flume-ng源码分析-核心组件分析
Posted 17聊技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flume-ng源码分析-核心组件分析相关的知识,希望对你有一定的参考价值。
从第一篇分析可知,flume中所有的组件都会实现LifecycleAware 接口。该接口定义如下:
在组件启动的时候会调用start方法,当有异常时调用stop方法。getLifecycleState 方法返回该组件的状态。包含IDLE, START, STOP, ERROR;
当在组件开发中需要配置一些属性的时候可以实现Configurable接口

下面开始分析Agent中各个组件的实现
source 实现
source定义

可以看到Source 继承了LifecycleAware 接口,并且提供了ChannelProcessor的getter和setter方法,channelProcessor在常用架构篇中讲到提供了日志过滤链,和channel选择的功能。所以Source的逻辑应该都在LifecycleAware中的start,stop方法中。
source创建
在启动篇中,我们讲到了flume是如何启动的。大致流程就是读取配置文件,生成flume的各种组件,执行各个组件的start()方法。在getConfiguration()方法中调用了loadSources()方法。
可以看到在loadSources方法中如何创建Source的


从上面的分析中可以看出,Source是后SourceFactory创建的,创建之后绑定到SourceRunner中,并且在SourceRunner中启动了Source。
SourceFactory只有一个实现DefaultSourceFactory。创建Source过程如下:

在创建重,通过type来或者source类的class。在getClass方法中,首先会去找type对应类型的class。在SourceType中定义的。如果没有找到,则直接获得配置的类全路径。最后通过Class.forName(String)获取class对象。
source提供了两种方式类获取数据:轮训拉去和事件驱动

PollableSource 提供的默认实现如下:
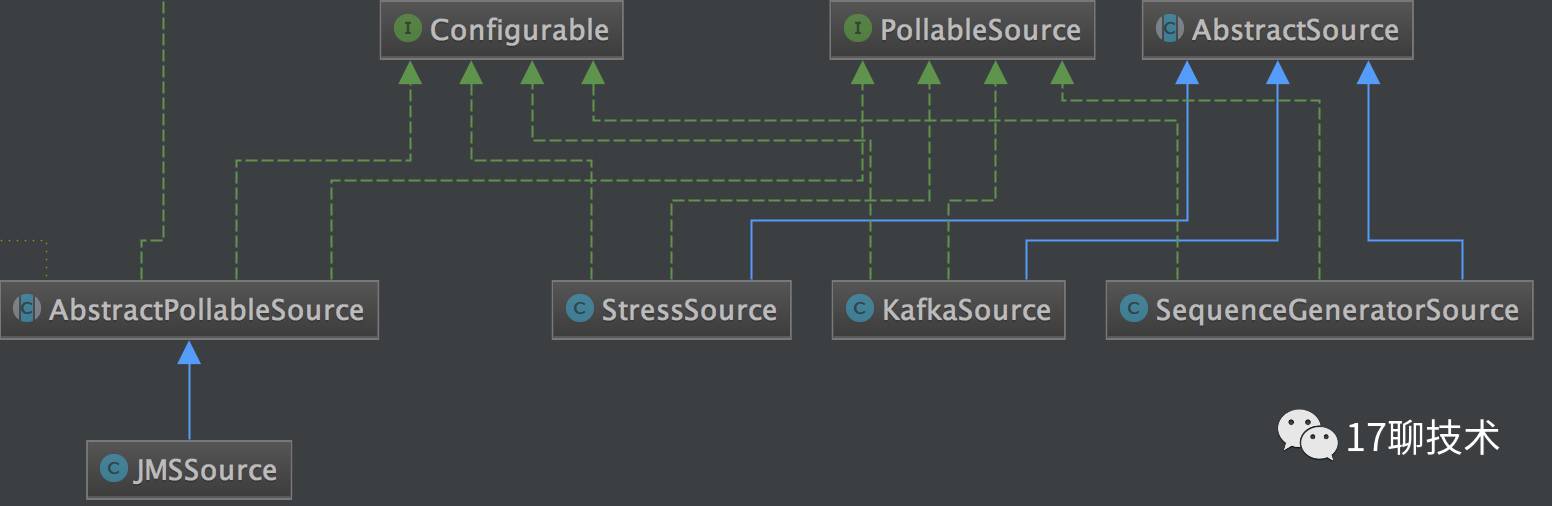
比如KafkaSource 利用Kafka的ConsumerApi,主动去拉去数据。
EventDrivenSource 提供的默认实现如下

