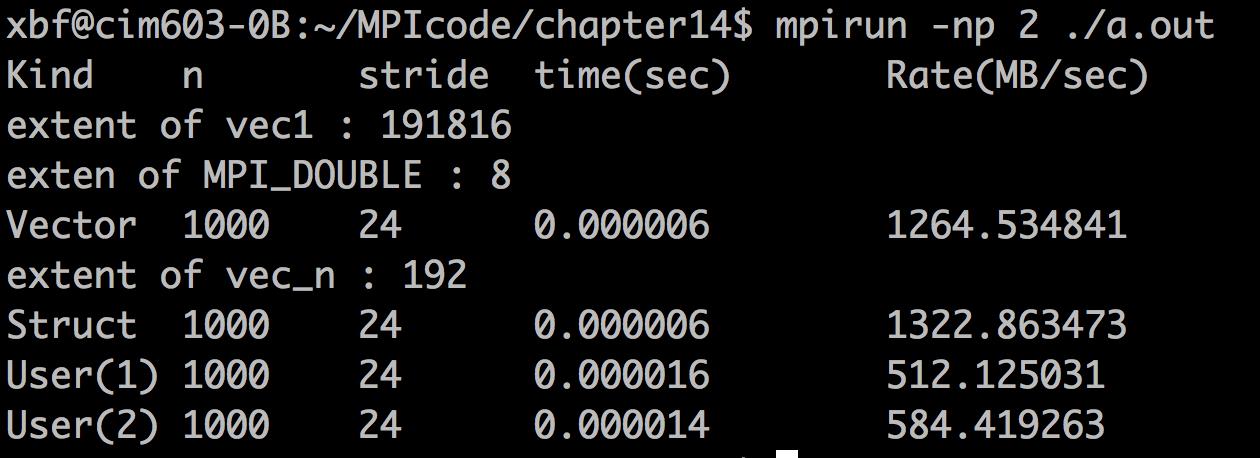
结果分析;
(1)传输效率。可以看到前面vector和struct两种MPI提供的派生数据的方式(利用MPI_Type_vector和MPI_Type_struct),是要由于后面用户自己派生数据的方式的(程序员自己自己将1000个double数据放到一个buf中再发送)。
(2)extent的算法。每个MPI的派生类型变量,都有一个extent的概念。这里的extent就是考虑了内存对齐后的派生类型的新变量跨度大小。这里以MPI_Type_vector(1000, 1, 24, MPI_DOUBLE, &vec1)为例,为什么vec1的extent是191816。
具体算法如下:vec1的基础类型是MPI_DOUBLE,每个MPI_DOUBLE占8个字节;每个变量段的便宜量是24个MPI_DOUBLE(即,第1个double+23个double占位+第2个double+23个double占位,....);这样重复999次,直到1000次的时候,最后一个double设定之后,后面就没有下一个doulbe了,因此也没有23个doulbe空间占位了(注意在算extent的时候不要把最后的23个double空间占位给算进去)。extent = 1000*24*8 - 23*8 = 191816
3.构造新数据类型时,计算地址偏移量的函数。
前面提到过,构造MPI派生类型时候,需要程序员指定每个变量相对于派生类型的入口地址(MPI_BOTTOM)偏移量是多少。前面的例子是通过人工设定的需要多少偏移量,MPI提供了一个函数MPI_Address(void *location, MPI_Aint *address)来帮我们解决这个问题。另外,还有个MPI_Type_size函数用来统计MPI派生变量中有用内容的大小,MPI_Type_extent函数测试MPI派生变量的跨度大小,下面的例子中也对这两个函数加以区分。
看如下的例子:
1 #include "mpi.h"
2 #include <stdio.h>
3 #include <stdlib.h>
4
5 int main(int argc, char *argv[])
6 {
7 int rank;
8 struct{
9 int a;
10 double b;
11 } value;
12 MPI_Datatype mystruct;
13 int blocklens[2];
14 MPI_Aint indices[2];
15 MPI_Datatype old_types[2];
16
17 MPI_Init(&argc, &argv);
18 MPI_Comm_rank(MPI_COMM_WORLD, &rank);
19 blocklens[0] = 1;
20 blocklens[1] = 1;
21 old_types[0] = MPI_INT;
22 old_types[1] = MPI_DOUBLE;
23 MPI_Address(&value.a, &indices[0]);
24 MPI_Address(&value.b, &indices[1]);
25 indices[1] = indices[1]-indices[0];
