编译原理--词法分析--实验报告(此文章在管理-发表文章 里也有)
Posted 天空遗落之物
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理--词法分析--实验报告(此文章在管理-发表文章 里也有)相关的知识,希望对你有一定的参考价值。
实验一、词法分析实验
专业:信息技术与工程学院 姓名:吕军 学号:201506110159
一、 实验目的
目的:主要是为了编辑一个词法分析程序。了解计算机的识别源程序字符串的过程。
二、 实验内容和要求
实验内容:通过了解 各种单词符号对应的种别码表,编写一个简单的词法分析程序,通过计算机识别字符串,反映其中的单词符号和所对应的种别码。
实验要求:用户输入源程序字符串,输出:二元组(种别,单词本身)
三、 实验方法、步骤及结果测试
1. 源程序名:简单的词法分析.c
可执行程序名:D:\\Debug\\简单的词法分析.exe

2. 原理分析及流程图
主要总体设计问题:
- 该用什么方式录入用户所输入的字符串。
- 该用什么方法去实现 识别这字符串的内容。怎么区别,识别,字符和关键字。
- 程序的便利问题。
程序原理分析:
我所写的仅仅只是十几个,二十多个字符识别的程序,所以我所用的存储结构是:以getchar从键盘录入,存入字符数组中。
主要算法:运用循环语句,使用switch case语句,一个个去识别是否对应得上字符串里的内容。
关键函数:getchar switch case
流程图:
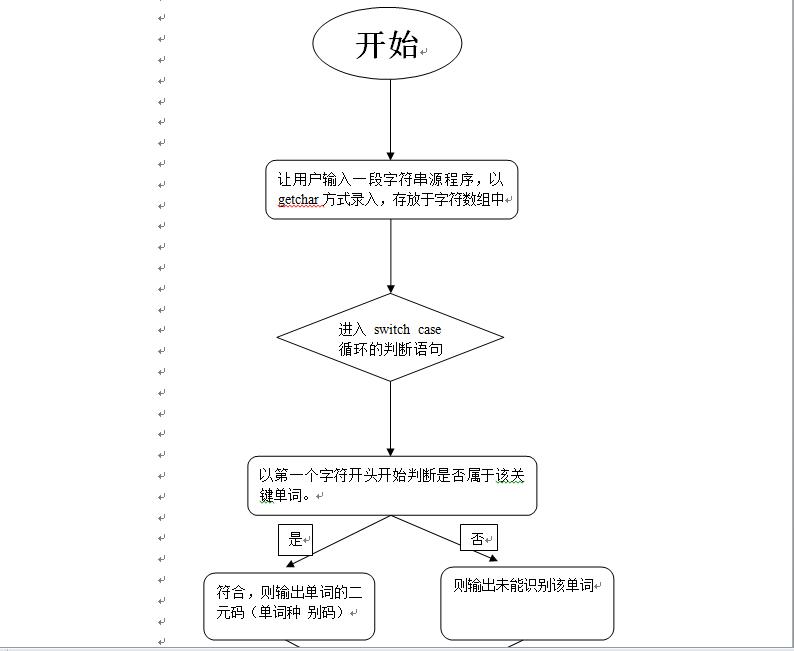
3. 主要程序段及其解释:
1. while(ch!=\'\\n\')
{
ch=getchar(); //字符串的录入与放存
entry[i]=ch;
i++;
}
for(j=0;j<i-1;j++)
{
switch(entry[j])
{
case \'+\': printf("%c 13 \\n",entry[j]);
break;
case \'-\': printf("%c 14 \\n",entry[j]);
break;
case \'*\': printf("%c 15 \\n",entry[j]);
break;
case \'/\': printf("%c 16 \\n",entry[j]);
break;
case \':\':
ch2=entry[j+1];
if(ch2==\'=\')
{
printf("%c%c 18\\n",entry[j],entry[j+1]);
j=j+1;
}
else
printf("%c 17\\n",entry[j]);
break;
case \'<\':
ch2=entry[j+1];
if(ch2==\'=\')
{
printf("%c%c 21 \\n",entry[j],entry[j+1]);
j=j+1;
}
else if(ch2==\'>\')
{
printf("%c%c 22 \\n",entry[j],entry[j+1]);
j=j+1;
}
else
printf("%c 20 \\n",entry[j]);
break;
case \'>\':
ch2=entry[j+1];
if(ch2==\'=\')
{
printf("%c%c 24\\n",entry[j],entry[j+1]);
j=j+1;
}
else
printf("%c 23\\n",entry[j]);
break;
case \'=\': printf("%c 25\\n",entry[j]);
break;
case \';\': printf("%c 26 \\n",entry[j]);
break;
case \'(\': printf("%c 27 \\n",entry[j]);
break;
case \')\': printf("%c 28 \\n",entry[j]);
break;
case \'#\': printf("%c 0\\n",entry[j]);
break;
case \'b\':
if(entry[j+1]==\'e\'&&entry[j+2]==\'g\'&&entry[j+3]==\'i\'&&entry[j+4]==\'n\')