如HttpSource,Net catSource就是事件驱动的,所谓事件驱动也就是被动等待。在HttpSource中内置了一个Jetty server,并且设置FlumeHTTPServlet 作为handler去处理数据。
source的启动
从上面的分析中知道,在启动flume读取配置文件时,会将所有的组件封装好,然后再启动。对于Source而言,封装成了SourceRunner,通过SourceRunner间接启动Source。
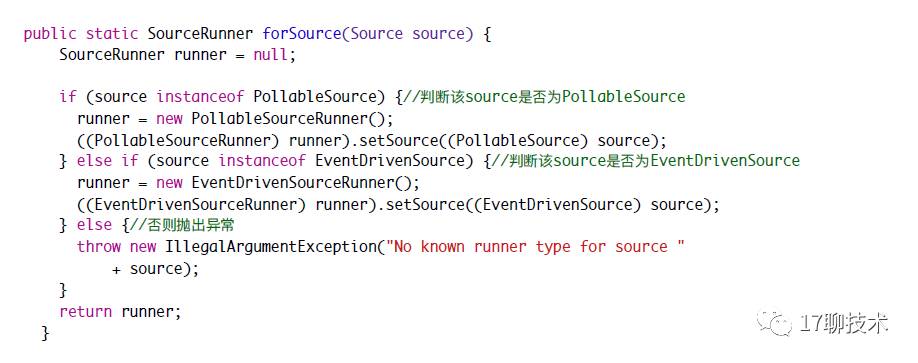
从上面可以看出SourceRunner 默认提供两种实现,PollableSourceRunner ,EventDrivenSource分别对应PollableSource 和EventDrivenSource。
查看PollableSourceRunner是如何启动的

在PollableSourceRunner中我们看到单独启动一个线程去执行PollingRunner,这个线程的作用就是不断的去轮询。
查看PollingRunner的实现

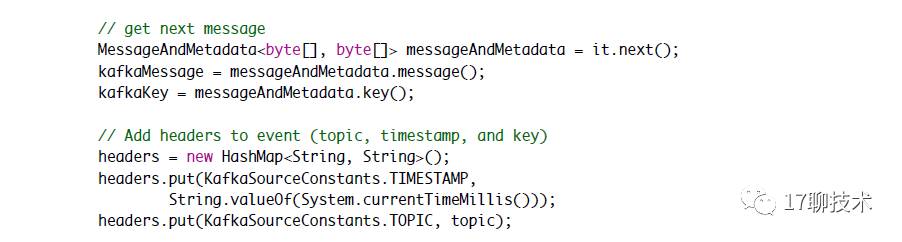
比如KafkaSource ,它的逻辑就在process方法中
EventDrivenSourceRunner

可以看到EventDrivenSourceRunner和PollableSourceRunnner 启动流程大致相同,只是PollableSourceRunner会额外启动一个线程去轮询source。
channel的实现
source 获取到数据后,会交给channelProcessor处理,发送到channel。最后由sink消费掉。所以channel是source,sink实现异步化的关键。
channelProcessor 中两个重要的成员
private final ChannelSelector selector;//channel选择器器
private final InterceptorChain interceptorChain; //过滤链
InterceptorChain 是由多个Interceptor组成,并且实现了Interceptor接口

Interceptor.java
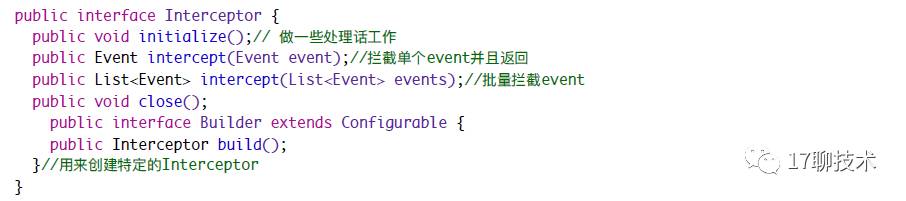
Interceptor定义了一些处理Event的接口,再Event处理之后都会返回改Envent
从source的分析中我们可以知道,如果是PollableSourceRunner会调用source 中的process()方法。如果是EventDrivenSourceRunner,就会用特定的方法来获取source,比如httpSource 利用FlumeHTTPServlet来接受消息。

