[0008] Windows 7 下 eclipse 的hadoop2.6.4 插件安装使用
Posted sunzebo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[0008] Windows 7 下 eclipse 的hadoop2.6.4 插件安装使用相关的知识,希望对你有一定的参考价值。
目的:
基于上篇的方法介绍,开发很不方便 。[0007] windows 下 eclipse 开发 hdfs程序样例
装上插件,方便后续直接在windows下的IDE开发调试。
环境:
- Linux Hadoop 2.6.4,参考文章 [0001]
- Win 7 64 下的 Eclipse Version: Luna Service Release 1 (4.4.1)
工具:
- hadoop-eclipse-plugin-2.6.4.jar 下载地址:http://download.csdn.net/detail/tondayong1981/9437360
- Hadoop 2.6.4 安装程序包, Hadoop2.6.4源码包
- hadoop 2.6 windows插件包 地址后面有
说明:
以下整个步骤过程是在全部弄好后,才来填补的。中间修改多次,为了快速成文有些内容从其他地方复制。因此,如果完全照着步骤,可能需要一些小修改。整个思路是对的。
1. 准备Hadoop安装包
在windows下解压 Hadoop 2.6.4 安装程序包。 将Linux上的hadoop 安装目录下 etc/hadoop的所有配置文件
全部替换 windows下解压后的配置文件
2 . 安装HDFS eclipse 插件
- eclipse关闭状态下, 将 hadoop-eclipse-plugin-2.6.4.jar 放到该目录下 eclipse安装目录\\plugins\\
- 启动eclipse
- 菜单栏->窗口windows->首选项preferences->Hadoop mapeduce ,指定hadoop路径为前面的解压路径
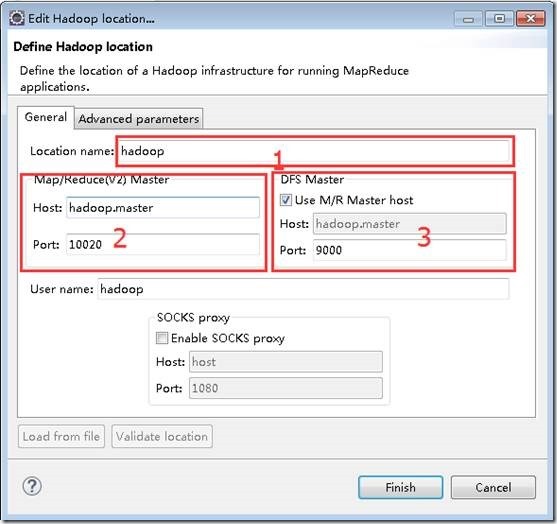
- 菜单栏->窗口windows->Open Perspective->Other->选择Map/Reduce ok->Map/Reduce Location选项卡 ->右边蓝色小象 打开配置窗口如图,进行如下设置,点击ok
1位置为配置的名称,任意。
2位置为mapred-site.xml文件中的mapreduce.jobhistory.address配置,如果没有则默认是10020。
3位置为core-site.xml文件中的fs.defaultFS:hdfs://ssmaster:9000 。
这是网上找到图片,我的设置
hadoop2.6伪分布式,ssmaster:10020,ssmaster:9000
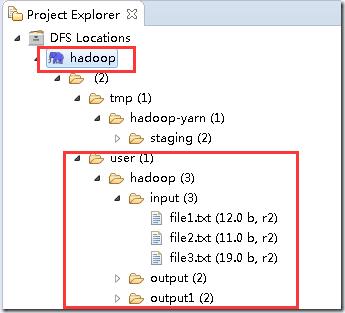
设置成功后,在eclipse这里可以直接显示Linux Hadoop hdfs的文件目录
可以直接在这里 下载、上传、 删除HDFS上的文件,很方便
3 配置Mapreduce Windows 插件包
3.1 下载hadoop 2.6 windows插件包包
没找到2.6.4的,用2.6的最后也成功了。
其中参考下载地址: http://download.csdn.net/detail/myamor/8393459,这个似乎是win8的, 本人的系统win7,不是从这里下的。 忘记哪里了。可以搜索 winutils.exe + win7 。 下载后的文件应该有 hadoop.dll hadoop.pdb hadoop.lib hadoop.exp winutils.exe winutils.pdb libwinutils.lib
3.2 配置
a 解压上面的插件包, 将文件全部拷贝到 G:\\RSoftware\\hadoop-2.6.4\\hadoop-2.6.4\\bin ,该路径为前面"2 . 安装HDFS eclipse 插件"的hadoop指定路径。
b 设置环境变量
HADOOP_HOME =G:\\RSoftware\\hadoop-2.6.4\\hadoop-2.6.4
Path 中添加 G:\\RSoftware\\hadoop-2.6.4\\hadoop-2.6.4\\bin
确保有 HADOOP_USER_NAME = hadoop 上一篇 [0007]中设置
