集群概述
Posted 火星小编
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集群概述相关的知识,希望对你有一定的参考价值。
集群概述
一、为什么使用集群。
在当前的互联网中,网页浏览成为我们日常中的必须。网页浏览的连接数对硬件是一个极大的考验。
如果我们的服务器硬件不能应对高强度的访问量时,就需要扩展.
扩展:
1、向上扩展:对当前服务器进行性能升级,提高CPU、内存的性能。但代价极大。
2、向外扩展:对服务器数量进行增加,提高服务器整体的性能,但需要集群技术。
二、集群技术
( 一)、集群技术的问题。
1、集群中各个服务器之间的连接和应用。
2、解决各个服务器之间性能的差异,合理使用服务器性能。
3、现在浏览器都是多并发,一个客户端访问的一个页面有可能是多个服务器提供的页面,这样会更快。
负载均衡集群
使用调度器来实现对各个服务器的访问。
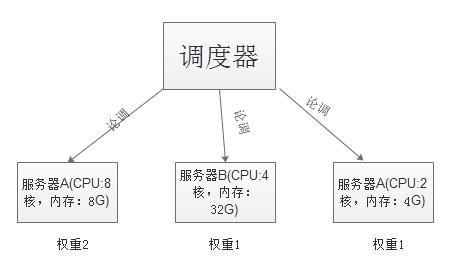
1、轮调:使用服务器调度机制来实现轮调(第一个用户请求到第一台,第二个用户到第二台)
2、加权轮流(公平和性能):不同服务器性能不同,可以使用权重来区分不同服务器的性能。
1、简单的web框架
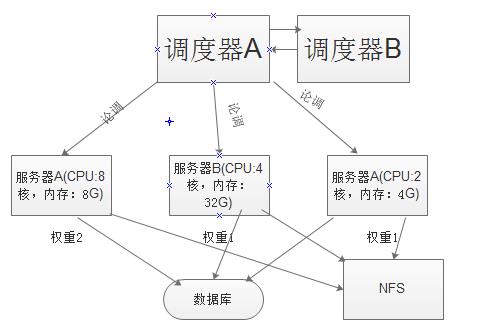
1.1、mysql服务器
1、登录信息
用户名、密码等信息。
2、图片、文档等大文件
利用另一个存储(NFS)服务器存储,数据库保存链接。
1.2、本地文件
1、网页页面和更新
利用主服务向其他从服务同步
1.1、利用rsync+inotify 实现同步
1.3、存储服务器
利用NFS共享来存储大文件
2、减缓调度器
备份调度器(高可用)
准备:两台调度器,一台primary,一台standby
条件:ip地址、服务全部转换、文本文件在服务器中都有。
发生:一旦发生故障马上切换
横向切分
划分多个小集群,来划分解决调度器负载过大
3、负载均衡中的高可用能力(但不是高可用集群)
利用负载均衡中的的调度器,在发现集群中有服务器宕机后,可以让调度器重新分发用户请求。
不会让一台服务器宕机,从而让所有服务无法访问。所以负载均衡具有一定的高可用能力。
4、健康状态检查(health check)机制
可以对正常到宕机、宕机到恢复这个过程中进行操作(故障时踢出集群,恢复时重新加入到集群中)。
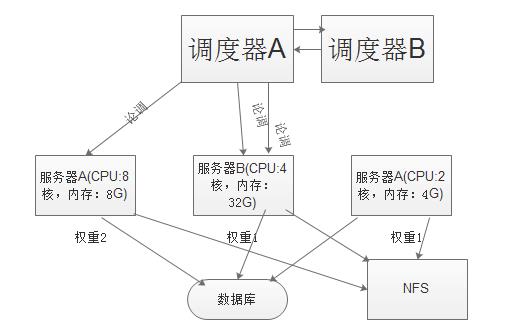
负载均衡中的高可用能力(图)
高可用集群
“高可用性”(High Availability)通常来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性。
可用性:在线时间/(在线时间+故障处理时间)
机制:
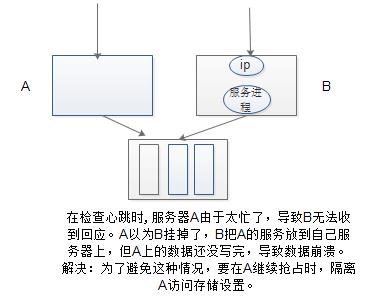
1、检查心跳机制
利用hearbeat中心跳数来确定服务器是否还在,通过发送并收到回应来确定服务器是否挂掉。发送是每分钟都会发送,按响应来确定服务器是否挂掉。
2、数据崩溃
使用隔离:节点级别
资源级别
3、高可用采用奇数个节点
采用奇数个节点的好处在于可以利用多个节点来控制单个节点或利用单个节点把自己隔离出这个集群。利用3个节点更容易判别那个节点出现问题。

用高可用集群搭建web:
1、问题:
(一)、NFS在框架中3台服务器可以承受,但如果是30台并发就会非常慢。
解决:搭建集群存储来完成。通过并行文件系统与基于对象的存储相结合,存储集群在 Linux 集群环境中提高了可管理性和性能。系统是基于集群设计的,它达到了极高的可扩展性和可用性。
需要知识点:
(1) 直接连接存储(DAS)
