数据库三大范式及事务
Posted 雪山上的蒲公英
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库三大范式及事务相关的知识,希望对你有一定的参考价值。
数据库三大范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
在实际开发中最为常见的设计范式有三个:
1.第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。

上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
2.第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
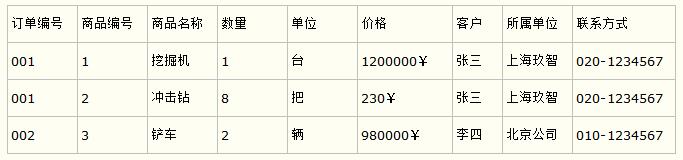
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
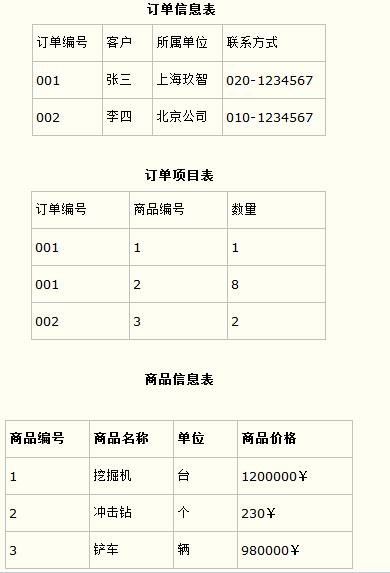
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
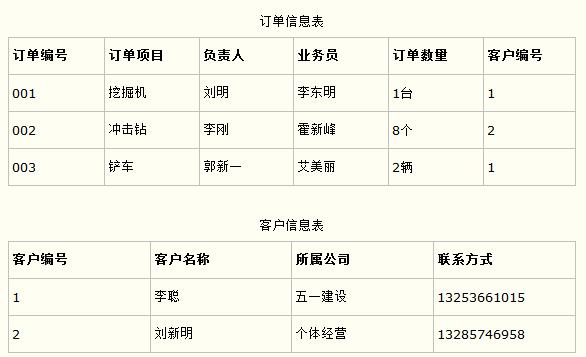
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
E-R图
E-R图为实体-联系(Entity-Relation)图,提供了表示实体型、属性和联系的方法,用来描述现实世界的概念模型。
构成E-R图的基本要素是实体型、属性和联系,其表示方法为:
· 实体型(Entity):用矩形表示,矩形框内写明实体名;比如学生张三丰、学生李寻欢都是实体。
· 属性(Attribute):用椭圆形表示,并用无向边将其与相应的实体连接起来;比如学生的姓名、学号、性别、都是属性。
· 联系(Relationship):用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时在无向边旁标上联系的类型(1 : 1,1 : n或m : n)。 比如老师给学生授课存在授课关系,学生选课存在选课关系。
如下图所示:是一个班级、学生、课程、教师之间的ER图:
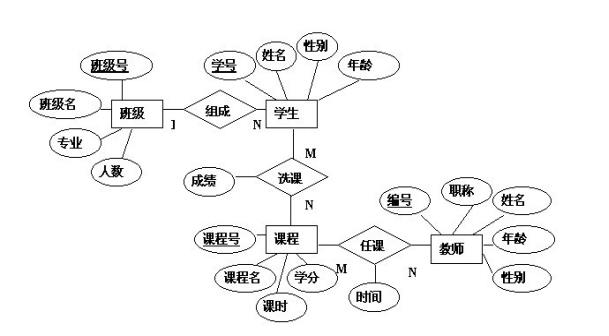
实体-联系图(Entity-Relation Diagram)用来建立数据模型,在数据库系统概论中属于概念设计阶段,形成一个独立于机器,独立于DBMS的ER图模型。 通常将它简称为ER图,相应地可把用ER图描绘的数据模型称为ER模型。ER图提供了表示实体(即数据对象)、属性和联系的方法,用来描述现实世界的概念模型。
ER模型最早由Peter Chen于1976年提出,它在数据库设计领域得到了广泛的认同,但很少用作实际数据库管理系统的数据模型。即使对SXL-92数据库来说,设计好的数据库也是具有挑战性的。它们可以在许多关于数据库设计的文献中找到,比如Toby Teorsey 的著作(1994 )。
大部分数据库设计产品使用实体-联系模型(ER模型)帮助用户进行数据库设计。ER数据库设计工具提供了一个“方框与箭头”的绘图工具,帮助用户建立ER图来描绘数据。
编辑本段
构成E-R图的基本要素是实体、属性和联系。 一个简单的例子
实体(entity):客观存在并且可以相互区分的事物称为实体。实体既可以是具体的对象,也可以是抽象的对象。
属性(attribute):实体的特性称为属性。主属性(identifier)则是能唯一标识实体的属性。
联系(relationship):实体之间的相互关系称为联系。联系可分为“一对一联系”、“一对多联系”、“多对多联系” 3种类型。
编辑本段
成分
在ER图中有如下四个成分:
矩形框:表示实体,在框中记入实体名。
菱形框:表示联系,在框中记入联系名。
椭圆形框:表示实体或联系的属性,将属性名记入框中。对于主属性名,则在其名称下划一下划线。
连线:实体与属性之间;实体与联系之间;联系与属性之间用直线相连,并在直线上标注联系的类型。(对于一对一联系,要在两个实体连线方向各写1; 对于一对多联系,要在一的一方写1,多的一方写N;对于多对多关系,则要在两个实体连线方向各写N,M。)
单元测试
http://blog.csdn.net/sunzhenhua0608/article/details/8858151
事务(Transaction)是并发控制的基本单位。所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行。所以,应该把它们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
针对上面的描述可以看出,事务的提出主要是为了解决并发情况下保持数据一致性的问题。
事务具有以下4个基本特征。
● Atomic(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败。