比如KafkaSource 是PollableSourceRunner 那么会调用KafkaSource中的process()方法。
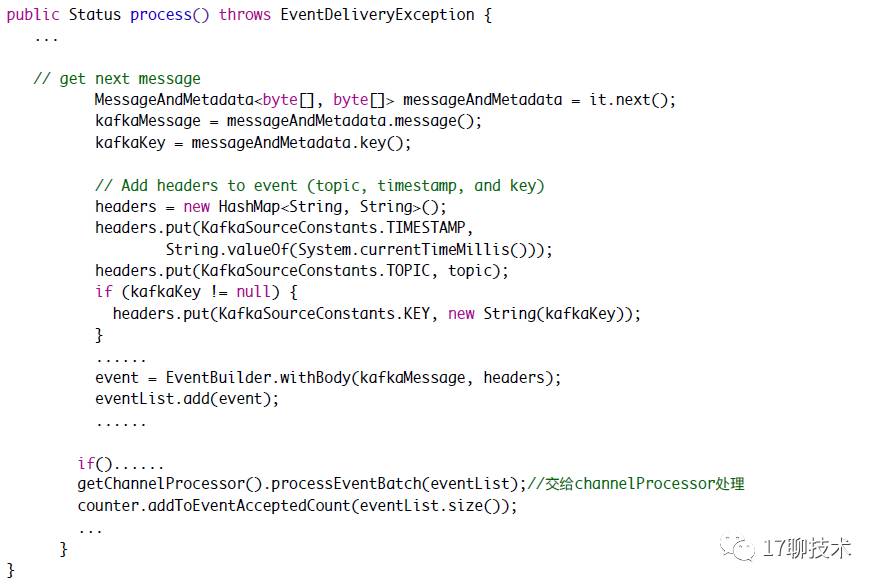
从以上分析不管source是轮询还是事件驱动的,都会触发ChannelProcessor中的processEvent或者ProcesEventBatch方法
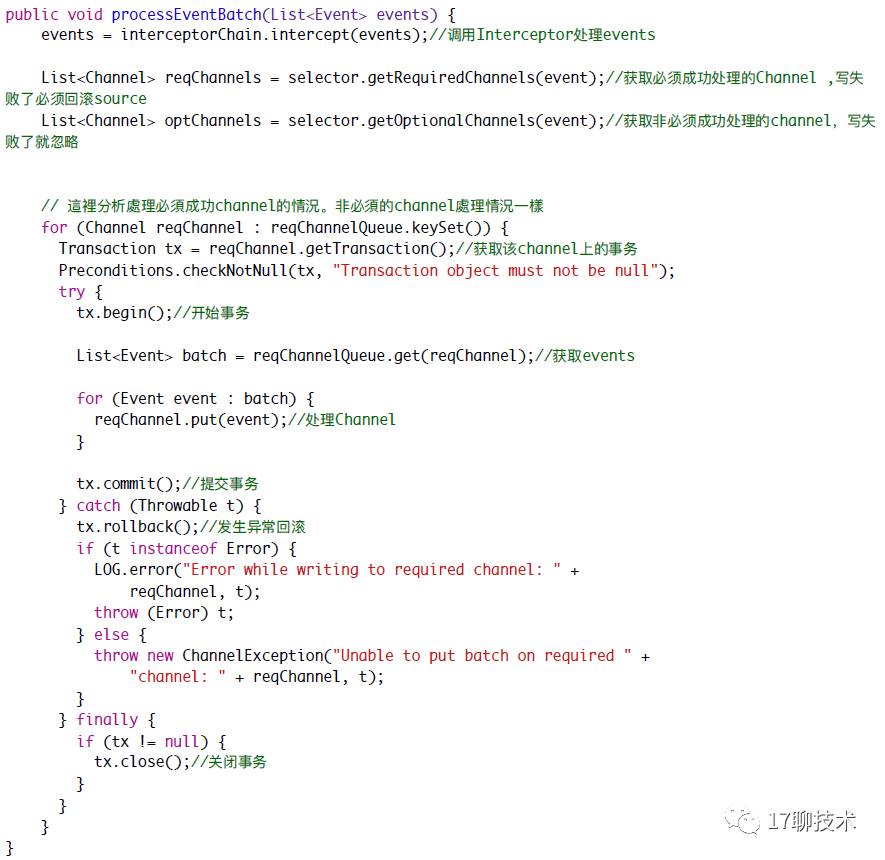
最后就是ChannelSelector ,flume默认提供两种实现多路复用和复制。多路复用选择器可以根据header中的值而选择不同的channel,复制就会把event复制到多个channel中。flume默认是复制选择器。
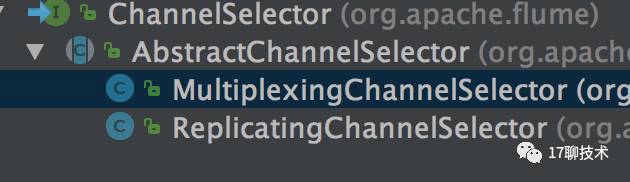
同样Selector的创建也是通过ChannelSelectorFactory创建的。
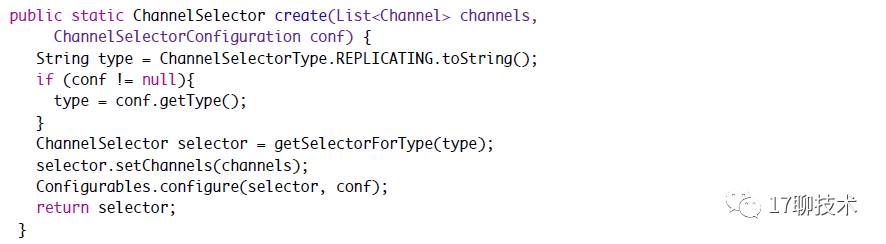
默认提供复制选择器,如果配置文件中配置了选择器那么就从配置文件中获取。
上面看到在processEventBatch 方法中调用channel的put方法。channel中提供了基本的
put和take方法来实现Event的流转。

