Flume-NG源码分析-整体结构及配置载入分析
Posted 世界那么大,我想去看看
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume-NG源码分析-整体结构及配置载入分析相关的知识,希望对你有一定的参考价值。
在 http://flume.apache.org 上下载flume-1.6.0版本,将源码导入到Idea开发工具后如下图所示:
一、主要模块说明
-
flume-ng-channels 里面包含了filechannel,jdbcchannel,kafkachannel,memorychannel通道的实现。
-
flume-ng-clients 实现了log4j相关的几个Appender,使得log4j的日志输出可以直接发送给flume-agent;其中有一个LoadBalancingLog4jAppender的实现,提供了多个flume-agent的load balance和ha功能,采用flume作为日志收集的可以考虑将这个appender引入内部的log4j中。
-
flume-ng-configuration 这个主要就是Flume配置信息相关的类,包括载入flume-config.properties配置文件并解析。其中包括了Source的配置,Sink的配置,Channel的配置,在阅读源码前推荐先梳理这部分关系再看其他部分的。
-
flume-ng-core flume整个核心框架,包括了各个模块的接口以及逻辑关系实现。其中instrumentation是flume内部实现的一套metric机制,metric的变化和维护,其核心也就是在MonitoredCounterGroup中通过一个Map<key, AtomicLong>来实现metric的计量。ng-core下几乎大部分代码任然几种在channel、sink、source几个子目录下,其他目录基本完成一个util和辅助的功能。
-
flume-ng-node 实现启动flume的一些基本类,包括main函数的入口(Application.java中)。在理解configuration之后,从application的main函数入手,可以较快的了解整个flume的代码。
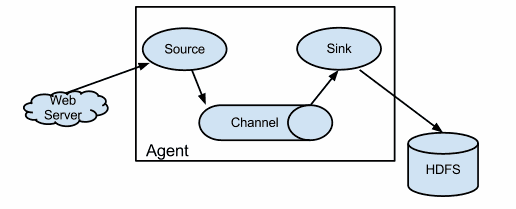
二、Flume逻辑结构图
三、flume-ng启动文件介绍
################################
# constants
################################
#设置常量值,主要是针对不同的参数执行相应的类,以启动Flume环境
FLUME_AGENT_CLASS="org.apache.flume.node.Application"
FLUME_AVRO_CLIENT_CLASS="org.apache.flume.client.avro.AvroCLIClient"
FLUME_VERSION_CLASS="org.apache.flume.tools.VersionInfo"
FLUME_TOOLS_CLASS="org.apache.flume.tools.FlumeToolsMain"
#真正启动Flume环境的方法
run_flume() {
local FLUME_APPLICATION_CLASS
if [ "$#" -gt 0 ]; then
FLUME_APPLICATION_CLASS=$1
shift
else
error "Must specify flume application class" 1
fi
if [ ${CLEAN_FLAG} -ne 0 ]; then
set -x
fi
#执行这一行命令,执行相应的启动类,比如org.apache.flume.node.Application
$EXEC $JAVA_HOME/bin/java $JAVA_OPTS $FLUME_JAVA_OPTS "${arr_java_props[@]}" -cp "$FLUME_CLASSPATH" -Djava.library.path=$FLUME_JAVA_LIBRARY_PATH "$FLUME_APPLICATION_CLASS" $*
}
################################
# main
################################
# set default params
# 在启动的过程中使用到的参数
FLUME_CLASSPATH=""
FLUME_JAVA_LIBRARY_PATH=""
#默认占用堆空间大小,这一块都可以根据JVM进行重新设置
JAVA_OPTS="-Xmx20m"
LD_LIBRARY_PATH=""
opt_conf=""
opt_classpath=""
opt_plugins_dirs=""
arr_java_props=()
arr_java_props_ct=0
opt_dryrun=""
# 根据不同的参数,执行不同的启动类,每个常量所对应的类路径在代码前面有过介绍。
if [ -n "$opt_agent" ] ; then
run_flume $FLUME_AGENT_CLASS $args
elif [ -n "$opt_avro_client" ] ; then
run_flume $FLUME_AVRO_CLIENT_CLASS $args
elif [ -n "${opt_version}" ] ; then
run_flume $FLUME_VERSION_CLASS $args
elif [ -n "${opt_tool}" ] ; then
run_flume $FLUME_TOOLS_CLASS $args
else
error "This message should never appear" 1
fi
这是其中最主要的一部分flume-ng命令行,根据重要性摘取了一段,感兴趣的读者可以自己到bin目录下查看全部。
四、从Flume-NG启动过程开始说起
从bin/flume-ng这个shell脚本可以看到Flume的起始于org.apache.flume.node.Application类,这是flume的main函数所在。
main方法首先会先解析shell命令,如果指定的配置文件不存在就抛出异常。
代码如下所示:
Options options = new Options();
Option option = new Option("n", "name", true, "the name of this agent");
option.setRequired(true);
options.addOption(option);
option = new Option("f", "conf-file", true,
"specify a config file (required if -z missing)");
option.setRequired(false);
options.addOption(option);
option = new Option(null, "no-reload-conf", false,
"do not reload config file if changed");
options.addOption(option);
// Options for Zookeeper
option = new Option("z", "zkConnString", true,
"specify the ZooKeeper connection to use (required if -f missing)");
option.setRequired(false);
options.addOption(option);
option = new Option("p", "zkBasePath", true,
"specify the base path in ZooKeeper for agent configs");
option.setRequired(false);
options.addOption(option);
option = new Option("h", "help", false, "display help text");
options.addOption(option);
#命令行解析类
CommandLineParser parser = new GnuParser();
CommandLine commandLine = parser.parse(options, args);
if (commandLine.hasOption(‘h‘)) {
new HelpFormatter().printHelp("flume-ng agent", options, true);
return;
}
String agentName = commandLine.getOptionValue(‘n‘);
boolean reload = !commandLine.hasOption("no-reload-conf");
if (commandLine.hasOption(‘z‘) || commandLine.hasOption("zkConnString")) {
isZkConfigured = true