ElasticSearch中index的设计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch中index的设计相关的知识,希望对你有一定的参考价值。
参考技术A 场景:需要将40G数据从mysql迁移到es,数据内容按照产品、语言进行分类,项目和语言都会不断的新增。使用方式:同一产品多语言查询、跨产品查询关键信息、同一语言查询关键字等。
如何拆分主要从容量、速度、查询、入库、后续扩展、准确性等维度进行考虑。
es在按照index存储数据时,默认采用的是5个分片(官方推荐分片数=1.5~3倍的节点数),每个分片不存储超过30G数据(es推荐的最大JVM空间)。
我们目前大概拥有40G数据,即使不做拆分,5个分片容量足够用很长时间,如果不够的话,可以动态进行扩容,新建其他index解决(如按照时间划分,每年存一个index)。
如果拆分的话,一般es一次查询最多不能超过1000个分片(不建议更改),若按照产品与语言划分,他们的总数不能超过200种(即200个index)。
es的查询过程为先找到指定的index对应的所有分片,并发对每个分片请求并获得结果,最终在请求节点对每个分片的结果进行合并。
针对目前的es集群状态,即:一个8g16核的节点和一个1g1核的节点
a) 全语言查询
如果按照语言划分的话(假定30种),每次需要对150个分片的结果并发查询,然后统一进行合并,
不划分的话,每次对5个分片的结果进行查询并合并。
理论上,只要cpu负荷和内存未告警的话,由于各个分片上的查询结果是并发的,拆分查询速度更快。
b)指定语言或产品查询
拆分index可以减少查询的分片总数,提高查询效率。
es查询条件包括两个部分:head和body
body部分主要是针对具体的条件进行过滤,和index拆分没有关系。
head部分需要指定相应的index,因此,如果对index按照语言或者产品进行过滤时,查询效率更高,只是在生成index时,按照一定规则生成即可。
拆分的话,需要根据记录信息分别生成index,简单的按产品或语言拆分几乎没有影响。
不管拆分与否,新增节点都能提高搜索性能
主分片对不同分片评分结果汇总,是根据每条记录中词条的出现频率和权重进行计算,即限定在document层面,和分片无关,因此拆分与否,不影响查询结果的准确性
如果单个index在查询时,可以控制在1s之内,则不拆分更简单。
如果单index查询较慢,拆分在查询单产品或语言时会提高查询速度,如果产品可能越来越多,全品类查询时,可能会超过1000分片,建议按照语言进行分类。
Elasticsearch最佳实践之Index与Shard设计
Index与Shard,这两个概念在《Elasticsearch最佳实践之核心概念与原理》一文有详细的介绍,分别对应了Elasticsearch的两种数据组织方式:逻辑组织和物理组织。逻辑层面上,Index与业务数据的结构、类型、使用方式等息息相关;而物理层面上,Shard关系到数据在不同机器上的分布情况。作为专栏的第三篇,本文主要探讨实际应用中Index与Shard的设计方法。所谓设计,即通过合理组合Elasticsearch的特性与功能来完成业务需求,尽可能实现业务的灵活性,保证系统的高性能与稳定性。当然,前提是得先知晓这些特性与功能以及何时使用。本文将从以下几个方面进行介绍,写作背景是Elasticsearch 5.5。(文中使用的一些示例和图片来自于笔者在2018年Elasticsearch南京Meetup中的幻灯片。)
