并行编程入门
Posted 安然_随心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并行编程入门相关的知识,希望对你有一定的参考价值。
目录
- 并行编程简介
- MapReduce
2.1 MapReduce简介
2.2 MapReduce框架
2.3 Hadoop介绍
2.4 Hadoop基本类
2.5 Hadoop编程实例
#1.并行编程简介
##1.1.并行编程作用,用途
商业用途,科学计算,大数据分析
##1.2.并行编程兴起原因
目前的串行编程的局限性
使用的流水线等隐式并行模式的局限性
硬件的发展
##1.3.并行算法设计原则步骤
a.分析问题
b.分解问题
其中分解方法有:
数据分解
递归分解
探测性分解
推测性分解
混合分解
c.根据分解方法,产生任务
d.将任务映射到处理器上
e.要注意的问题:
减少任务之间的交互(任务粒度,任务的依赖)
负载均衡(静态均衡和动态均衡)
###1.4并行算法模型
数据并行模型
任务图模型
工作池模型(任一个任务可映射到任一个处理器上)
主-从模型
###
##1.5.基本通信操作(单端口,双向)
对于不同的操作,对于不同的设备模型,有如下几种组合:
a.一对多广播及多对一归约(一传到二,然后二传到4)
环或线性阵列:
格网:
超立方体:
b.多对多广播 及 多对多归约
环或线性阵列:
格网:
超立方体:
d.全归约 及 前缀和
环或线性阵列:
格网:
超立方体:
e.散发及 收集归约
环或线性阵列:
格网:
超立方体:
f.循环移位
环或线性阵列:
格网:
超立方体:
##1.6.解析建模
模型需要考虑的因素有:
- 开销分析
- 性能度量
执行时间,加速比,总并行开销,效率,成本 - 粒度影响
- 系统可扩展性
###1.7使用消息传递模式编程
使用MPI API 进行编程
MPI,消息传递接口
int MPI_Init(int *argc,char ***grgv)
int MPI_Finalize()
int MPI_Comm_size(MPI_Comm comm,int * size):用size返回comm域中进程数目
int MPI_Comm_rank(MPI_Comm comm,int * rank):用rank返回comm域中进程等级(0-size-1)
int MPI_Send(void buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_comm comm);
int MPI_Recv(void buf,int count,MPI_Datatype datatype,int source,int tag,MPI_comm comm,MPI_status status);
int MPI_Get_count(MPI_Status *status, MPI_Datatype datatype, int *count)
###
#2.MapReduce
参考文献:
http://www.open-open.com/lib/view/open1328763069203.html
http://www.wnt.com.cn/html/news/tophome/top_xytd/top_xytd_jswz/bbs_service/20130711/111140562.html
http://blog.csdn.net/geekcome/article/details/9024419
http://www.cnblogs.com/biyeymyhjob/archive/2012/08/12/2633608.html
http://www.educity.cn/wenda/578905.html
http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop1/#ibm-pcon
http://wiki.apache.org/hadoop/
http://hadoop.apache.org/
http://research.google.com/archive/mapreduce-osdi04.pdf
IBM Hadoop分布式并行编程系列:
第一部分:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop1/
第二部分:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop2/
第三部分:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop3/
http://www.educity.cn/wenda/578905.html
http://datalife.iteye.com/blog/930318
##2.1MapReduce简介
MapReduce 是 Google 公司的核心计算模型,它将复杂的运行于大规模集群上的并行计算过程高度的抽象到了两个函数,Map 和 Reduce, 这是一个令人惊讶的简单却又威力巨大的模型。适合用 MapReduce 来处理的数据集(或任务)有一个基本要求: 待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理