26 indices[0] = 0;
27 MPI_Type_struct(2, blocklens, indices, old_types, &mystruct);
28 MPI_Type_commit(&mystruct);
29 MPI_Aint extent[1];
30 MPI_Type_extent(mystruct, extent);
31 int size;
32 MPI_Type_size(mystruct, &size);
33 if (0==rank) {
34 printf("stride:%d\\n",(int)indices[1]);
35 printf("extent:%d\\n",(int)*extent);
36 printf("size of struct:%d\\n",(int)sizeof(value));
37 printf("size of mystruct:%d\\n", size);
38 }
39
40 while (value.a>=0) {
41 if (0==rank) {
42 scanf("%d %lf",&value.a,&value.b);
43 }
44 MPI_Bcast(&value, 1, mystruct, 0, MPI_COMM_WORLD);
45 printf("Process %d got %d and %lf\\n",rank,value.a,value.b);
46 }
47 MPI_Type_free(&mystruct);
48 MPI_Finalize();
49 }
代码执行结果如下:
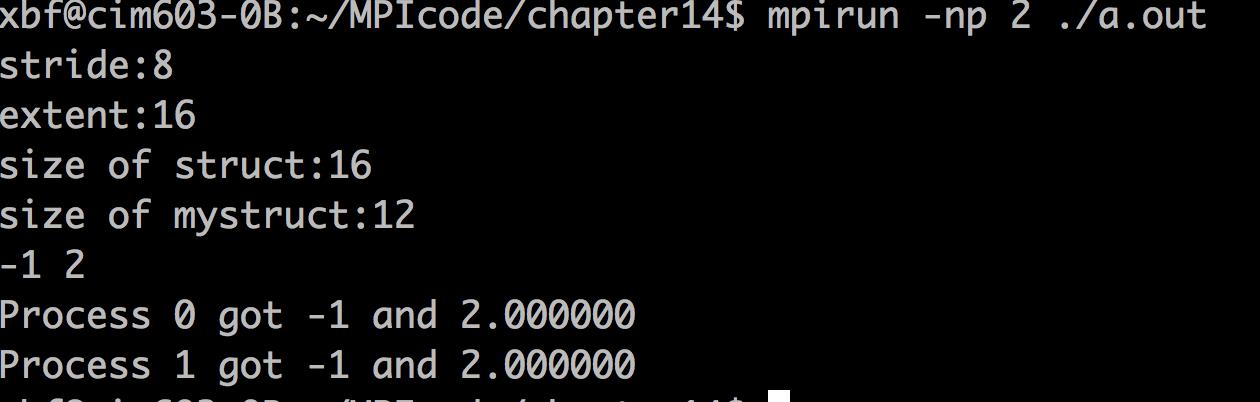
分析如下:
(1)line23~25,就是用MPI_Address来计算派生类型中各个基础类型变量起始位置的绝对偏移量(间接通过一个{int, double}结构体类型作为标靶,来找到MPI目标派生类型各个基变量的偏移量的)
(2)定义的结构体value中虽然只有一个int和double,但是考虑内存对齐(double大小8的整数倍),所以size是16。
(3)同理,MPI派生类型mystruct经过内存对齐要求后,extent也是16。
(4)MPI_Type_size只要求有效数据大小,因此是int+double加一起是12个bytes。
4. 打包与解包
打包与解包并不是构造新的MPI数据类型,而是将不同类型的数据利用打包函数压缩到连续的发送缓冲区中;再通过解包函数,按照解包的规则,从接受缓冲区中将数据解包,进而后续使用。
打包函数和解包函数:
MPI_Pack(void *inbuf, int incount, MPI_datatype, void *outbuf, int outcount, int *position, MPI_Comm comm)
MPI_Unpack(void *inbuf, int insize, int *position, void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm)
打包后发送时的数据类型:
经过打包后的数据,也是存放在一个缓冲区中;此时再用MPI_Send函数发送时,需要指定发送类型为MPI_PACKED。
打包和解包在MPI通信中的位置:
a. 给定发送缓冲区、给定接受缓冲区
b. 将数据打包到发送缓冲区中(一个数据一个数据打包)
c. 将打包后的数据发送到目标进程
d. 将数据从目标进程的接收缓冲区中解包(一个数据一个数据解包,解包的顺序与打包的顺序相同)
可以看到,打包和解包在通信过程外围一层,是服务于MPI通信的(这里的通信可以是Send Recv也可以是Bcast这种广播模式)
下面看一个代码例子,root进程将一个整数和双精度数打包,然后广播给所有的进程,各进程分别将数据解包后再打印。
1 #include "mpi.h"
2 #include <stdio.h>
3 #include <stdlib.h>
4
5 int main(int argc, char *argv[])
6 {
7 int rank;
8 int packsize, position;
9 int a;
10 double b;
11 char packbuf[100];
12
13 MPI_Init(&argc, &argv);
14 MPI_Comm_rank(MPI_COMM_WORLD, &rank);
15 while (a>=0) {
16 if (0==rank) { // 在进程0中准备发送的数据
17 scanf("%d %lf",&a,&b);
18 packsize = 0;
19 MPI_Pack(&a, 1, MPI_INT, packbuf, 100, &packsize, MPI_COMM_WORLD);
20 MPI_Pack(&b, 1, MPI_DOUBLE, packbuf, 100, &packsize, MPI_COMM_WORLD);
21 }
22 MPI_Bcast(&packsize, 1, MPI_INT, 0, MPI_COMM_WORLD);
23 MPI_Bcast(packbuf, packsize, MPI_PACKED, 0, MPI_COMM_WORLD);
24 if (0!=rank) { // 在进程1中处理进程0发送来的打包数据
25 position = 0;
26 MPI_Unpack(packbuf, packsize, &position, &a, 1, MPI_INT, MPI_COMM_WORLD);
27 MPI_Unpack(packbuf, packsize, &position, &b, 1, MPI_DOUBLE, MPI_COMM_WORLD);
28 }
29 printf("Process %d got %d and %lf\\n", rank, a, b);
30 }
31 MPI_Finalize();
32 return 0;
33 }
执行结果如下:
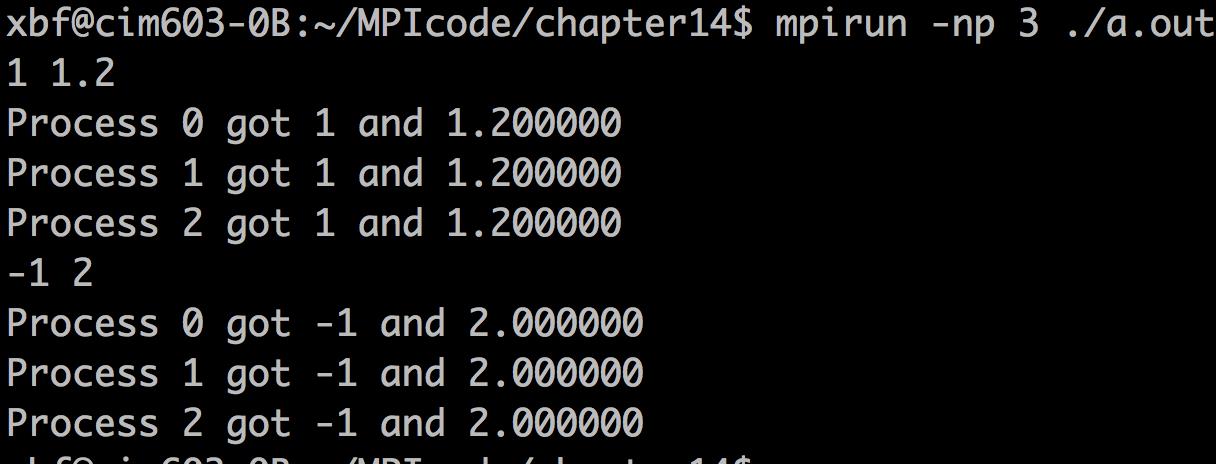
总结一下,如果MPI不提供(1)自定义派生数据类型(2)打包和解包 两种非连续的数据发送方法,则发送非连续的组合数据,需要程序员写非常多的Send Recv通信对来完成,既降低了通信的效率,又增加了程序维护的成本。以后遇到类似的问题时候,可以回顾MPI这块的知识。
以上是关于MPI学习6MPI并行程序设计模式:具有不连续数据发送的MPI程序设计的主要内容,如果未能解决你的问题,请参考以下文章