● Consistency(一致性):只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初状态。
● Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。同时,并行事务的修改必须与其他并行事务的修改相互独立。
● Durability(持久性):事务结束后,事务处理的结果必须能够得到固化。
2.事务的语句
开始事物:BEGIN TRANSACTION
提交事物:COMMIT TRANSACTION
回滚事务:ROLLBACK TRANSACTION
3.事务的4个属性
①原子性(Atomicity):事务中的所有元素作为一个整体提交或回滚,事务的个元素是不可分的,事务是一个完整操作。
②一致性(Consistemcy):事物完成时,数据必须是一致的,也就是说,和事物开始之前,数据存储中的数据处于一致状态。保证数据的无损。
③隔离性(Isolation):对数据进行修改的多个事务是彼此隔离的。这表明事务必须是独立的,不应该以任何方式以来于或影响其他事务。
④持久性(Durability):事务完成之后,它对于系统的影响是永久的,该修改即使出现系统故障也将一直保留,真实的修改了数据库
4.事务的保存点
SAVE TRANSACTION 保存点名称 --自定义保存点的名称和位置
ROLLBACK TRANSACTION 保存点名称 --回滚到自定义的保存点
其他高手的一些补充:
事务的标准定义: 指作为单个逻辑工作单元执行的一系列操作,而这些逻辑工作单元需要具有原子性, 一致性,隔离性和持久性四个属性,统称为ACID特性。
所谓事务是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位。例如,在关系数据库中,一个事务可以是一条SQL语句、一组SQL语句或整个程序。
事务和程序是两个概念。一般地讲,一个程序中包含多个事务。
事务的开始与结束可以由用户显式控制。如果用户没有显式地定义事务,则由DBMS按缺省规定自动划分事
务。在SQL语言中,定义事务的语句有三条:
BEGIN TRANSACTION
COMMIT
ROLLBACK
同生共死。。
显示事务被用begin transaction 与 end transaction 标识起来,其中的 update 与 delete 语句或者全部执行或者全部不执行。。 如:
begin transaction T1
update student
set name=\'Tank\'
where id=2006010
delete from student
where id=2006011
commit
简单地说,事务是一种机制,用以维护数据库的完整性。
其实现形式就是将普通的SQL语句嵌入到Begin Tran...Commit Tran 中(或完整形式 Begin Transaction...Commit Transaction),当然,必要时还可以使用RollBack Tran 回滚事务,即撤销操作。
利用事务机制,对数据库的操作要么全部执行,要么全部不执行,保证数据库的一致性。需要使用事务的SQL语句通常是更新和删除操作等。
end transaction T1
关于savepoint
用户在事务(transaction)内可以声明(declare)被称为保存点(savepoint)
的标记。保存点将一个大事务划分为较小的片断。
用户可以使用保存点(savepoint)在事务(transaction)内的任意位置作标
记。之后用户在对事务进行回滚操作(rolling back)时,就可以选择从当前
执行位置回滚到事务内的任意一个保存点。例如用户可以在一系列复杂的更
新(update)操作之间插入保存点,如果执行过程中一个语句出现错误,用
户 可以回滚到错误之前的某个保存点,而不必重新提交所有的语句。
在开发应用程序时也同样可以使用保存点(savepoint)。如果一个过程
(procedure)内包含多个函数(function),用户可以在每个函数的开始位置
创建一个保存点。当一个函数失败时, 就很容易将数据恢复到函数执行之前
的状态,回滚(roll back)后可以修改参数重新调用函数,或执行相关的错误
处理。
当事务(transaction)被回滚(rollback)到某个保存点(savepoint)后,
Oracle将释放由被回滚语句使用的锁。其他等待被锁资源的事务就可以继续
执行。需要更新(update)被锁数据行的事务也可以继续执行。
将事务(transaction)回滚(roll back)到某个保存点(savepoint)的过程如
下:
1. Oracle 回滚指定保存点之后的语句
2. Oracle 保留指定的保存点,但其后创建的保存点都将被清除
3. Oracle 释放此保存点后获得的表级锁(table lock)与行级锁(row
lock),但之前的数据锁依然保留。