- 基于时间的Index设计
- Mapping设计技巧
- 巧妙的Alias
- Shard分配原则
- 整体思路
1. 基于时间的Index设计
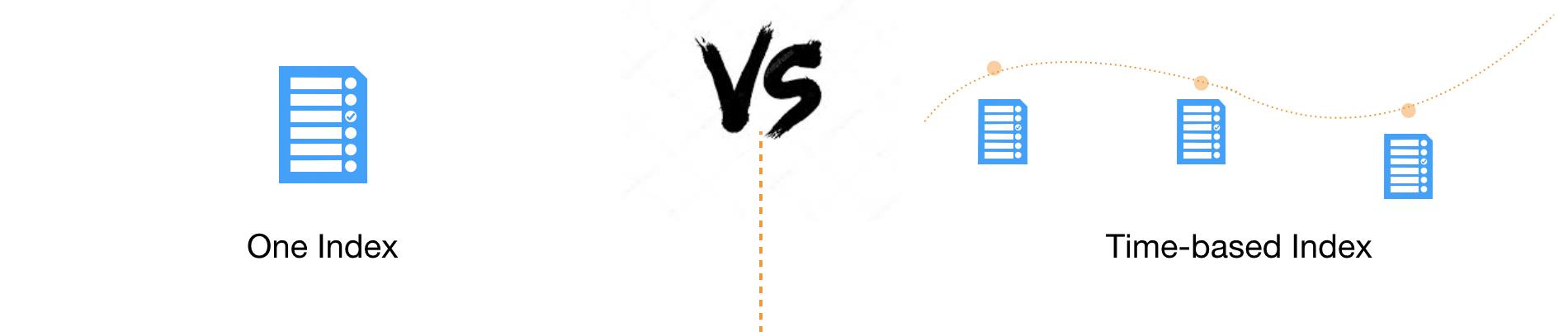
Index设计时要考虑的第一件事,就是基于时间对Index进行分割,即每隔一段时间产生一个新的Index。为什么要这样做呢?因为现实世界的数据是随着时间的变化而不断产生的,切分管理可以获得足够的灵活性和更好的性能。
- 如果数据都存储在一个Index中,很难进行扩展和调整,因为Elasticsearch中Index的某些设置在创建时就设定好了,是不能更改的,比如Primary Shard的个数。而根据时间来切分Index,则可以实现一定的灵活性,既可以在数据量过大时及时调整Shard个数,也可以及时响应新的业务需求。
- 大多数业务场景下,客户对数据的请求都会命中在最近一段时间上,通过切分Index,可以尽可能的避免扫描不必要的数据,提高性能。
当然,并不排除某些特定的业务场景下,不用对Index进行切分管理,比如一个固定的数据集或者一个增长非常缓慢的数据集。大多数情况下,笔者都建议按照时间进行分割。那么,要考虑的第二件事就是,按照什么规则来设定切分的间隔呢?根据上面的分析,自然是时间越短越能保持灵活性,但是这样做就会导致产生大量的Index,而每个Index都会消耗资源来维护其元信息的,因此需要在灵活性、资源和性能上做权衡。建议按照如下几点来思考:
- 常见的间隔有小时、天、周和月。先考虑总共要存储多久的数据,然后选一个既不会产生大量Index又能够满足一定灵活性的间隔。比如,你需要存储6个月的数据,那么一开始选择“周”这个间隔就会比较合适。
- 考虑业务增长速度。假如业务增长的特别快,比如上周产生了1亿数据,这周就增长到了10亿,那么就需要调低这个间隔来保证有足够的弹性能应对变化。
- 结合业务特性和性能测试来决定要不要调整间隔。这点更多的是从业务角度来考虑的,举个例子,在笔者的一个项目中,一开始选择了“周”作为间隔,一周产生一个新的Index来存储实时的分钟级数据,但是每周会将历史数据合并成小时级数据来降低数据量、提高查询速度。在性能测试中发现,合并后的查询性能相比合并前提升特别大,因此我们将整体间隔调整到“天”来缩短合并的周期。(后面会另撰文章更详细的分享这个案例)
接下来就是第三件事,如何实现Index的分割?切分行为是由客户端(数据的写入端)发起的,根据时间间隔与数据产生时间将数据写入不同的Index中,为了易于区分,会在Index的名字中加上对应的时间标识。创建新Index这件事,可以是客户端主动发起一个创建的请求,带上具体的Settings、Mappings等信息,但是可能会有一个时间错位,即有新数据写入时新的Index还没有建好。Elasticsearch提供了更优雅的方式来实现这个动作,即Index Template。
Index Template提供的功能是:先设置一个Template,定义好具体的Settings、Mappings等信息,当有数据需要写入新的Index时,就会根据Template内容自动创建Index。是否根据Template建立新的Index受三点因素制约:
- 是否是新的Index;
- Index的名字是否与template参数中定义的格式相匹配;
- 如果有多个Template匹配上了,则根据order参数的大小来依次生效,即从小到大逐步更新相应的配置信息(相同的配置信息会被覆盖)。
下面给出了一个具体的Index Template定义,来自于笔者项目中的真实定义(去掉了部分字段信息),该Template会匹配所有前缀为“ce-index-access-v1-”的Index,这个示例会被上下多个小节引用。
"facet_internet_access_minute":
"template": "ce-index-access-v1-*",
"order": 0,
"settings":
"number_of_shards": 5
,
"aliases":
"index-query":
,
"mappings":
"es_doc":
"dynamic": "strict",
"_all":
"enabled": false
,
"_source":
"enabled": false
,
"properties":
"CLF_Timestamp":
"type": "long"
,
"CLF_CustomerID":
"type": "keyword"
,
"CLF_ClientIP":
"type": "ip",
"ignore_malformed": true
2. Mapping设计技巧
Index设计的第四件事,是结合业务需求来设定Mapping信息。如在专栏的第二篇中所述,Mapping定义了具体的数据结构与相关的元信息,合适的设置可以有效提高性能、节省磁盘空间。Mapping的设计,主要考虑两方面内容:
- Schema设计。第一,尽管Elasticsearch支持半结构化数据,但是在实际使用中还是应该尽最大可能对数据结构加以控制。第二,因为Elasticsearch不支持JOIN操作,所以Schema应该尽量扁平化。第三,对于只需要做精确匹配的字段,应该设置为不做分词,5.5中通过type=keyword来设定。
- 参数调整,即修改部分参数的默认值来适应自身业务。Elasticsearch中有很多参数可用,几乎可以满足大多数的业务需求,你很难记住所有的,不妨在有相关需求时先去文档查查看。
这里将结合上述Index Template示例,阐述几个笔者用过的Mapping参数。
_all参数
假设在你的业务中,需要根据关键词来查找某条数据,但是并不明确知道要到哪个字段中去查,这时用_all参数就可以帮助你解决。_all=true时,Elasticsearch会在写入数据时将其所有字段值合并起来组合为一个新的值,对其建立索引,用来满足前面所述的搜索需求。也就是说,如果你的业务没有这种需求,那么将其设置为false,可以节省磁盘、提高性能。
_source参数
我们知道Elasticsearch中存储的每一条数据都是一个JSON结构,在写入数据时会对每个字段建立Inverted Index、doc values等,如果_source=true,Elasticsearch会将整个JSON数据也存储下来。如果你的业务中,不需要查询原始数据,只需要根据索引来过滤然后做聚合查询,那么可以将其设置为false,同样可以节省磁盘空间、提高性能。
