编译原理 实验一 java语言实现对C语言词法分析
Posted _DiMinisH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理 实验一 java语言实现对C语言词法分析相关的知识,希望对你有一定的参考价值。
实验一 C语言词法分析器 (预习报告)
一、实验目的
1. 理解词法分析在编译程序中的作用;
2. 掌握词法分析程序的实现方法和技术
二、实验原理
输入源程序,扫描分解字符串,通过状态转换图,识别出对应的标识符。
三、实验要求
- 单词分类
明确所分析的代码片段包含的单词种别,以及有限单词的具体内容。比如保留字集合、运算符集合等。 - 待分析的源程序的输入形式和识别后单词的输出形式
明确输入以文件输入,输出二元组中单词种别码的表述形式。 - 单词状态转换图
给出各类单词识别的状态转换图。 - 算法设计
path是文件路径,isShow表示用不用,返回值是一个结果
public static Map<String, Pair<String, String>> analyseToAll (String path, boolean isShow)
map是结果,函数用来输出全部结果
public static void printAll (Map<String, Pair<String, String>> map)
实验一 C语言词法分析器 (实验报告)
一、概述
实验可以实现对关键字、特殊符号、运算符、常量的分析,常量可以识别出字符常量、字符串常量,同时可以删除程序中的注释。
实验亮点:对注释删除,识别字符和字符串常量,可以用于分析其他源程序,只需要改动符号链表即可
二、实验方案
1. 词法分析器的结构
词法分析器以循环结构为主,每次读取c语言源代码文件中的数据进行判断,实现对c语言源程序的词法分析
Delimiter 界符
KeyWord 关键字
Operator 运算符
SpecialIdentifier 特殊符号
2. 词法分析器的状态转换图
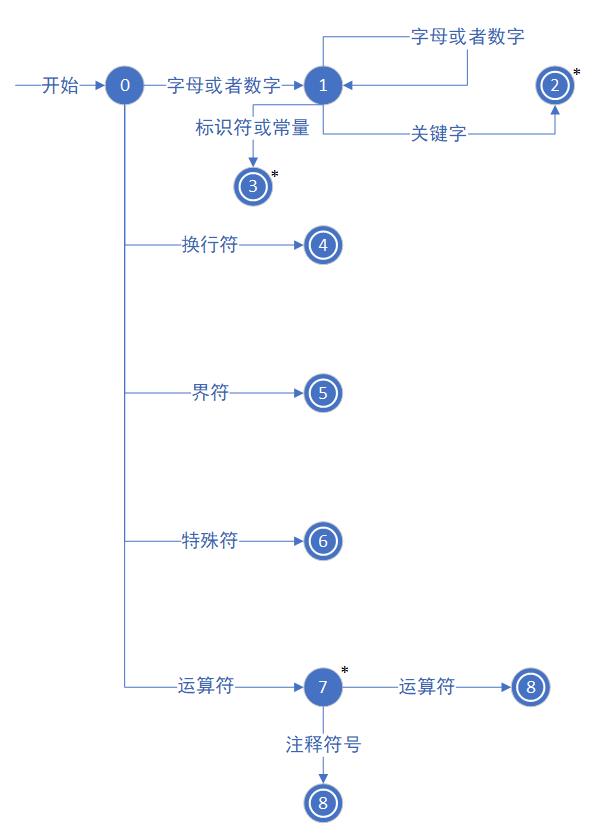
3. 词法分析器的程序流程图
三、实验过程及结果分析
1.测试过程
- 测试数据
#include <stdio.h>
/*
书籍结构体
*/
struct Books
char title[50];
char author[50];
char subject[100];
int book_id;
book = "C 语言", "RUNOOB", "编程语言", 123456;
int main()
printf("title : %s\\nauthor: %s\\nsubject: %s\\nbook_id: %d\\n", book.title, book.author, book.subject, book.book_id);
- 测试结果
特殊符 : #
关键字 : include
界符 : <
标识符 : stdio
运算符 : .
标识符 : h
界符 : >
关键字 : struct
标识符 : Books
界符 :
关键字 : char
标识符 : title
界符 : [
常量 : 50
界符 : ]
特殊符 : ;
关键字 : char
标识符 : author
界符 : [
常量 : 50
界符 : ]
特殊符 : ;
关键字 : char
标识符 : subject
界符 : [
常量 : 100
界符 : ]
特殊符 : ;
关键字 : int
标识符 : book_id
特殊符 : ;
界符 :
标识符 : book
运算符 : =
界符 :
界符 : "
字符串 : C 语言
界符 : "
运算符 : ,
界符 : "
字符串 : RUNOOB
界符 : "
运算符 : ,
界符 : "
字符串 : 编程语言
界符 : "
运算符 : ,
常量 : 123456
界符 :
特殊符 : ;
关键字 : int
标识符 : main
界符 : (
界符 : )
界符 :
标识符 : printf
界符 : (
界符 : "
字符串 : title : %s\\nauthor: %s\\nsubject: %s\\nbook_id: %d\\n
界符 : "
运算符 : ,
标识符 : book
运算符 : .
