数据库的三大范式索引事务
Posted 小猪媛不圆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库的三大范式索引事务相关的知识,希望对你有一定的参考价值。
数据库的三大范式、索引、事务
1.数据库的三大范式
写在前面:三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
1.1 第一范式(1NF):列不可再拆分
- 每一列属性都是不可再分的属性值,确保每一列的原子性
- 两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据
1.2 第二范式(2NF):保证表中每一列都和主键相关
第二范式是在第一范式的基础上建立起来的,即满足第二范式必须先满足第一范式。第二范式要求数据库表中的每个实例或行必须可以被唯一的区分,为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。这个唯一属性列被称为主键。
1.3 第三范式(3NF):数据库中的每一列都和主键直接相关,而不是间接相关
数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。像:a–>b–>c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号–> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)–(所在院校,院校地址,院校电话)
2.数据库索引
2.1 什么是索引
- 索引是一种特殊的文件,包含着对书库表里所有记录的引用指针。可以对表中的一列或者多列创建索引。并指定索引的类型。
- 索引是一种数据结构。数据库索引是数据控制管理系统中的一个排序的数据结构,以协助快速查询,更新数据库表中的数据。
- 索引的通常实现是B+树
- 通俗的说,索引就相当于目录,表就相当于书,而数据就是书中的内容。通过内容建立索引形成目录
- 索引就是一个文件,需要占据物理空间
2.2 索引的使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑下面几点:
- 数据量较大,且经常对这些列进行条件查询
- 该数据库表的插入操作,及对这些列的修改操作频率较低
- 索引会占用额外的磁盘空间
满足以上条件是,考虑对表中的这些字段创建索引,以提高查询效率
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
2.3 索引的底层实现
2.3.1 为什么数据库索引结构不使用Hash表或者二叉搜索树?
- 对于Hsah表:哈希表需要明确的知道key的值是什么,才可以通过哈希函数计算得到下标,进而进行查找得到数据,这样在模糊匹配的时候,key值无法确定,就无法利用哈希表进行查找了。
- 对于二叉搜索树:二叉搜索树的特点是,每个非叶子节点都有两个孩子节点,但这样会导致在数据量非常大的情况下,二叉搜索树的深度过深,在进行搜索的时候,子根节点向下进行搜索需要访问的叶子结点也会非常多,大大降低了查询的效率。
2.3.2 mysql索引结构——B+树
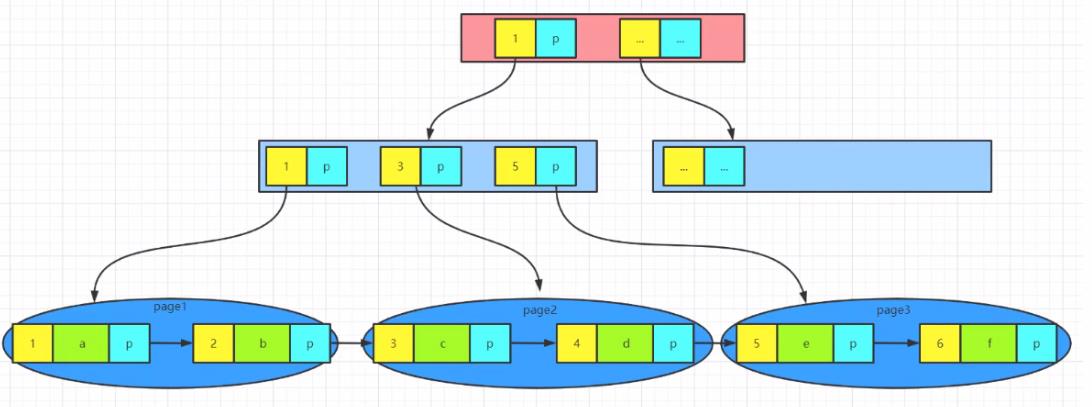
这种结构就是B+树
特点:
- B树中的非叶子结点也可能会存储数据,但是B+树的数据一定是存放在叶子结点上,非叶子结点只是用来辅助进行查找
- 每一层兄弟结点之间都是相互连通的(类似于链表),通过指针关联不同的数据,这使得遍历起来更加方便,尤其是指定区间进行查找的时候
总结
- B+树对于哈希表来说,可以处理模糊匹配的场景
- B+树对于二叉搜索树来说,深度更低,查找效率更高
- B+树对于B树来说
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索
- 单一节点可以存储更多的数据,降低查询的IO次数
- 所有的查询都需要查找到叶子节点1,使得查询性能更稳定
- 兄弟节点之间形成有序链表,便于范围内查找,增删效率也高
2.3.3 索引的使用
在创建主键约束(primary key),唯一约束(unique),外键约束(foreign key)时,会自动创建该列的索引
- 查看索引
show index from 表名;
- 创建索引
// 对于非主键,非唯一约束,非外键的字段,创建普通索引
create index 索引名 on 表名(字段名);
- 删除索引
drop index 索引名 on 表名;
3.数据库事务
事务是一个不可分割的数据库操作序列,也就是数据库并发控制的基本单位;事务是逻辑上的一组操作,这组操作的各个单元要么全部执行成功,要么全部执行失败(事务的典例:转账)
3.1 事务的四大特征
- 原子性:事务是最小的执行单位,不允许分割,其中包含的操作,要么全部执行成功,要么前部执行失败
- 一致性:事务执行前后,数据要保持在一种合法的情况(无论事务最后执行是成功的,还是失败的,最终数据库中的数据都是满足实际生活中的逻辑的)
- 持久性:一个事务一旦被提交,对于数据库的修改就是永久的,即使数据库发生故障也不会对其有任何影响
- 隔离性:多个事务并发执行时,事务的内部操作和其他事务的内部操作时相互隔离,互不影响的。
3.2 并发操作数据库可能带来的问题
- 脏读(Dirty-Read):指一个事务A读取了另一个事务B没有提交的数据,由于 某些原因,B对数据进行了修改,则A读到的数据就是不正确的,这就是脏读。
为了解决脏读问题,可以给写操作加锁,一个事务在没有提交数据之前,不能被读取。
- 不可重复读(Non-repeatable read):一个事务先后两次读取到的数据不一 致,可能是两次读取过程中插入了一个事务更新了原有的数据,这就是不可重 复读。
为了解决不可重复读,可以给读操作加锁,一个事务在没有读完之前不能修改数据。
幻读(Phantom Read):同一个事务中,多次查询返回的结果集不一样。例如
有一个事务查询了几列数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。这就是幻读。
如果要避免幻读,就得进一步提高隔离性,即“串行化”。
以上是关于数据库的三大范式索引事务的主要内容,如果未能解决你的问题,请参考以下文章