dynamic参数
假如突然有一条数据里面包含了一个没有定义的字段,这时你期望Elasticsearch怎么做?dynanic参数便是用来处理此种情况的,有三种选择:strict表示不接受数据中包含没有定义的字段,发现了就报错;true表示允许没有定义的字段被插入进来;false表示忽略没有定义过的字段,继续写入数据的其他信息。具体怎么选,更多的取决于业务需求,但是要考虑清楚可能带来的后果。在笔者的项目中,就选择了strict,用来拒绝一切脏数据。
ignore_malformed参数
假设有一个字段CLF_ClientIP传过来的是字符串,我们期望将其转换为ip数据类型,方便做查询。理论上,将type设置为ip就可以解决了,但是有这么一种情况,客户端在某些情况下没有拿到对应的IP信息,用了一个“–”来表示,这样的数据到了Elasticsearch端是没法转换为ip数据类型的,但是这又是一条正常数据,该怎么处理呢?通过ignore_malformed=true,可以做到忽略CLF_ClientIP字段而保留数据的其他信息。
3. 巧妙的Alias
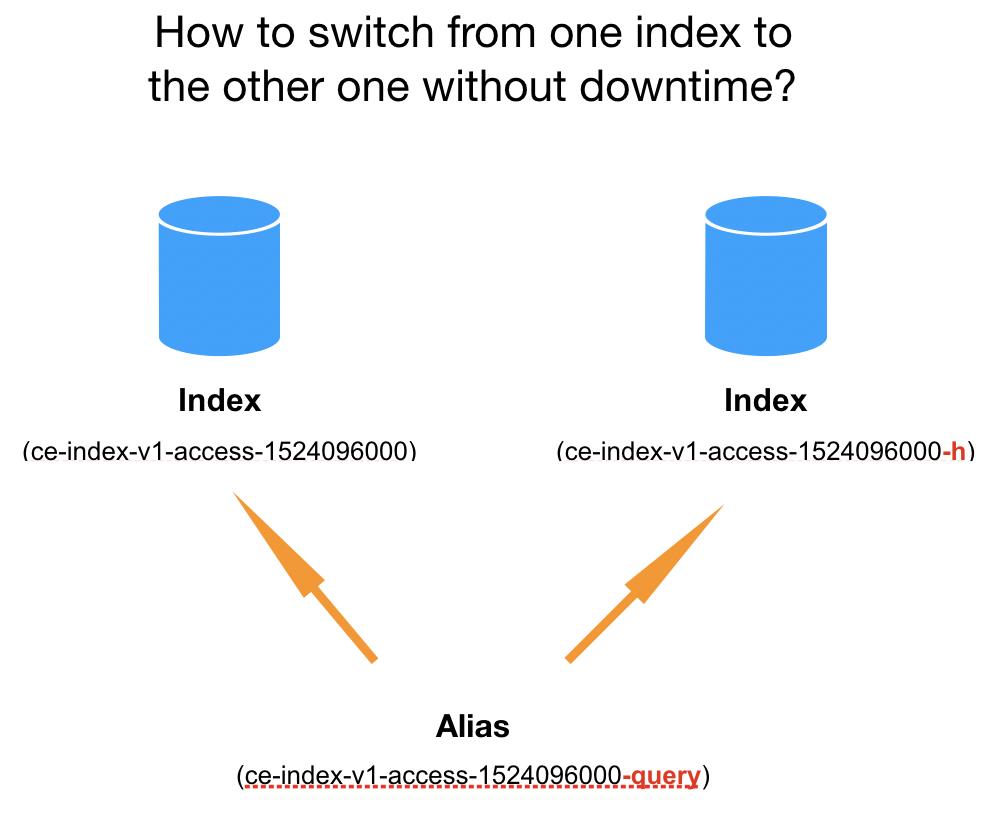
Alias,顾名思义,就是Index的别名。一个Alias可以指向多个Index,一个Index也可以关联多个Alias,具体可以通过Alias的REST API来设定。在查询数据时,Elasticsearch会自动检测请求的Path是否是Alias,是的话就会从其关联的Index中查询数据。Alias的巧妙之处在于,能帮助我们将查询请求无缝的从一个Index切换到另一个Index上面,这种切换对于客户端是透明的。
举个例子来阐述,上面有提到,在笔者业务中,存在一种数据合并:将分钟粒度数据合并成小时粒度的数据,从而可以降低数据量、提高查询性能。下图中,左边表示分钟粒度数据的Index,右边表示小时粒度数据的Index。用户的查询会先命中到分钟粒度Index上,一天之后,当历史数据完成合并后,会将查询请求转到小时粒度Index上(分钟粒度的Index会被删除)。通过Alias,我们就可以实现这种没有downtime的切换,并且对客户端透明。客户端只要按照固定的Alias来查询即可,至于Elasticsearch这边从哪个Index来查,则是取决于不同时间这个Alias关联的Index。(在数据合并完成后,切换Alias关联的Index,在一个请求中完成卸载老的Index和关联新的Index。)
4. Shard分配原则
所谓Shard分配原则,就是如何设定Primary Shard的个数。看上去只是一个数字而已,也许在很多场景下,即使不设定也不会有问题(默认是5个Primary Shard)。但是如果不提前考虑,一旦出问题就可能导致系统性能下降、不可访问、甚至无法恢复。换句话说,即使使用默认值,也应该是通过足够的评估后作出的决定,而非拍脑袋定的。具体的分配方法,很难给出一个完美的套路适用于所有的业务需求,这里主要结合笔者的实践谈几点原则和调整方法,给大家提供一个思路。
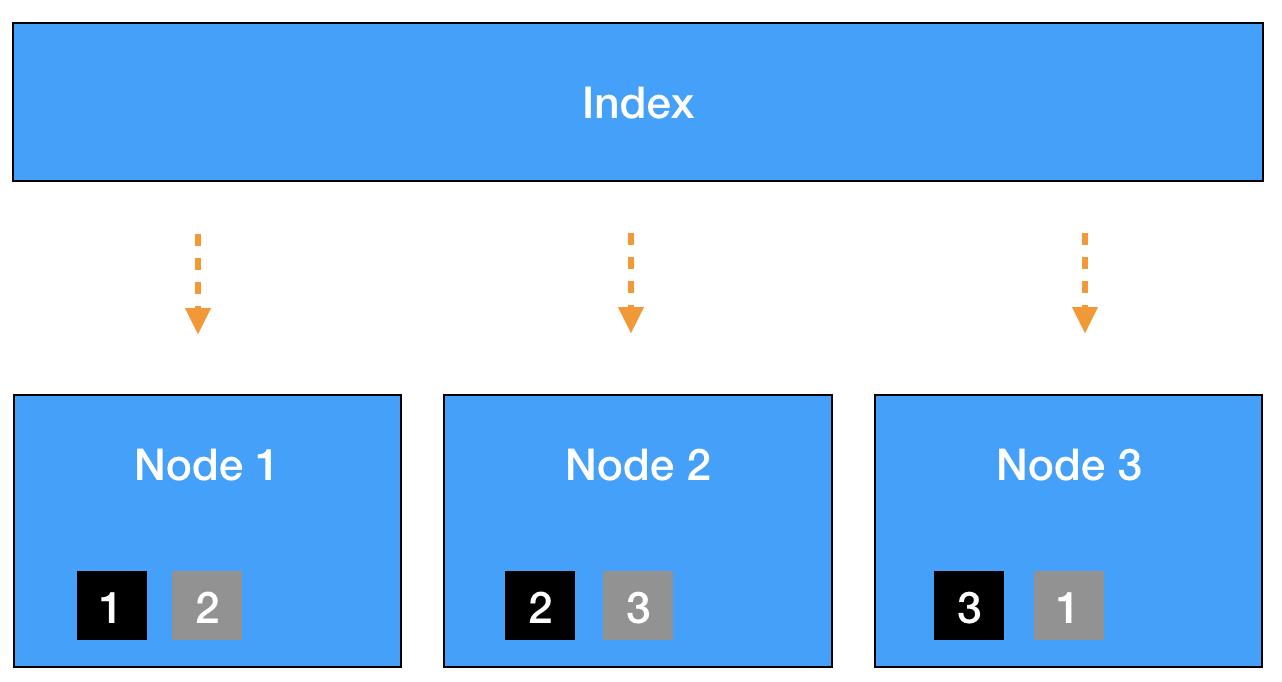