DAS 系统原本是设计来为部门级的 IT 环境提供直接的小数据池的访问的。对于小的集群,这可能是一种可接受的解决方案,但当集群规模增长时,就需要一个一个地增加 DAS 系统,而这些系统之间又不能直接通信,所以它们肯定是被作为数据孤岛被管理的。
(2) 网络连接存储(NAS)
NAS 系统,或专门的 NFS 服务器被设计来提供在异构平台上的广泛的数据共享,在那里,多台主机能共享文件,每个用户有相对适度的 I/O 需求。一个例子是部门级的工作站网络。例如:用作用户的根目录(home directory)的存储。然而,当增加容量来支持更多的应用和客户访问系统时, NAS 系统的性能不能很好地扩展。事实上,还经常出现相反的情况。增加容量实际上会降低系统的性能。用户通常采用的一种方法,是购买许多 NAS 控制器(filers),把用户的工作负载分散到许多 NAS 系统上去。这种情形相似于 NAS 出现之前的情况,去购买许多文件服务器来管理日益增长的数据存储需要。相似于 SAN,这会导致成本和复杂性的增加。
(3)存储区域网(SAN)
SAN 被设计来向适度数量的应用服务器提供对共享的存储设备池的高性能,高可靠性的访问,例如,企业级的事务处理数据库。SANs为存储配给过程提供了杠杆作用 — 允许磁盘在应用服务器之间重新分配,很容易满足容量需求的改变,但是会形成基于应用服务器的数据孤岛。这常常导致复杂性和管理费用的增加。
传统的SAN与NAS分别提供的是数据块与文件两个不同级别的存储服务,集群存储也分为提供数据块与文件两个不同级别存储服务的集群存储系统。
解决需要集群存储:
(4)集群存储
集群存储是将多台存储设备中的存储空间聚合成一个能够给应用服务器提供统一访问接口和管理界面的存储池,应用可以通过该访问接口透明地访问和利用所有存储设备上的磁盘,可以充分发挥存储设备的性能和磁盘利用率。数据将会按照一定的规则从多台存储设备上存储和读取,以获得更高的并发访问性能。
存储集群文件系统
存储集群的心脏是存储集群文件系统,它把文件的活动分散到许多存储设备中。
概念:
集群文件系统是指运行在多台计算机之上,之间通过某种方式相互通信从而将集群内所有存储空间资源整合、虚拟化并对外提供文件访问服务的文件系统。其与NTFS、EXT等本地文件系统的目的不同,前者是为了扩展性,后者运行在单机环境,纯粹管理块和文件之间的映射以及文件属性。
集群文件系统的分类:,按照对存储空间的访问方式,可分为共享存储型集群文件系统和分布式集群文件系统,前者是多台计算机识别到同样的存储空间,并相互协调共同管理其上的文件,又被称为共享文件系统;后者则是每台计算机各自提供自己的存储空间,并各自协调管理所有计算机节点中的文件。Veritas的CFS,昆腾Stornext,中科蓝鲸BWFS,EMC的MPFS,属于共享存储型集群文件系统。而HDFS、Gluster、Ceph、Swift等互联网常用的大规模集群文件系统无一例外都属于分布式集群文件系统。分布式集群文件系统可扩展性更强,目前已知最大可扩展至10K节点。
按照文件访问方式来分类:集群文件系统可分为串行访问式和并行访问式,后者又被俗称为并行文件系统。串行访问是指客户端只能从集群中的某个节点来访问集群内的文件资源,而并行访问则是指客户端可以直接从集群中任意一个或者多个节点同时收发数据,做到并行数据存取,加快速度。HDFS、GFS、pNFS等集群文件系统,都支持并行访问,需要安装专用客户端,传统的NFS/CIFS客户端不支持并行访问。
可以使用的集群存储系统有:
块级集群存储系统 如:IBM XIV集群存储系统
文件级集群存储系统 如:HP Ibrix集群存储系统华赛 N8500集群NAS系统
开源的文件系统(开源中国):http://www.oschina.net/project/tag/104/storage
常见的分布式文件系统