标识符 : title
运算符 : ,
标识符 : book
运算符 : .
标识符 : author
运算符 : ,
标识符 : book
运算符 : .
标识符 : subject
运算符 : ,
标识符 : book
运算符 : .
标识符 : book_id
界符 : )
特殊符 : ;
界符 :
Process finished with exit code 0
2.调试分析
- 如何区分大于小于号是运算符还是界符(<studio.h>)
分析:当前面出现#号,表示当前行的大于小于号是界符,如果当前行没有#号,则表示大于小于号一定是运算符。
解决:增加boolean类型变量 isTheSameLine,指出当前行有没有#号,如果有,不进行运算符判断操作,如果没有不进行界符判断操作。 - 多行注释识别
分析:多行注释以/开头/结尾,可以使用滞后输出的方式,即当前读取的字符先不着急作出判断,先入栈,等到下一次读取到字符,统一进行操作,当判断出出现了/,则接下来读取的字符都不进行关键字、标识符等判断操作,只有读到/再进行判断操作。
解决:增加三个boolean类型变量:isText表示接下来读取到的都是注释里面的内容,不进行判断;isStar表示接下来的注释是多行注释,而不是//这种单行注释,lastIsStar表示上一个读取到的是*,用来判断是否多行注释结束,在对c语言源程序读入分析时,当读取到/后,接下来只用判断是否读入了,如果读入,则lastIsStar = true,继续读取,如果读取到下一个是/,则结束注释,如果不是/,则lastIsStar 又变为false。
3. 程序运行界面

四、总结与体会
本次试验总体评价优,与预期结果相符合,本实验主要用到的就是Java文件操作,不算复杂,但是主要的逻辑在于如何分析每一个词,试验过程是一个解决问题的过程,从本次试验中我学到了词法分析器的原理、如何用程序实现词法分析器,但还是有些遗憾,没有实现对浮点数的分析,总体来说很不错,加油。
五、代码
1. 词法分析
package main;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
import java.util.Comparator;
import java.util.Map;
import java.util.Stack;
import java.util.TreeMap;
import static main.Constants.*;
/**
* @author Diminish
* @date 2022/4/9 7:46
*/
public class WordAnalysis
/**
* 读取到数字或字母后所暂存的字符串
* */
private static String input = "";
/**
* 记录读取到的关键字个数, 可以改为当前行数
* */
private static int index = 1;
/**
* 记录引号个数
* */
private static int number = 0;
/**
* 记录单引号个数
* */
private static int single = 0;
/**
* 是否当前行有#号
* */
private static boolean isTheSameLine = false;
/**
* 接下来读入的都是注释里的内容
* */
private static boolean isText = false;
/**
* 当前注释是多行注释
* */
private static boolean isStar = false;
/**
* 上一个符号是*
* */
private static boolean lastIsStar = false;
/**
* @param path C文件路径
* @param isShow 是否显示输入的源码
* @return 单词种别二元组
* */
public static Map<String, Pair<String, String>> analyseToAll (String path, boolean isShow)
Map<String, Pair<String, String>> result = new TreeMap<>(Comparator.comparingInt(Integer::parseInt));
try (Reader fileReader = new FileReader(path))
StringBuilder stringBuilder = new StringBuilder();
// 读取到的字符
int c;
while ((c = fileReader.read()) != -1)
stringBuilder.append((char) c);
String ch = (char) c + "";
// 判断注释
if (isText)
// 开启了注释
switch (ch)
case "\\n":
if (!isStar)
isText = false;
break;
case "*":
lastIsStar = true;
break;
case "/":
if (lastIsStar && isStar)
isText = false;
break;
default:
lastIsStar = false;
break;
continue;
// 判断是数字或者字母
else if (ch.matches(NUMBER_LETTER_REGULAR_EXPRESSION))
// 数字或字母加入到待处理的字符串input中
input += ch;
if (!OPERATOR_STACK.empty())
String operator = OPERATOR_STACK.pop();
result.put(index++ + "", new Pair<>(OPERATOR, operator));
continue;
else if (number % 2 != 0 && !"\\"".equals(ch))
input += ch;
continue;
else if (number % 2 != 0)
result.put(index++ + "", new Pair<>(STRING, input));
input = "";
else if (single % 2 != 0 && !"'".equals(ch))
input += ch;
continue;
else if (single % 2 != 0)
result.put(index++ + "", new Pair<>(CHAR, input));
input = "";
// 判断是不是空格