- 单个Shard的存储大小不超过30GB。首先,为什么是30GB?关于这个值,来自于笔者跟AWS和Elastic专家的沟通结果,大家普遍认为30GB是个合适的上限值。目前我们尚未对此做过测试验证,不过实践中确实遇到过因为单个Shard过大(超过30GB)导致系统不稳定的情况。其次,为什么不能超过30GB?主要是考虑Shard Relocate过程的负载。我们知道,如果Shard不均衡或者部分节点故障,Elasticsearch会做Shard Relocate,在这个过程中会搬移Shard,如果单个Shard过大,会导致CPU、IO负载过高进而影响系统性能与稳定性。
- 单个Index的Primary Shard个数 = k * 数据节点个数。在保证第一点的前提下,单个Index的Primary Shard个数不宜过多,否则相关的元信息与缓存会消耗过多的系统资源。这里的k,为一个较小的整数值,建议取值为1,2等,整数倍的关系可以让Shard更好地均匀分布,可以充分的将请求分散到不同节点上。
- 对于很小的Index,可以只分配1~2个Primary Shard的。有些情况下,Index很小,也许只有几十、几百MB左右,那么就不用按照第二点来分配了,只分配1~2个Primary Shard是可以,不用纠结。
- 聊一个特殊的例子。曾经遇到过一个Index,里面存放的是关键事件的日志信息,数据量不大(400MB左右),所以只分配了2个Primary Shard。但是因为“最近的事件”是用户非常关注的,所以这个Index承载了整个集群50%以上的查询请求,为了提高查询性能,将请求分散到不同机器上,最后还是将Primary Shard设置为数据节点的个数。
5. 整体思路
Index与Shard的设计,并不是一下子就可以完成的,需要不断预估、测试、调整、再测试来达到最终模型。整个过程大致如下图时间轴所示,分为以下几个阶段,当然期间有很多阶段是需要迭代的。
- 第一阶段,Index的设计,即完成本文第1~3小节提到的内容。这一阶段是完成业务需求的分解与设计,之后剩下的就是如何构建Elasticsearch集群来承载这样的需求了。
- 第二阶段,预估数据量。预估单个Index的数据量,结合需要保留的数据周期可以得到整体的数据量。
- 第三阶段,预估机型。根据业务的场景,来决定选择CPU增强型、内存增强型还是通用型机器(针对云服务)。
- 第四阶段,预估机器个数。因为单机能挂载的磁盘大小是有限的,因此知道了数据量,也就知道了最少需要多少台机器。在预估磁盘空间时,还需要考虑另外两个因素:一个是Replica,即副本的个数,大多数情况下1个就够了(当然还是取决于业务);另一个是预留30%的磁盘空间,这部分空间既是预留给系统使用的,也是为磁盘告警的处理预留足够的时间。
- 第五阶段,预估Primary Shard个数。即参考第4小节中的思路,预估Primary Shard的个数。
- 第六阶段,部署、测试。根据性能测试和业务的特殊情况,做适当调整,调整可能包括Primary Shard个数、机型、机器个数等。

(全文完,本文地址:https://blog.csdn.net/zwgdft/article/details/86416668 )
(版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!)
Bruce
2019/01/22 下午
以上是关于ElasticSearch中index的设计的主要内容,如果未能解决你的问题,请参考以下文章