重启Eclipse ,读取新环境变量
4 测试Mapreduce
4.1 新建mapreduce 工程
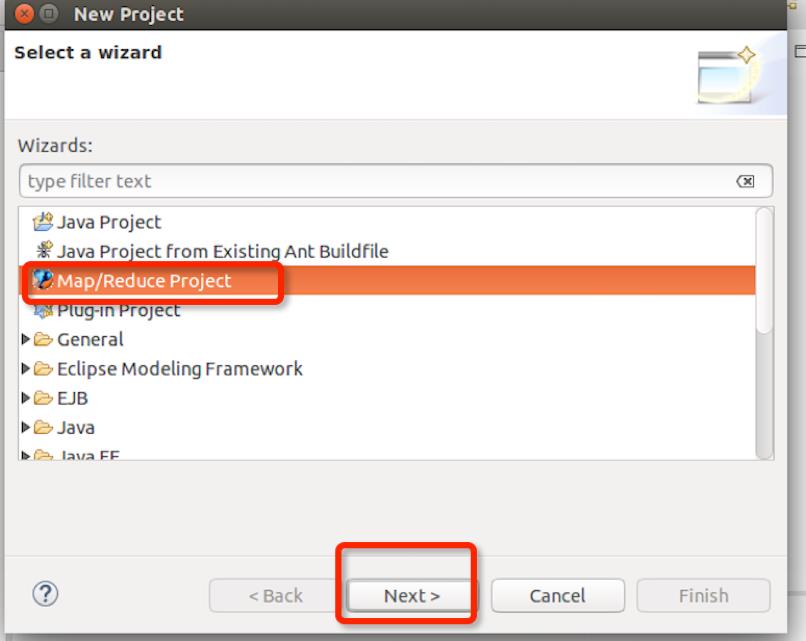
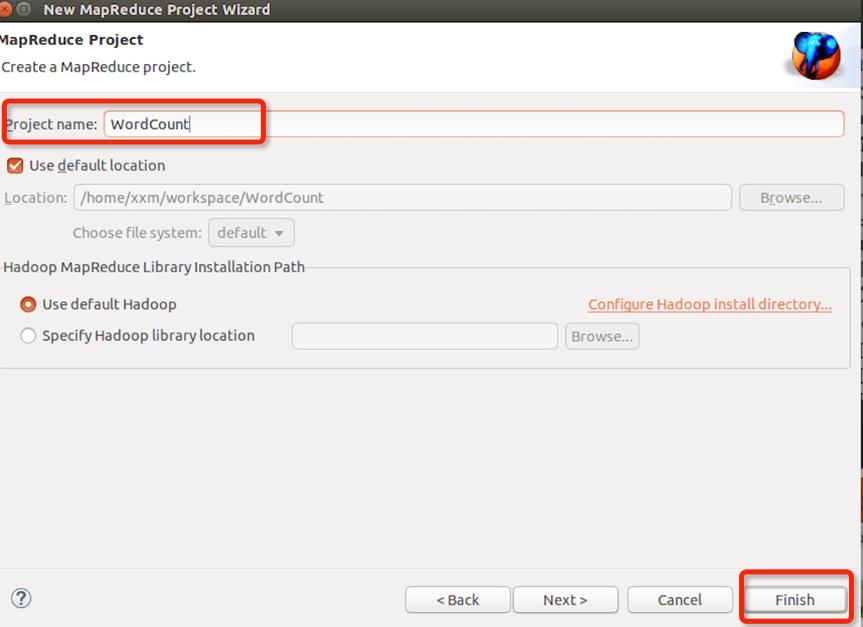
完成后项目会自动把Hadoop的所有jar包导入
4.2 项目配置log4j
在src目录下,创建log4j.properties文件 ,内容如下
log4j.rootLogger=debug,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%
log4j.logger.com.codefutures=DEBUG
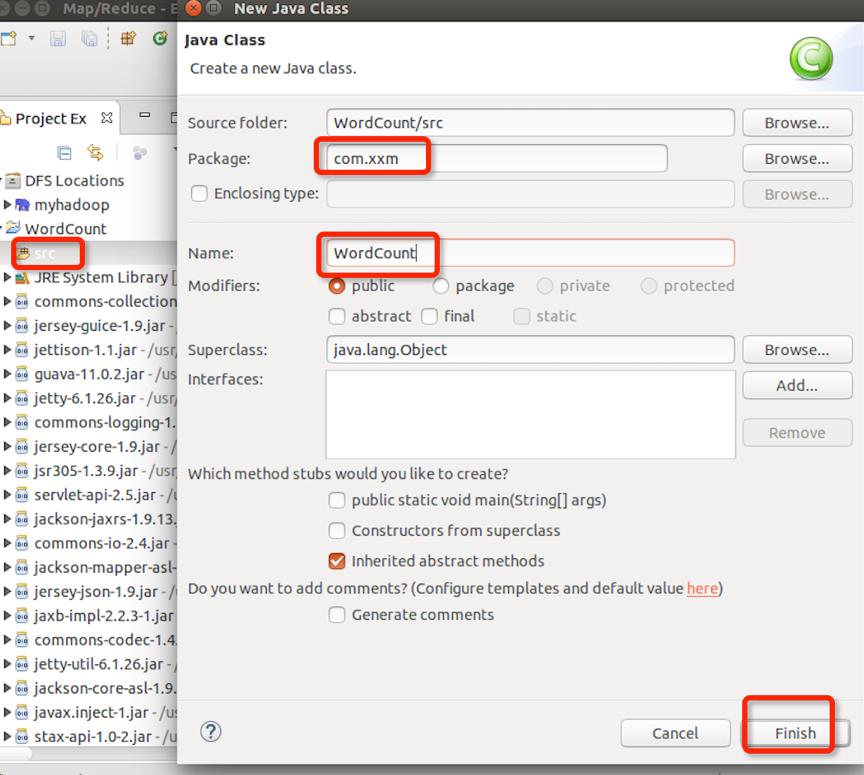
4.3 WordCount类中 添加代码
在WordCount项目里右键src新建class,包名com.xxm(请自行命明),类名为WordCount


package mp.filetest; import java.io.IOException; import java.util.*; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; /** * 描述:WordCount explains by xxm * @author xxm */ public class WordCount2 { /** * Map类:自己定义map方法 */ public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { /** * LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类 * 都能够被串行化从而便于在分布式环境中进行数据交换,可以将它们分别视为long,int,String 的替代品。 */ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); /** * Mapper类中的map方法: * protected void map(KEYIN key, VALUEIN value, Context context) * 映射一个单个的输入k/v对到一个中间的k/v对 * Context类:收集Mapper输出的<k,v>对。 */ public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } /** * Reduce类:自己定义reduce方法 */ public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { /** * Reducer类中的reduce方法: * protected void reduce(KEYIN key, Interable<VALUEIN> value, Context context) * 映射一个单个的输入k/v对到一个中间的k/v对 * Context类:收集Reducer输出的<k,v>对。 */ public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } /** * main主函数 */ public static void main(String[] args) throws Exception { Configuration conf = new Configuration();//创建一个配置对象,用来实现所有配置 Job job = new Job(conf, "wordcount2");//新建一个job,并定义名称 job.setOutputKeyClass(Text.class);//为job的输出数据设置Key类 job.setOutputValueClass(IntWritable.class);//为job输出设置value类 job.setMapperClass(Map.class); //为job设置Mapper类 job.setReducerClass(Reduce.class);//为job设置Reduce类 job.setJarByClass(WordCount2.class); job.setInputFormatClass(TextInputFormat.class);//为map-reduce任务设置InputFormat实现类 job.setOutputFormatClass(TextOutputFormat.class);//为map-reduce任务设置OutputFormat实现类 FileInputFormat.addInputPath(job, new Path(args[0]));//为map-reduce job设置输入路径 FileOutputFormat.setOutputPath(job, new Path(args[1]));//为map-reduce job设置输出路径 job.waitForCompletion(true); //运行一个job,并等待其结束 } }