flume提供的默认channel如下图所示:

sink的实现
sink的定义:

提供了channel的setter,getter方法。process方法用来消费。并返回状态READY,BACKOFF
sink的创建

sink的创建也是通过sinkFactory
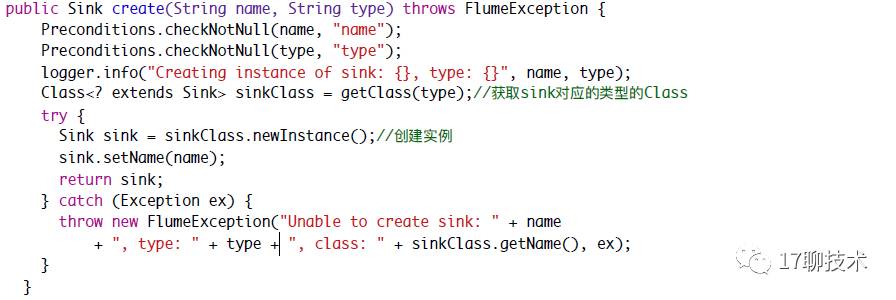
通过传入的type找到对应的Class 要是没有找到则直接通过Class.forNamae(String name)来创建sink还提供了分组功能。该功能由SinkGroup实现。在SinkGroup内部如何调度多个Sink,则交给SinkProcessor完成。
sink的启动
和Source一样,flume也为Sink提供了SinkRunner来流转Sink
在sinkRunner中
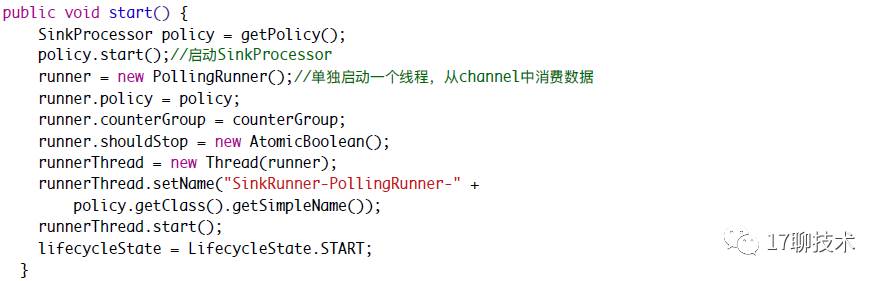
sinkRunner中通过启动SinkProcessor 间接启动Sink,并且单独启动一个线程,不停地调用process()方法从channel中消费数据
在SinkProcessor中,如果是DefaultSinkProcessor 那么直接调用sink.start()方法启动sink。如果是LoadBalancingSinkProcessor,FailoverSinkProcessor由于这两种处理器中包含多个Sink,所以会依次遍历sink
调用start()方法启动

