EM算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EM算法相关的知识,希望对你有一定的参考价值。
(一)中我们谈到,如果带入样本分类的不确定性,我们要估计的(1)式就会变得相当复杂,为了绕开这个问题,靠的就是EM算法。
这里我决定倒着讲,可能更容易然大家理解。首先,说一下EM算法是怎么操作来让(4)式的最大值逼近(1)式的最大值的;接下来,会在几何的角度上证明我们的想法。最后,会把论文中提到的式子加以证明。
EM是怎么操作的?
E步:给定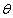 (第一次迭代时候可以随机给出初始值),令
(第一次迭代时候可以随机给出初始值),令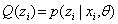 。
。
M步:求解令(4)式最大的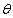 值。
值。
如此循环,直到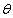 的值不再有太大的变化。
的值不再有太大的变化。
从几何角度讲,EM算法在做神马事情?
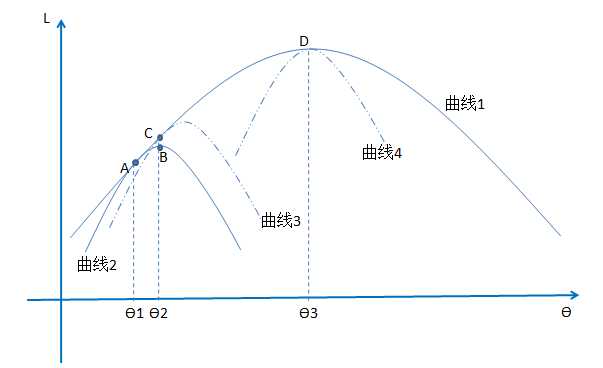
曲线1是(1)式的似然函数曲线。曲线2、3、4是(4)式可能的似然函数曲线。因为(1)式大于等于(4)式,所以曲线2、3、4一定在曲线1的下边。(4)式的曲线随着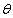 、
、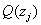 的取值的不同变换着位置。
的取值的不同变换着位置。
那么EM算法每部发生了什么?当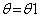 的时候,给定
的时候,给定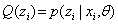 曲线2会和曲线1在A点相交(E步,后边会证明为什么在A点相交)。这时候求得曲线2最值B点对应的
曲线2会和曲线1在A点相交(E步,后边会证明为什么在A点相交)。这时候求得曲线2最值B点对应的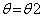 (M步)。这时候EM算法的第一次循环就做完了。然后在
(M步)。这时候EM算法的第一次循环就做完了。然后在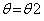 的基础上从新令,这时候曲线3会和曲线1相交在C点(E步),然后我们在求得曲线三的最值(M步)。如此循环,最终我们会走向曲线4,而这时候,曲线4的最值就是曲线1的最值,
的基础上从新令,这时候曲线3会和曲线1相交在C点(E步),然后我们在求得曲线三的最值(M步)。如此循环,最终我们会走向曲线4,而这时候,曲线4的最值就是曲线1的最值,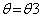 即满足了曲线4取得最值,也让曲线1取得最值。从路径上看,(4)式对应的似然函数曲线会沿着曲线1的边界不断的逼近曲线1的最值。
即满足了曲线4取得最值,也让曲线1取得最值。从路径上看,(4)式对应的似然函数曲线会沿着曲线1的边界不断的逼近曲线1的最值。
到这一步,各位会有的问题是,为什么会让两个曲线有一个交点,而且为什么每次迭代会毕竟真正的最值。
两个证明。
先说,什么时候(1)式和(4)式会相等。如果一个函数是严格的凸函数,回想Jensen不等式会在什么时候相等?只有自变量是常数的情况下才会相等。
那么就有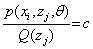 (就是(4)式log函数的自变量),又因为
(就是(4)式log函数的自变量),又因为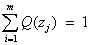 ,所以
,所以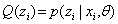 (简单推到下就可以得到结果了)。所以E步可以保证:(4)式和(1)式的曲线有一个交点。
(简单推到下就可以得到结果了)。所以E步可以保证:(4)式和(1)式的曲线有一个交点。
那么,是不是每次跌倒后会有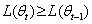 ?也就是说,M步是否具有收敛性。
?也就是说,M步是否具有收敛性。
上图的从几何角度已经给出了一个很直接的答案,这里就不在赘述过程。有兴趣的朋友可以简单推到下。
以上是关于EM算法的主要内容,如果未能解决你的问题,请参考以下文章