可选, 如果没有配置,最后可能报这个错误,在文章最后面异常部分, 按照异常解决办法配置。
( Y.2 运行过程中 异常
1 main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)
)
4.4 运行
确保Hadoop已经启动
在WordCount的代码区域,右键,点击Run As—>Run Configurations,配置运行参数,文件夹输入和输出,第2个参数的路径确保HDFS上不存在
hdfs://ssmaster:9000/input
hdfs://ssmaster:9000/output

点击 Run运行,可以直接在eclipse的控制台看到执行进度和结果
INFO - Job job_local1914346901_0001 completed successfully INFO - Counters: 38 File System Counters FILE: Number of bytes read=4109 FILE: Number of bytes written=1029438 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=134 HDFS: Number of bytes written=40 HDFS: Number of read operations=37 HDFS: Number of large read operations=0 HDFS: Number of write operations=6 Map-Reduce Framework Map input records=3 Map output records=7 Map output bytes=70 Map output materialized bytes=102 Input split bytes=354 Combine input records=7 Combine output records=7 Reduce input groups=5 Reduce shuffle bytes=102 Reduce input records=7 Reduce output records=5 Spilled Records=14 Shuffled Maps =3 Failed Shuffles=0 Merged Map outputs=3 GC time elapsed (ms)=21 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=1556611072 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=42 File Output Format Counters Bytes Written=40
在“DFS Locations”下,刷新刚创建的“hadoop”看到本次任务的输出目录下是否有输出文件。

4.5 可选 命令行下执行,导出成jar包,上传到Linux
右键项目名字->导出->java/jar文件 ->指定jar路径名字->指定main类为 完成
先删除刚才的输出目录
hadoop@ssmaster:~/java_program$ hadoop fs -rm -r /output
hadoop@ssmaster:~/java_program$ hadoop fs -ls /
Found 4 items
drwxr-xr-x - hadoop supergroup 0 2016-10-24 05:04 /data
drwxr-xr-x - hadoop supergroup 0 2016-10-23 00:45 /input
drwxr-xr-x - hadoop supergroup 0 2016-10-24 05:04 /test