GFS :Google File System
HDFS:适合存储大文件;
TFS:在名称节点上将元数据存储于关系型数据中,文件数量不再受限于名称节点的内存空间;可以存储海量小文件;
Lustre: 企业级应用,重量级;
GlusterFS: 适用于存储少量大文件 ,流媒体,云
MooseFS: 通用简便,适用于存储小文件,大文件也不错
Mogilefs: 使用Perl语言,FastDFS
FastDFS:在内存中存储
Ceph:内核级别,支持PB级别存储
Squid是一款高性能分布式代理缓存服务器。
2、参数
2.1、存储器
1、登录信息
用户名、密码等信息。
2、图片、文档等大文件
利用另一个存储(NFS)服务器存储,数据库保存链接。也可以使用存储集群。
3、可使用redis(内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理)开快访问速度。
2.2、本地文件(主要服务、文件等)
1、网页页面和更新
利用主服务向其他从服务同步
1.1、利用rsync+inotify 实现同步
2.3、节点和资源
节点:每个服务器(节点)最好只实现一个服务功能。
资源:每个服务器中运行的程序和文件。
2.4、存储设备中的块级别和文件级别
块级别:文件包含多个块,块来自磁盘的多个扇区。一般在本地是使用块级访问。
文件级别:远程访问或请求。如:以文件方式访问到NFS共享中的文件(文件方式)。
本地访问和使用我们称为:直接附加存储(DAS)
连接在网络上存储功能的装置:网络附属存储(NAS)
3、模型
3.1、高可用集群的服务整合
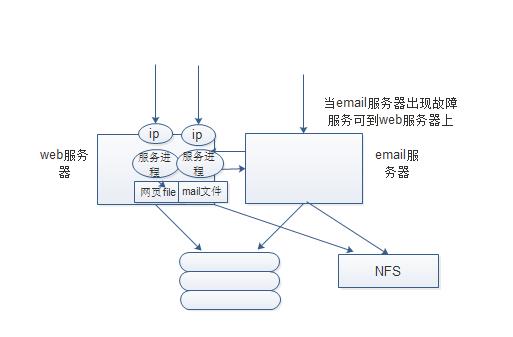
如果有两台服务器,一台是web服务,一台是email服务。web服务器比email服务器强,可把web服务器当成email服务器的备份。
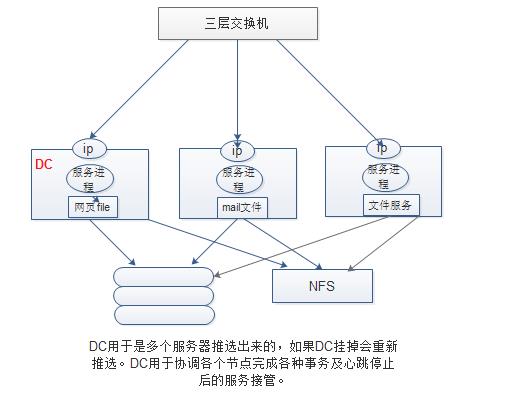
3.2、高可用集群的协调
DC事务协调(协调各个节点完成各种事务及心跳停止后的实现服务整合)
高性能计算集群
高性能计算(High Perfermance Computing)集群,简称HPC集群。这类集群致力于提供单个计算机所不能提供的强大的计算能力。
类型:
(一)向量机 :基本不会用到
(二)并行处理集群:如:hadoop
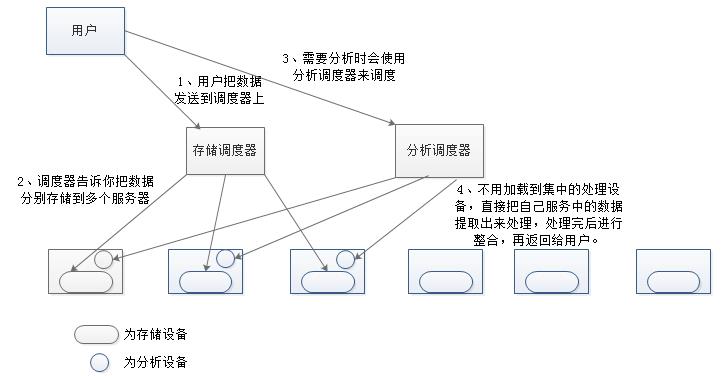
所用机制:
1、 分布式文件系统。
2、 将大任务切割成小任务,分别进行处理机制。
集群中的负载均衡集群、高可用集群、高性能计算集群的区别:
负载均衡集群
负载均衡集群中的高可用依赖于前端调度器,而不是后端相互之间的服务器。
如果前端服务器出现故障,还是给后端的宕机服务器分发用户请求,就需要在前端部署健康状态检查(health check)机制。
着重点: 是以提高服务的并发处理能力为主
高可用集群
高可用集群利用相互之间的信号可以实现快速转换
着重点:是以服务的始终在线为主,不能因为宕机而服务不可用。
高性能计算集群
需要海量计算的问题的集群和需要科学运算的集群
分布式(集群)与集群的联系与区别
分布式是指将不同的业务分布在不同的地方。
而集群指的是将几台服务器集中在一起,实现同一业务。
分布式中的每一个节点,都可以做集群。
集群并不一定就是分布式的。
举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。
分布式,从窄意上理解,也跟集群差不多, 但是它的组织比较松散,不像集群,有一个组织性,一台服务器垮了,其它的服务器可以顶上来。
分布式的每一个节点,都完成不同的业务,一个节点垮了,哪这个业务就不可访问了。
以上是关于集群概述的主要内容,如果未能解决你的问题,请参考以下文章