计算模型的核心是 Map 和 Reduce 两个函数,这两个函数由用户负责实现,功能是按一定的映射规则将输入的 <key, value> 对转换成另一个或一批 <key, value> 对输出。

以一个计算文本文件中每个单词出现的次数的程序为例,<k1,v1> 可以是 <行在文件中的偏移位置, 文件中的一行>,经 Map 函数映射之后,形成一批中间结果 <单词,出现次数>, 而 Reduce 函数则可以对中间结果进行处理,将相同单词的出现次数进行累加,得到每个单词的总的出现次数。
基于 MapReduce 计算模型编写分布式并行程序非常简单,程序员的主要编码工作就是实现 Map 和 Reduce 函数,其它的并行编程中的种种复杂问题,如分布式存储,工作调度,负载平衡,容错处理,网络通信等,均由 MapReduce 框架(比如 Hadoop )负责处理,程序员完全不用操心。
##2.2 MapReduce框架
### 2.2.1运行架构图
如下: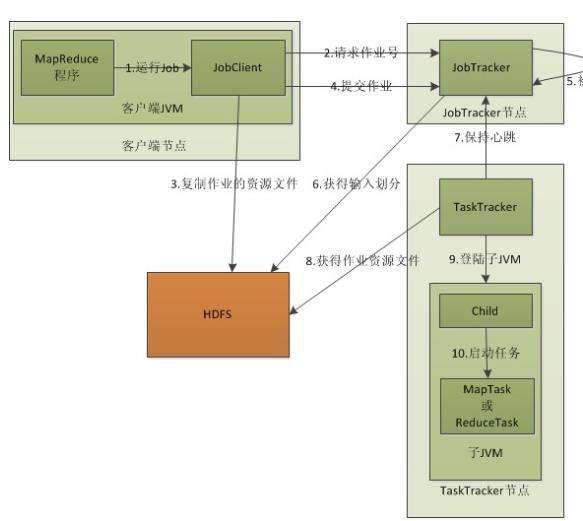
### 2.2.流程分析
1.在客户端启动一个作业。
2.向JobTracker请求一个Job ID。
3.将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息(输入划分信息?)。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4.JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度(这里是不是很像微机中的进程调度呢,呵呵),当作业调度器根据自己的调度算法调度到该作业时,**会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。**这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
5.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
以上是在客户端、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,下面我们再细致一点,从map任务和reduce任务的层次来分析分析吧。
### 2.2.2.Map、Reduce任务中Shuffle和排序的过程
流程分析:
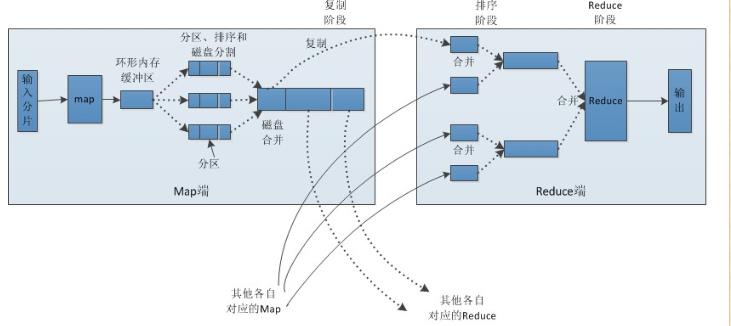
Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的过程呢?呵呵。
Reduce端:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数
##2.3 Hadoop简介
###2.3.1 Hadoop是什么
MapReduce的一个开源实现
### 2.3.2数据分布存储
Hadoop 中的分布式文件系统 HDFS 由一个管理结点 ( NameNode )和N个数据结点 ( DataNode )组成,每个结点均是一台普通的计算机。在使用上同我们熟悉的单机上的文件系统非常类似,一样可以建目录,创建,复制,删除文件,查看文件内容等。但其底层实现上是把文件切割成 Block,然后这些 Block 分散地存储于不同的 DataNode 上,每个 Block 还可以复制数份存储于不同的 DataNode 上,达到容错容灾之目的。NameNode 则是整个 HDFS 的核心,它通过维护一些数据结构,记录了每一个文件被切割成了多少个 Block,这些 Block 可以从哪些 DataNode 中获得,各个 DataNode 的状态等重要信息。
###2.3.3 分布式并行计算
Hadoop 中有一个作为主控的 JobTracker,用于调度和管理其它的 TaskTracker, JobTracker 可以运行于集群中任一台计算机上。TaskTracker 负责执行任务,必须运行于 DataNode 上,即 DataNode 既是数据存储结点,也是计算结点。 JobTracker 将 Map 任务和 Reduce 任务分发给空闲的 TaskTracker, 让这些任务并行运行,并负责监控任务的运行情况。如果某一个 TaskTracker 出故障了,JobTracker 会将其负责的任务转交给另一个空闲的 TaskTracker 重新运行。
###2.3.4 本地计算
数据存储在哪一台计算机上,就由这台计算机进行这部分数据的计算,这样可以减少数据在网络上的传输,降低对网络带宽的需求。在 Hadoop 这样的基于集群的分布式并行系统中,计算结点可以很方便地扩充,而因它所能够提供的计算能力近乎是无限的,但是由是数据需要在不同的计算机之间流动,故网络带宽变成了瓶颈,是非常宝贵的,“本地计算”是最有效的一种节约网络带宽的手段,业界把这形容为“移动计算比移动数据更经济”。

###2.3.5 任务粒度