drwx------ - hadoop supergroup 0 2016-10-23 00:05 /tmp
执行 hadoop jar hadoop_mapr_wordcount.jar /input /output
hadoop@ssmaster:~/java_program$ hadoop jar hadoop_mapr_wordcount.jar /input /output 16/10/24 08:30:32 INFO client.RMProxy: Connecting to ResourceManager at ssmaster/192.168.249.144:8032 16/10/24 08:30:33 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 16/10/24 08:30:33 INFO input.FileInputFormat: Total input paths to process : 1 16/10/24 08:30:34 INFO mapreduce.JobSubmitter: number of splits:1 16/10/24 08:30:34 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1477315002921_0004 16/10/24 08:30:34 INFO impl.YarnClientImpl: Submitted application application_1477315002921_0004 16/10/24 08:30:34 INFO mapreduce.Job: The url to track the job: http://ssmaster:8088/proxy/application_1477315002921_0004/ 16/10/24 08:30:34 INFO mapreduce.Job: Running job: job_1477315002921_0004 16/10/24 08:30:43 INFO mapreduce.Job: Job job_1477315002921_0004 running in uber mode : false 16/10/24 08:30:43 INFO mapreduce.Job: map 0% reduce 0% 16/10/24 08:30:52 INFO mapreduce.Job: map 100% reduce 0% 16/10/24 08:31:02 INFO mapreduce.Job: map 100% reduce 100% 16/10/24 08:31:04 INFO mapreduce.Job: Job job_1477315002921_0004 completed successfully 16/10/24 08:31:05 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=3581 FILE: Number of bytes written=220839 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=1863 HDFS: Number of bytes written=1425 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=6483 Total time spent by all reduces in occupied slots (ms)=7797 Total time spent by all map tasks (ms)=6483 Total time spent by all reduce tasks (ms)=7797 Total vcore-milliseconds taken by all map tasks=6483 Total vcore-milliseconds taken by all reduce tasks=7797 Total megabyte-milliseconds taken by all map tasks=6638592 Total megabyte-milliseconds taken by all reduce tasks=7984128 Map-Reduce Framework Map input records=11 Map