实验1 词法分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验1 词法分析相关的知识,希望对你有一定的参考价值。
|
格式说明:排版时注意按此模板的字体,字号和行距。 报告提交和打印输出时请去掉此框。 |
实验一、词法分析实验
商软1班 周展鹏 201506110114
一、 实验目的
通过设计一个词法分析程序,对词法进行分析,加强对词法的理解,掌握对程序设计语言的分解和理解。
二、 实验内容和要求
在原程序中输入源代码
- 对字符串表示的源程序
- 从左到右进行扫描和分解
- 根据词法规则
- 识别出一个一个具有独立意义的单词符号
- 以供语法分析之用
- 发现词法错误,则返回出错信息
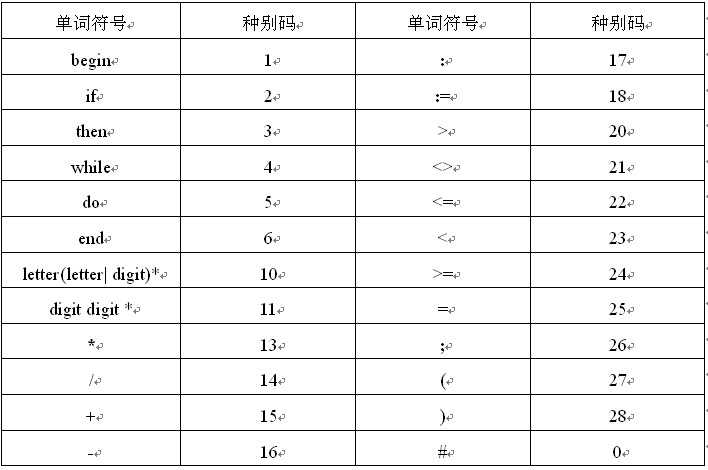
在源程序中,自动识别单词,把单词分为五种,并输出对应的单词种别码。
(1) 关键字 是由程序语言定义的具有固定意义的标识符。例如,Pascal 中的begin,end,if,while都是保留字。这些字通常不用作一般标识符。
(2) 标识符 用来表示各种名字,如变量名,数组名,过程名等等。
(3) 常数 常数的类型一般有整型、实型、布尔型、文字型等。
(4) 运算符 如+、-、*、/等等。
(5) 界符 如逗号、分号、括号、等等。
各种单词符号对应的种别码。
输出形式:
- 二元式
– (单词种别,单词自身的值)
- 单词种别,表明单词的种类,语法分析需要的重要信息
– 整数码
- 关键字、运算符、界符:一符一码
- 标识符:10, 常数:11
- 单词自身的值
三、 实验方法、步骤及结果测试
- 1. 源程序名:压缩包文件(rar或zip)中源程序名×××.c
可执行程序名:×××.exe
- 2. 原理分析及流程图
主要总体设计问题。
(包括存储结构,主要算法,关键函数的实现等)
- 3. 主要程序段及其解释:
实现主要功能的程序段,重要的是程序的注释解释。
package CompilePrograme;
import java.awt.List;
import java.util.Scanner;
public class Compile {
public static void main(String[] args) {
// TODO Auto-generated method stub
double startTime = System.currentTimeMillis();
final int MAX_LEN = 100;
Scanner input = new Scanner(System.in);
System.out.print("Please input a string <end with ‘#‘>:");
String uString = input.nextLine();
input.close();
String[] keyWords = new String[] { "begin", "if", "then", "while", "do", "end" };
char[] analyseData = new char[MAX_LEN];
int index = 0, key = 0;
List list = new List();
do {
String compareStr = null;
char temp = uString.charAt(index);
list = extactCharacters(temp, analyseData, keyWords, uString, index, compareStr);
if (list.getItemCount() == 0) {
index++;
continue;
}
// 规定List的第一个元素为index,第二个元素为key
index = Integer.parseInt(list.getItem(0));
key = Integer.parseInt(list.getItem(1));
String words = list.getItem(2);
System.out.println("< " + key + " ," + words + " >");
} while (key != 0);
double endTime = System.currentTimeMillis();
System.out.println("\\nProgram running time is :" + (endTime - startTime));
}
public static List extactCharacters(char temp, char[] analyseDate, String[] keywords, String uString, int index,
String compareStr) {
int keyID = -1, m = 0;
// index--;
List list = new List();
// 1.判断下一个读入的字符是否为空格,用while作为大循环,若读取到空格则跳出方法,提取下一个字符进行判断
while (temp != ‘ ‘) {
// 2.判断当前字符是字母或者数字和字母的组合
if (temp >= ‘a‘ && temp <= ‘z‘) {
m = 0;
// 当读取到不是大小写字母或者数字时候判断为一个单词读取完成
while (temp >= ‘a‘ && temp <= ‘z‘ || temp >= ‘A‘ && temp <= ‘Z‘ || temp >= ‘0‘ && temp <= ‘9‘) {
analyseDate[m++] = temp;
compareStr += temp + "";
temp = uString.charAt(++index);
}
compareStr = compareStr.substring(4);
// 与读取出来的字符判断是否为关键字
for (int i = 0; i < 6; i++) {
if (compareStr.equals(keywords[i])) {
keyID = i + 1;
list.add(index + "");
list.add(keyID + "");
list.add(compareStr);
return list;
}
}
// 不是关键字就当作为标识符
keyID = 10;
list.add(index + "");
list.add(keyID + "");
list.add(compareStr);
return list;
}
// 3,判断当前字符是数字?