把原始大数据集切割成小数据集时,通常让小数据集小于或等于 HDFS 中一个 Block 的大小(缺省是 64M),这样能够保证一个小数据集位于一台计算机上,便于本地计算。有 M 个小数据集待处理,就启动 M 个 Map 任务,注意这 M 个 Map 任务分布于 N 台计算机上并行运行,Reduce 任务的数量 R 则可由用户指定。
###2.3.6 Partition
把 Map 任务输出的中间结果按 key 的范围划分成 R 份( R 是预先定义的 Reduce 任务的个数),划分时通常使用 hash 函数如: hash(key) mod R,这样可以保证某一段范围内的 key,一定是由一个 Reduce 任务来处理,可以简化 Reduce 的过程。
###2.3.7 Combine
在 partition 之前,还可以对中间结果先做 combine,即将中间结果中有相同 key的 <key, value> 对合并成一对。combine 的过程与 Reduce 的过程类似,很多情况下就可以直接使用 Reduce 函数,但 combine 是作为 Map 任务的一部分,在执行完 Map 函数后紧接着执行的。Combine 能够减少中间结果中 <key, value> 对的数目,从而减少网络流量。
###2.3.8 Reduce 任务从 Map 任务结点取中间结果
Map 任务的中间结果在做完 Combine 和 Partition 之后,以文件形式存于本地磁盘。中间结果文件的位置会通知主控 JobTracker, JobTracker 再通知 Reduce 任务到哪一个 DataNode 上去取中间结果。注意所有的 Map 任务产生中间结果均按其 Key 用同一个 Hash 函数划分成了 R 份,R 个 Reduce 任务各自负责一段 Key 区间。每个 Reduce 需要向许多个 Map 任务结点取得落在其负责的 Key 区间内的中间结果,然后执行 Reduce 函数,形成一个最终的结果文件。
###2.3.9 任务管道
有 R 个 Reduce 任务,就会有 R 个最终结果,很多情况下这 R 个最终结果并不需要合并成一个最终结果。因为这 R 个最终结果又可以做为另一个计算任务的输入,开始另一个并行计算任务
###2.3.10
##2.4Hadoop基本类
###2.4. 1 InputFormat类
该类的作用是将输入的文件和数据分割成许多小的split文件,并将split的每个行通过LineRecorderReader解析成<Key,Value>,通过job.setInputFromatClass()函数来设置,默认的情况为类TextInputFormat,其中Key默认为字符偏移量,value是该行的值。
###2.4.2.Map类
根据输入的<Key,Value>对生成中间结果,默认的情况下使用Mapper类,该类将输入的<Key,Value>对原封不动的作为中间按结果输出,通过job.setMapperClass()实现。实现Map函数。
###2.4.3.Combine类
实现combine函数,该类的主要功能是合并相同的key键,通过job.setCombinerClass()方法设置,默认为null,不合并中间结果。实现map函数
###2.4.4.Partitioner类
该该主要在Shuffle过程中按照Key值将中间结果分成R份,其中每份都有一个Reduce去负责,可以通过job.setPartitionerClass()方法进行设置,默认的使用hashPartitioner类。实现getPartition函数
###2.4.5.Reducer类
将中间结果合并,得到中间结果。通过job.setReduceCalss()方法进行设置,默认使用Reducer类,实现reduce方法。
###2.4. 6.OutPutFormat类
该类负责输出结果的格式。可以通过job.setOutputFormatClass()方法进行设置。默认使用TextOUtputFormat类,得到<Key,value>对。
hadoop主要是上面的六个类进行mapreduce操作,使用默认的类,处理的数据和文本的能力很有限,具体的项目中,用户通过改写这六个类(重载六个类),完成项目的需求。说实话,我刚开始学的时候,我怀疑过Mapreudce处理数据功能,随着学习深入,真的很钦佩mapreduce的设计,基本就二个函数,通过重载,可以完成所有你想完成的工作
##2.5Hadoop编程实例
###2.5.1 环境搭建
Cygwin 安装配置
1. 下载Cygwin安装文件
2. 运行安装文件,选择一个下载站点,继续
3. 选择要安装的程序,默认是不安装某些组件,需要手动选择
Net Category下的:openssh,openssl
BaseCategory下的:sed (若需要Eclipse,必须sed)
Devel Category下的:subversion(建议安装)
4. 等待下载并完成安装,之后,设置环境变量,把 C:/cygwin/bin;C:/cygwin/usr/bin 加入到系统环境变量的Path中
5. 打开cygwin,输入 ssh-host-config
当询问if privilege separation should be used 时输入 no .
当询问if sshd should be installed as a service 时输入yes .