该线程会不停的执行SinkProcessor的process()方法,而SinkProcessor的process()方法会调用对应的Sink的process()方法。然后判断处理状态如果是失败补偿,那么等待超时时间后重试
SinkGroup

SinkGroup中包含多个Sink,并且提供一个SinkProcessor来处理SinkGroup内部调度
SinkProcessor
SinkProcessor 默认提供三种实现。
DefaultSinkProcessor,LoadBalancingSinkProcessor,FailoverSinkProcessor
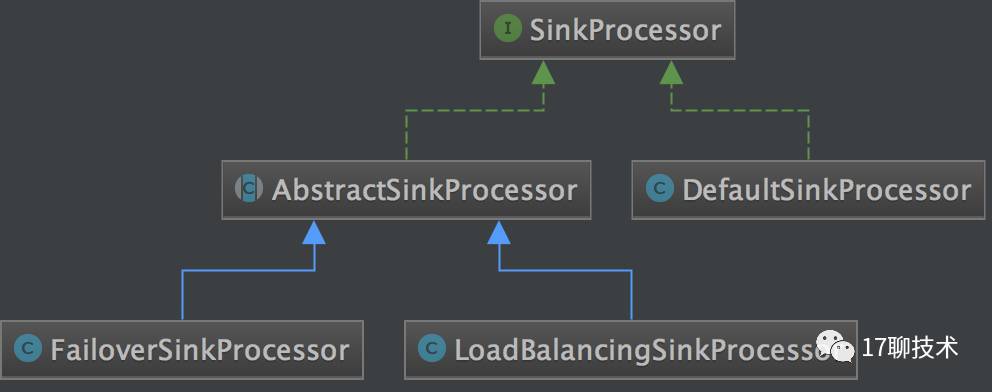
DefaultSinkProcessor:默认实现,适用于单个sink
LoadBalancingSinkProcessor:提供负载均衡
FailoverSinkProcessor:提供故障转移
DefaultSinkProcessor
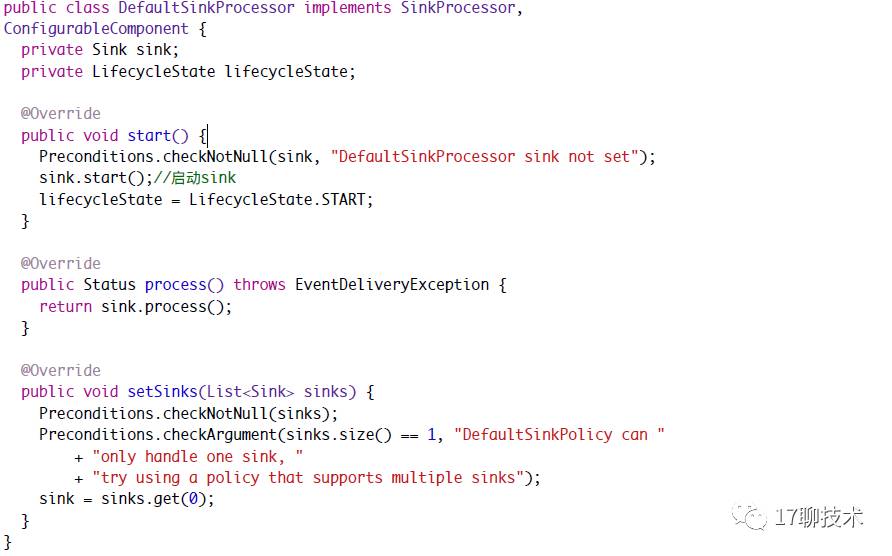
从上面可以看出DefaultSinkProcessor 只能处理一个Sink。在process方法中调用sink的方法。具体到某个具体的Sink,比如HDFSEventSink,那么就执行该sink的process方法
接下来分析SinkProcessor中负载均衡和故障转移 是如何具体实现的。
FailOverSinkProcessor 实现分析
FailOverSinkProcessor 中process()方法实现如下:

存活队列是一个SortMap 其中key是sink的优先级。activeSink 默认取存活队列中的最后一个,存活队列是根据配置的sink优先级来排序的
失败队列是一个优先队列,按照FailSink的refresh属性进行排序

refresh 属性,在FailSink创建时和sink 处理发生异常时 会触发调整
refresh 调整策略 如下:

refresh 等于系统当前的毫秒加上最大等待时间(默认30s)和失败次数指数级增长值中最小的一个。
FAILURE_PENALTY等于1s;(1 << sequentialFailures) * FAILURE_PENALTY)用于实现根据失败次数等待时间指数级递增。
一个配置的failOver具体的例子:
host1.sinkgroups = group1
host1.sinkgroups.group1.sinks = sink1 sink2
host1.sinkgroups.group1.processor.type = failover
host1.sinkgroups.group1.processor.priority.sink1 = 5
host1.sinkgroups.group1.processor.priority.sink2 = 10
host1.sinkgroups.group1.processor.maxpenalty = 10000
LoadBalancingSinkProcessor实现分析
loadBalaneingSinkProcessor 用于实现sink的负载均衡,其功能通过SinkSelector实现。类似于ChannelSelector和Channel的关系
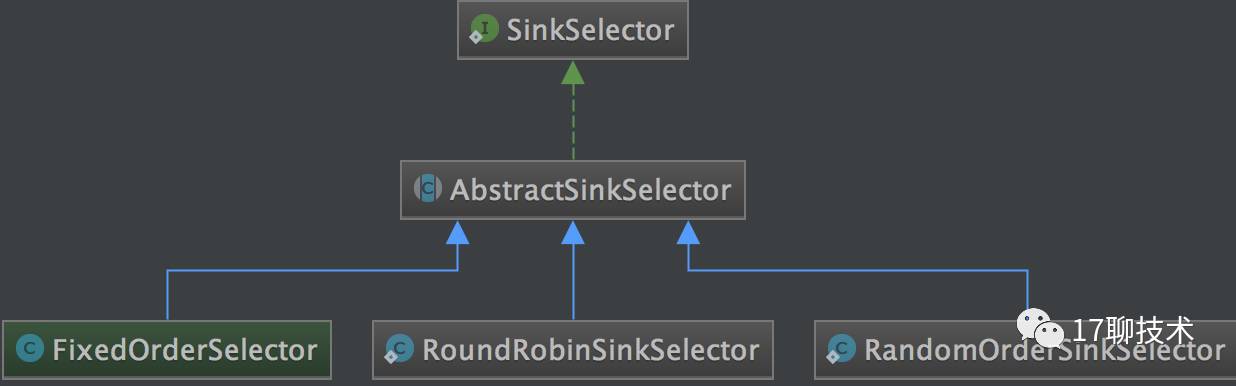
SinkSelector中模式有三种实现
1.固定顺序
2.轮询
3.随机
LoadBalancingSinkProcessor 中使用均衡负载的方式

在上面的解释中,最大的两个疑惑就是:
这个Sink迭代器也就是createSinkIterator() 是如何实现的
发生异常后SinkSelector的处理是如何实现的
先来看createSinkIterator 的实现。首先看RoundRobinSinkSelector的实现

如上图所示RoundRobinSinkSelector 内部包含一个OrderSelector的属性。
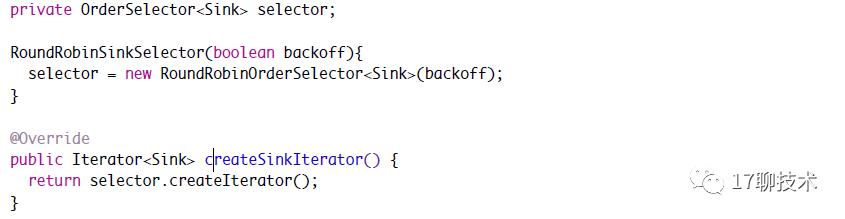
内部通过一个RoundRobinOrderSelector 来实现。查看起createIterator实现

接下来看一下getIndexList 的实现
stateMap是一个LinkedHashMap其中T在这里指的是Sink。
如果没有开启了退避算法,那么会认为每个sink都是存活的,所有的sink都加到IndexList。否则等到了失败补偿时间才会加入到IndexList。可以通过processor.backoff = true配置开启
最后分析一下当sink处理失败SinkSelector是如何处理的
CONSIDER_SEQUENTIAL_RANGE 是一个常量 只为1小时。
EXP_BACKOFF_COUNTER_LIMIT 为期望最大的退避次数,值为16。如果上次失败到现在的是哪在上次退避等待时间超过一个小时后 或者 退避次数超过EXP_BACKOFF_COUN
TER_LIMIT 那么退避的等待时间将不再增加。
以上是关于flume-ng源码分析-核心组件分析的主要内容,如果未能解决你的问题,请参考以下文章