{
printf("begin 1\\n");
j=j+4;
}
else
printf("未能识别 %c 这个单词符号 \\n",entry[j]);
break;
case \'i\': if(entry[j+1]==\'f\')
{
printf("if 2\\n",entry[j]);
j=j+1;
}
else
printf("未能识别 %c 这个单词符号 \\n",entry[j]);
break;
case \'t\':
if(entry[j+1]==\'h\'&&entry[j+2]==\'e\'&&entry[j+3]==\'n\')
{
printf("then 3\\n");
j=j+3;
}
else
printf("未能识别 %c 这个单词符号 \\n",entry[j]);
break;
case \'w\':
if(entry[j+1]==\'h\'&&entry[j+2]==\'i\'&&entry[j+3]==\'l\'&&entry[j+4]==\'e\')
{
printf("while 4\\n");
j=j+4;
}
else
printf("未能识别 %c 这个单词符号 \\n",entry[j]);
break;
case \'d\': if(entry[j+1]==\'o\')
{
printf("do 5\\n ");
j=j+1;
}
else if(entry[j+1]==\'i\'&&entry[j+2]==\'g\'&&entry[j+3]==\'h\'&&entry[j+4]==\'t\')
{
printf("dight 11\\n");
j=j+4;
}
else
printf("未能识别 %c 这个单词符号 \\n",entry[j]);
break;
case \'e\': if(entry[j+1]==\'n\'&&entry[j+2]==\'d\')
{
printf("end 6\\n");
j=j+2;
}
else
printf("未能识别 %c 这个单词符号 \\n",entry[j]);
break;
case \'l\':
if(entry[j+1]==\'e\'&&entry[j+2]==\'t\'&&entry[j+3]==\'t\'&&entry[j+4]==\'e\'&&entry[j+5]==\'r\')
{
printf("letter 10 \\n");
j=j+5;
}
else
printf("未能识别 %c 这个单词符号 \\n",entry[j]);
break;
default :
printf("未能识别 %c 这个字符 \\n", entry[j]);
}
//这一大段是将已知道的字符,对用户输入里的关键单词进行识别
4. 运行结果及分析
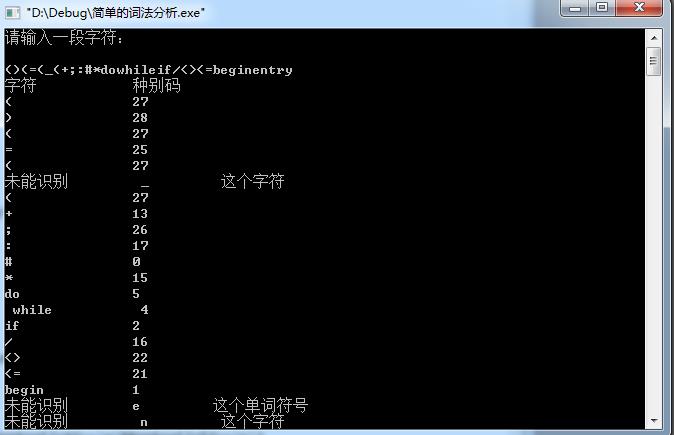
分析:我觉得程序还做得不太好,排版还是有些问题。
四、 实验总结
心得体会:
难点:1.用户输入字符串存储的问题,我考虑过用getchar直接录入,也考虑过用数组,和单链表,最终我选择了字符数组,因为将用户录入的字符串放在数组里更容易操作,当然,其他两种更加简便,不过我还没想出怎么去用,因为在选择用getchar和单链表的时候都会遇到一些问题。
2.用什么方法去识别,去输出的问题。我想到的是用switch case的判断语句去实现的,不过这样很麻烦,而且工程量大,仅仅只适合于比较小规模的字符判别。如果字符判别类型过多,需要些很多的case语句。很麻烦。所以我写的只是简单的词法分析程序。而我看过我同学所写的程序,他写的很详细,他运用到了数组函数,用到了许多if else 和switch case语句,我觉得他那样写简便很多,而且他写的是判断标识符,界符的程序,如果添加其它的,可以简便的添加。我的太麻烦了。
解决方案:1.查阅书籍。
2.向C语言厉害的同学请教。
3.网络搜索,看看别人是怎么写的。有没有值得参考的地方。
以上是关于编译原理--词法分析--实验报告(此文章在管理-发表文章 里也有)的主要内容,如果未能解决你的问题,请参考以下文章