当询问about the value of CYGWIN environment variable enter 时输入 ntsec .
其余询问均输入 no
ps:如果电脑上没有 有密码的帐号,配置会不成功。此时,应该创建一个windows 带密码的帐号,也可以通过该配置界面创建一个
6. 打开 控制面板-》管理-》服务 启动名为 CYGWIN sshd 的服务,亦可在cygwin中输入 cygrunsrv --start sshd 启动sshd,
输入cygrunsrv --stop sshd停止sshd
7. 打开cygwin,输入 ssh-keygen,当询问要filenames 和 pass phrases 的时候都点回车,接受默认的值
8. 命令结束后输入 cd ~/.ssh 转到.ssh目录,输入 ls –l 应该包含两个文件:id_rsa.pub 和 id_rsa
9. 在第8步的窗口(当前目录在.ssh)中输入 cat id_rsa.pub >> authorized_keys
10. 输入 ssh localhost 启动SSH
PS:对于window64位系统,开始我安装的是对应的64位的Cygwin,但是配置不成功,会出现如下错误。删除后,重新安装32位的cygwin后,就好了
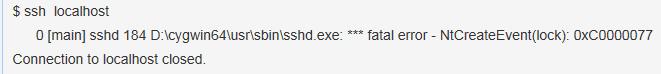
在cygwin中开启停用删除服务的命令:
开启服务: $ net start 服务名
停止服务: $ net stop 服务名
删除服务: $ cygrunsrv -R 服务名
cygwin自带的命令:
检查所有安装的软件的版本号: $ cygcheck -c
检查当前Cygwin的版本号: $ cygcheck -c cygwin
cygwin编译搭建hadoop环境需要安装的软件包:
1.openssh
2.openssl
3.sed
4.zlib
4.tcp_wrappers
5.diffutils
6.vim
7.subversion
cygwin没有自动卸载功能,需要手动操作3个步骤如下:
1.停止服务: $ net stop 服务名
2.删除服务: $ cygrunsrv -R 服务名
3.删除cygwin文件
伪分布模式配置
可以把伪分布模式看作是只有一个节点的集群,在这个集群中,这个节点既是Master,也是Slave,既是NameNode,也是DataNode,既是JobTracker,也是TaskTracker
这种模式也是在一台单机上运行,但用不同的 Java 进程模仿分布式运行中的各类结点 ( NameNode, DataNode, JobTracker, TaskTracker, Secondary NameNode ),请注意分布式运行中的这几个结点的区别:
从分布式存储的角度来说,集群中的结点由一个 NameNode 和若干个 DataNode 组成, 另有一个 Secondary NameNode 作为 NameNode 的备份。 从分布式应用的角度来说,集群中的结点由一个 JobTracker 和若干个 TaskTracker 组成,JobTracker 负责任务的调度,TaskTracker 负责并行执行任务。TaskTracker 必须运行在 DataNode 上,这样便于数据的本地计算。JobTracker 和 NameNode 则无须在同一台机器上
hadoop配置文件详解、安装及相关操作
http://blog.csdn.net/lin_fs/article/details/7349497
http://blog.csdn.net/ruby97/article/details/7423088
注意事项:
对于配置文件的更改,我开始是直接在window下打开修改的,结果出现如下错误:
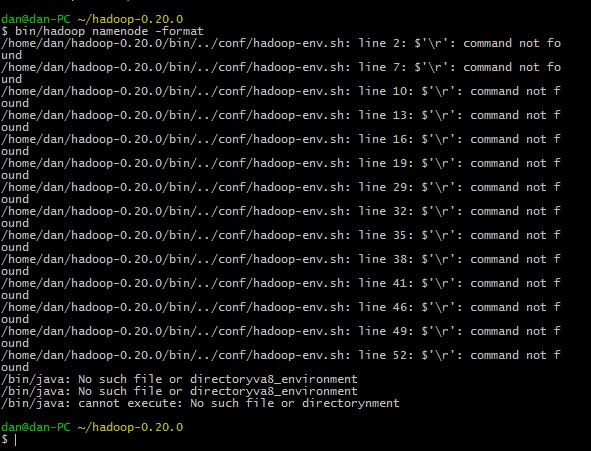
原因:在windows下打开修改后,会更改文件的编码方式,使得文件在linux环境下读取错误问题
解决办法:
1.使用utraedit工具打开后,转换成Linux编码方式
2.重新操作,在复制后,不在window下修改,直接在Linux中用vim编辑器打开修改(需要了解vim命令)
改完之后,重新操作,结果如下:
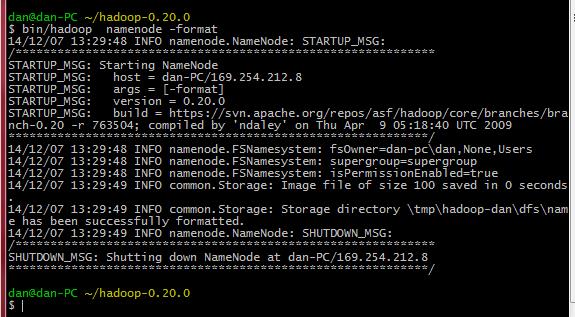
关于错误:ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 0 time(s).的错误。hadoop安装完成
用jps命令,也看不不到namenode的进程, 必须再用命令hadoop namenode format格式化后,才能再使用
原因是:hadoop默认配置是把一些tmp文件放在/tmp目录下,重启系统后,tmp目录下的东西被清除,所以报错
解决方法:在conf/core-site.xml (0.19.2版本的为conf/hadoop-site.xml)中增加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