if (" ".equals(ch) || "\\r".equals(ch) || "\\n".equals(ch))
if (!"".equals(input))
isKeyWord(result);
if (!OPERATOR_STACK.empty())
String operator = OPERATOR_STACK.pop();
result.put(index++ + "", new Pair<>(OPERATOR, operator));
if ("\\n".equals(ch))
isTheSameLine = false;
// 不是字母或者数字就进入
else
// 判断是不是特殊符号
if (SpecialIdentifier.isSpecialIdentifier(ch))
// 判断是不是关键字
isKeyWord(result);
if ("#".equals(ch))
isTheSameLine = true;
result.put(index++ + "", new Pair<>(SPECIAL_IDENTIFIER, ch));
// 判断是不是运算符
if (Operator.isOperator(ch))
// 判断是不是关键字
isKeyWord(result);
boolean b = "<".equals(ch) || ">".equals(ch);
if (!isTheSameLine)
// 大于小于号是界符
if (b)
if (!OPERATOR_STACK.empty())
String halfOperator = OPERATOR_STACK.pop();
if (Operator.isOperator(halfOperator + ch))
result.put(index++ + "", new Pair<>(OPERATOR, halfOperator + ch));
else if (",".equals(halfOperator))
result.put(index++ + "", new Pair<>(OPERATOR, halfOperator));
result.put(index++ + "", new Pair<>(OPERATOR, ch));
else
error(halfOperator + ch, stringBuilder, "错误的运算符", result);
return result;
else
OPERATOR_STACK.push(ch);
else
if (!OPERATOR_STACK.empty())
String halfOperator = OPERATOR_STACK.pop();
if (Operator.isOperator(halfOperator + ch))
result.put(index++ + "", new Pair<>(OPERATOR, halfOperator + ch));
else if (",".equals(halfOperator))
result.put(index++ + "", new Pair<>(OPERATOR, halfOperator));
result.put(index++ + "", new Pair<>(OPERATOR, ch));
else if ("//".equals(halfOperator + ch))
isText = true;
else if ("/*".equals(halfOperator + ch))
isText = true;
isStar = true;
else
error(halfOperator + ch, stringBuilder, "错误的运算符", result);
return result;
else
OPERATOR_STACK.push(ch);
else
if (!b)
if (!OPERATOR_STACK.empty())
String halfOperator = OPERATOR_STACK.pop();
if (Operator.isOperator(halfOperator + ch))
result.put(index++ + "", new Pair<>(OPERATOR, halfOperator + ch));
else if (",".equals(halfOperator))
result.put(index++ + "", new Pair<>(OPERATOR, halfOperator));
result.put(index++ + "", new Pair<>(OPERATOR, ch));
else if ("/*".equals(halfOperator + ch) || "//".equals(halfOperator + ch))
// "/*".equals(halfOperator + ch) ||
isText = true;
else
error(halfOperator + ch, stringBuilder, "错误的运算符", result);
return result;
else
OPERATOR_STACK.push(ch);
// 判断是不是界符
if (Delimiter.isDelimiter(ch))
// 判断是不是关键字
isKeyWord(result);
// 栈不空
if (!IDENTIFIER_STACK.empty())
// 判断c的类型, 是不是左括号
if (Delimiter.isLeftDelimiter(ch))
// 左界符入栈
if ("<".equals(ch) || ">".equals(ch))
if (isTheSameLine)
result.put(index++ + "", new Pair<>(DELIMITER, ch));
IDENTIFIER_STACK.push(ch);
else
result.put(index++ + "", new Pair<>(DELIMITER, ch));
IDENTIFIER_STACK.push(ch);
// 判断是不是引号
else if (Delimiter.isNotOrientationDelimiter(ch))
if ("\\"".equals(ch))
boolean inc = false;
if (number == 0)
number++;
inc = true;
// 引号为奇数
if (number % 2 != 0)
result.put(index++ + "", new Pair<>(DELIMITER, ch));
if (!inc) 以上是关于编译原理 实验一 java语言实现对C语言词法分析的主要内容,如果未能解决你的问题,请参考以下文章