else if (temp >= ‘0‘ && temp <= ‘9‘) {
m = 0;
String tempTokens = null;
// 对后面的字符进行判断是否为数字
while (temp >= ‘0‘ && temp <= ‘9‘) {
analyseDate[m++] = temp;
tempTokens += temp;
temp = uString.charAt(++index);
}
// 不是数字则返回种别码,结束当前方法
keyID = 11;
tempTokens = tempTokens.substring(4);
list.add(index + "");
list.add(keyID + "");
list.add(tempTokens + "");
return list;
}
m = 0;
// 4.判断当前字符是其他关系运算符
String token = null;
switch (temp) {
case ‘<‘:
// String token = null;
analyseDate[m++] = temp;
token += temp;
if (uString.charAt(++index) == ‘=‘) {
analyseDate[m++] = temp;
keyID = 22;
token += uString.charAt(index++);
} else if (uString.charAt(++index) == ‘>‘) {
analyseDate[m++] = temp;
keyID = 21;
token += uString.charAt(index++);
} else {
keyID = 23;
}
list.add(index + "");
list.add(keyID + "");
token = token.substring(4);
list.add(token);
return list;
case ‘>‘:
// String tokens = null;
analyseDate[m++] = temp;
token += temp;
if (uString.charAt(++index) == ‘=‘) {
keyID = 24;
analyseDate[m++] = temp;
token += uString.charAt(index++);
} else {
keyID = 20;
}
list.add(index + "");
list.add(keyID + "");
token = token.substring(4);
list.add(token);
return list;
case ‘:‘:
analyseDate[m++] = temp;
token += temp;
if (uString.charAt(++index) == ‘=‘) {
keyID = 18;
// analyseDate[m++] = temp;
analyseDate[m++] = uString.charAt(index);
token += uString.charAt(index++);
} else {
keyID = 17;
}
list.add(index + "");
list.add(keyID + "");
token = token.substring(4);
list.add(token);
return list;
case ‘*‘:
keyID = 13;
break;
case ‘/‘:
keyID = 14;
break;
case ‘+‘:
keyID = 15;
break;
case ‘-‘:
keyID = 16;
break;
case ‘=‘:
keyID = 25;
break;
case ‘;‘:
keyID = 26;
break;
case ‘(‘:
keyID = 27;
break;
case ‘)‘:
keyID = 28;
break;
case ‘#‘:
keyID = 0;
break;
default:
keyID = -1;
break;
}
analyseDate[m++] = temp;
list.add(++index + "");
list.add(keyID + "");
list.add(temp + "");
return list;
}
return list;
}
}
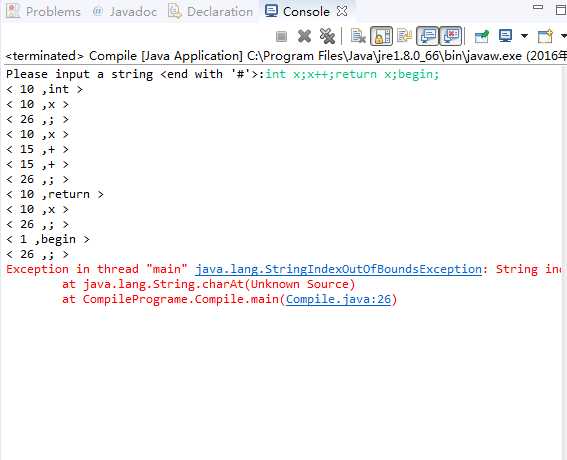
- 1. 运行结果及分析
一般必须配运行结果截图,结果是否符合预期及其分析。
(截图需根据实际,截取有代表性的测试例子)
一、 实验总结
心得体会,实验过程的难点问题及其解决的方法。
以上是关于实验1 词法分析的主要内容,如果未能解决你的问题,请参考以下文章