<description>A base for other temporary directories</description>
</property>
重启hadoop后,格式化namenode即可
测试配置是否成功
浏览器下查看Hadoop系统情况的地址。
http://127.0.0.1:50070/ HDFS情况
http://127.0.0.1:50060/ Task Tracker 情况
http://127.0.0.1:50030/ Job Tracker-Map/Reduce Administration

- 启动hdfs
进入hadoop目录,在bin/下面有很多启动脚本,可以根据自己的需要来启动。
- start-all.sh 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack
- stop-all.sh 停止所有的Hadoop
- start-mapred.sh 启动Map/Reduce守护。包括Jobtracker和Tasktrack
- stop-mapred.sh 停止Map/Reduce守护
- start-dfs.sh 启动Hadoop DFS守护Namenode和Datanode
- stop-dfs.sh 停止DFS守护
三、Hadoop hdfs 整合
可按如下步骤删除和更改hdfs不需要的文件:
1.将hadoop-core-1.0.0.jar 移动到lib目录下。
2. 将ibexec目录下的文件移动到bin目录下。
3. 删除除bin、lib、conf、logs之外的所有目录和文件。
4. 如果需要修改日志存储路径,则需要在conf/hadoop-env.sh文件中增加:
export HADOOP_LOG_DIR=/home/xxxx/xxxx即可。
四、HDFS文件操作
Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似。并且支持通配符,如*。
-
查看文件列表
查看hdfs中/user/admin/hdfs目录下的文件:bin/hadoop fs -ls /user/admin/hdfs
查看hdfs中/user/admin/hdfs目录下的所有文件(包括子目录下的文件):bin/hadoop fs -lsr /user/admin/hdfs -
创建文件目录
新建一个叫做newDir的新目录:bin/hadoop fs -mkdir /user/admin/hdfs/newDir -
删除hdfs中/user/admin/hdfs目录下一个名叫needDelete的文件: bin/hadoop fs -rm /user/admin/hdfs/needDelete
删除hdfs中/user/admin/hdfs目录以及该目录下的所有文件:bin/hadoop fs -rmr /user/admin/hdfs -
上传文件
上传一个本机/home/admin/newFile的文件到hdfs中/user/admin/hdfs目录下
sh bin/hadoop fs –put /home/admin/newFile /user/admin/hdfs/ -
下载文件
下载hdfs中/user/admin/hdfs目录下的newFile文件到本机/home/admin/newFile中
执行sh bin/hadoop fs –get /user/admin/hdfs/newFile /home/admin/newFile -
查看hdfs中/user/admin/hdfs目录下的newFile文件
bin/hadoop fs –cat /home/admin/newFile
7.学习各种 HDFS 命令的使用:bin/hadoop dfs –help 可以
###2.5. 3 运行 wordcount 应用
1.将本地文件系统上的 ./test-in 目录拷到 HDFS 的根目录上,目录名改为 input
$ bin/hadoop dfs -put test input
2.查看执行结果,将文件从 HDFS 拷到本地文件系统中再查看:
$ bin/hadoop jar hadoop-0.20.0-examples.jar wordcount input output
$ bin/hadoop dfs -get output output
$ cat output/*
也可以直接查看
$ bin/hadoop dfs -cat output/*
$ bin/stop-all.sh #停止 hadoop 进程
###2.5.4 eclipse编程环境搭建
http://www.cnblogs.com/flyoung2008/archive/2011/12/09/2281400.html
以上是关于并行编程入门的主要内容,如果未能解决你的问题,请参考以下文章
虚幻4与现代C++:基于任务的并行编程与TaskGraph入门