CentOS7+hadoop2.6.4+spark-1.6.1
Posted 搬砖小工053
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CentOS7+hadoop2.6.4+spark-1.6.1相关的知识,希望对你有一定的参考价值。
摘要
在上一篇博客《Centos7 下 Hadoop 2.6.4 分布式集群环境搭建》
已经详细写了Hadoop 2.6.4 配置过程,下面详细介绍 spark 1.6.1的安装过程。
Scala 安装
下载 ,解压
下载 scala-2.11.8.tgz, 解压到 /root/workspace/software/scala-2.10.4t 目录下
修改环境变量文件 /etc/profile
添加以下内容
export SCALA_HOME=/root/workspace/software/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/binsource 使之生效
source /etc/profile验证 Scala 安装
slaver1-slaver4 部署 scala
slaver1 - slaver4 参照 master 机器安装步骤进行安装。
Spark 安装
下载,解压
下载 spark-1.6.1-bin-hadoop2.6.tgz,解压到/root/workspace/software/spark1.6.1_hadoop2.6目录下。
修改环境变量文件 /etc/profile, 添加以下内容。
export SPARK_HOME=/root/workspace/software/spark1.6.1_hadoop2.6/
export PATH=$PATH:XXX其他软件的环境变量:$SPARK_HOME/bin# 在最后添加:$SPARK_HOME/binsource 使之生效
source /etc/profileSpark 配置
spark-env.sh
进入 Spark 安装目录下的 /root/workspace/software/spark1.6.1_hadoop2.6/conf 目录, 拷贝 spark-env.sh.template 到 spark-env.sh。
cp spark-env.sh.template spark-env.sh编辑 spark-env.sh,在其中添加以下配置信息:
export SCALA_HOME=/root/workspace/software/scala-2.10.4
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_HOME=/root/workspace/software/hadoop-2.6.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=192.168.122.1
export SPARK_LOCAL_DIRS=/root/workspace/software/spark1.6.1_hadoop2.6
export SPARK_WORKER_MEMORY=20gJAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录。
SPARK_WORKER_MEMORY 我这边的机器内存32g,我设置内存为20g,更加自己的情况修改。
slaves
将 slaves.template 拷贝到 slaves, 编辑其内容为:
master
slaver1
slaver2
slaver3
slaver4即 master 既是 Master 节点又是 Worker 节点
slaver1- slaver4 部署
slaver1 -slaver4 参照 master 机器安装步骤进行安装。
启动 Spark 集群
启动 Hadoop 集群
参考《Centos7 下 Hadoop 2.6.4 分布式集群环境搭建》
启动 Spark 集群
启动 Master 节点
运行 /root/workspace/software/spark1.6.1_hadoop2.6/sbin 下面, start-master.sh
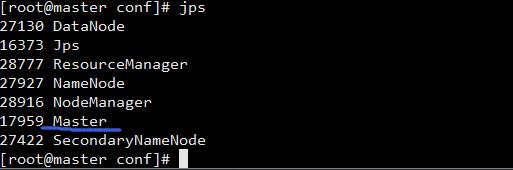
可以看到 master 上多了一个新进程 Master。
启动所有 Worker 节点
运行 运行 /root/workspace/software/spark1.6.1_hadoop2.6/sbin 下面,start-slaves.sh
在slaver1-slaver4查看进程
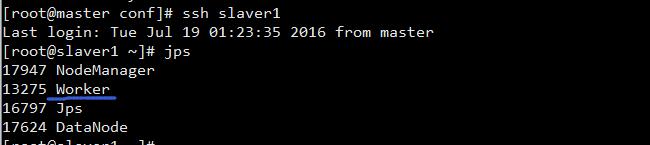
可以发现都启动了一个 Worker 进程
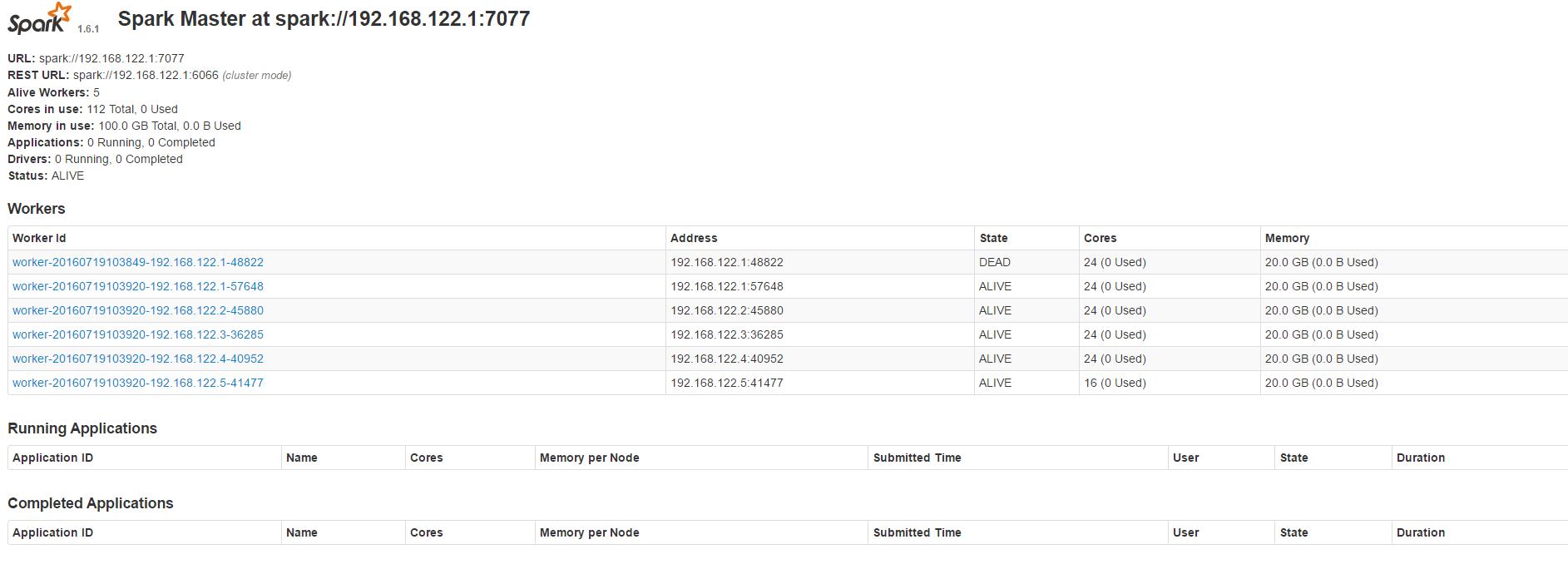
浏览器查看 Spark 集群信息
访问:http://masterIP:8080, 如下图:
使用 spark-shell
运行 spark-shell,可以进入 Spark 的 shell 控制台,如下:

浏览器访问 SparkUI
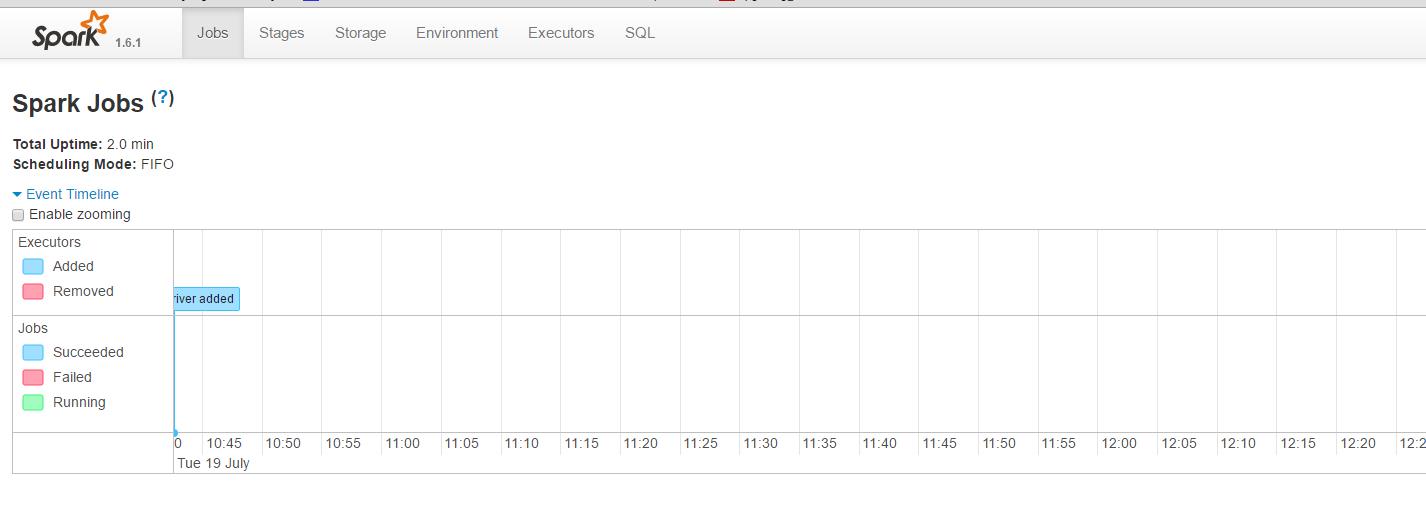
可以从 SparkUI 上查看一些 如环境变量、Job、Executor等信息。
至此,整个 Spark 分布式集群的搭建就到这里结束。
停止 Spark 集群
停止 Master 节点
运行/root/workspace/software/spark1.6.1_hadoop2.6/sbin,下面的stop-master.sh 来停止 Master 节点。

jps查看java进程
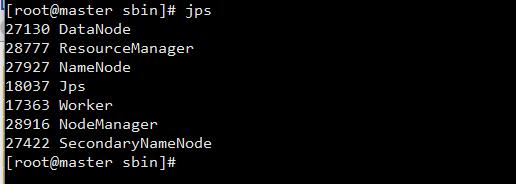
可以发现 Master 进程已经停止。
停止 Master 节点
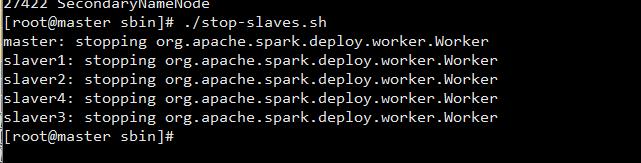
运行/root/workspace/software/spark1.6.1_hadoop2.6/sbin,下面的stop-slaves.sh (注意是stop-slavers 有s) 可以停止所有的 Worker 节点
使用 jps 命令查看 master上的进程信息:
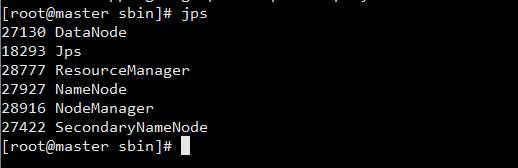
worker 关闭了
使用 jps 命令查看 slaver1上的进程信息:

可以看到, Worker 进程均已停止,最后再停止 Hadoop 集群.
搞定啦
后面边学习边理解里面设置的东西。。
以上是关于CentOS7+hadoop2.6.4+spark-1.6.1的主要内容,如果未能解决你的问题,请参考以下文章
CentOS7搭建hadoop2.6.4+HBase1.1.6
[0008] Windows 7 下 eclipse 的hadoop2.6.4 插件安装使用