被部分回滚的事务(transaction)依然处于活动状态,可以继续执行。
一个事务(transaction)在等待其他事务的过程中,进行回滚(roll back)到
某个保存点(savepoint)的操作不会释放行级锁(row lock)。为了避免事务
因为不能获得锁而被挂起,应在执行 UPDATE 或 DELETE 操作前使用 FOR
UPDATE ... NOWAIT 语句。(以上内容讲述的是回滚保存点之前所获得的
锁。而在保存点之后获得的行级锁是会被释放的,同时保存点之后执行的
SQL 语句也会被完全回滚)
☆事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要不全部成功,要不全部不成功。
例如:A——B转帐,对应于如下两条sql语句
update from account set money=money+100 where name=‘b’;
update from account set money=money-100 where name=‘a’;
☆数据库开启事务命令
start transaction 开启事务
Rollback 回滚事务
Commit 提交事务
set transction isolation level 设置事务隔离级别
select @@tx_isolation 查询当前事务隔离级别
☆事务的特性(ACID)
原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
隔离性(Isolation)事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响。
使用JDBC管理事务
当一个连接对象被创建时,默认情况下JDBC是自动提交事务:每次执行一个 SQL 语句时,如果执行成功,就会向数据库自动提交,而不能回滚。如想多条SQL在同一事务中,可使用下列语句:
☆JDBC控制事务语句
Connection.setAutoCommit(false);
Connection.rollback();
Connection.commit();
☆演示银行转帐案例
在JDBC代码中使如下转帐操作在同一事务中执行。
update from account set money=money-100 where name=‘a’;
update from account set money=money+100 where name=‘b’;
☆设置事务回滚点
Savepoint sp = conn.setSavepoint();
Conn.rollback(sp);
Conn.commit(); //回滚后必须要提交
☆事务的隔离级别
多个线程开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个线程在获取数据时的准确性。
☆数据库共定义了四种隔离级别:
Serializable(串行化):可避免脏读、不可重复读、虚读情况的发生。
Repeatable read(重复读):可避免脏读、不可重复读情况的发生。
Read committed(读提交):可避免脏读情况发生。
Read uncommitted(读未提交):最低级别,以上情况均无法保证。
☆事务的隔离性
*脏读:
指一个事务读取了另外一个事务未提交的数据。
这是非常危险的,假设A向B转帐100元,A在一台电脑上开启事务执行如下2步操作,向B存入100元,并把自己的钱减少100元:
1.update account set money=money+100 while name=‘b’;
2.update account set money=money-100 while name=‘a’;
当第1步执行完,第2步还未执行,A未提交时,此时B查询自己的帐户就会发现自己多了100元钱,以为A转了100元。如果A等B走后再回滚,B就会损失100元。
*不可重复读:
在一个事物内读取表中的某一行数据,多次读取结果不同。
例如银行想查询A帐户余额,第一次查询A帐户为200元,此时A向帐户内存了100元,银行此时又进行了一次查询,此时A帐户为300元了,银行可能就会很困惑,不知道哪次查询是准的。和脏读的区别是,脏读是读取前一事务未提交的脏数据,不可重复读是重新读取了前一事务已提交的数据。
很多人认为这种情况就对了,无须困惑,当然是后面的为准。我们可以考虑这样一种情况,比如银行程序需要将查询结果分别输出到电脑屏幕和写到文件中,结果在一个事务中针对输出的目的地,进行的两次查询不一致,导致文件和屏幕中的结果不一致,银行工作人员就不知道以哪个为准了。
*虚读
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。
如丙存款100元未提交,这时银行做报表统计account表中所有用户的总额为2700元,然后丙提交了,这时银行再统计发现帐户为2800元了,造成虚读同样会使银行不知所措,到底以哪个为准。
以上是关于数据库三大范式及事务的主要内容,如果未能解决你的问题,请参考以下文章