output records=303 Map output bytes=2969 Map output materialized bytes=3581 Input split bytes=101 Combine input records=0 Combine output records=0 Reduce input groups=158 Reduce shuffle bytes=3581 Reduce input records=303 Reduce output records=158 Spilled Records=606 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=241 CPU time spent (ms)=4530 Physical memory (bytes) snapshot=456400896 Virtual memory (bytes) snapshot=1441251328 Total committed heap usage (bytes)=312999936 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1762 File Output Format Counters Bytes Written=1425
备注:如何导出包,可以用这种方式执行 hadoop jar xxxx.jar wordcount /input /output [遗留]
Y 异常
Y.1 Permission denied: user=Administrator
在第2步最后, HDFS的某个目录可能提示:
Permission denied: user=Administrator, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
用户Administator在hadoop上执行写操作时被权限系统拒,windows eclipse的默认用 用户Administator 去访问hadoop的文件
解决如下:
windows 添加环境变量 HADOOP_USER_NAME ,值为 hadoop (这是Linux上hadoop2.6.4 的用户名)
重启eclipse生效
Y.2 运行过程中 异常
1 main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
原因:未知
解决:
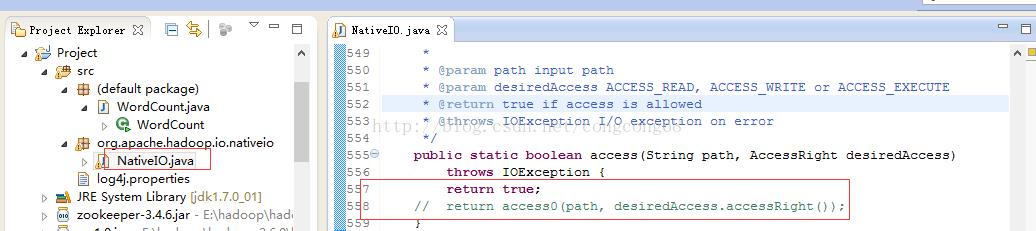
a 将前面下载的配置包中的 hadoop.dll 文件拷贝到 C:\\Windows\\System32 ,参考中提示需要 重启电脑
b 源码包 hadoop-2.6.4-src.tar.gz解压,hadoop-2.6.4-src\\hadoop-common-project\\hadoop-common\\src\\main\\java\\org\\apache\\hadoop\\io\\nativeio下NativeIO.java 复制到对应的Eclipse的project
修改如下地方
2 log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://ssmaster:9000/output already exists at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146) at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:267) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:140) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1297) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1294) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1294) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1315) at mp.filetest.WordCount2.main(WordCount2.java:88)
原因: log4j.properties文件没有
解决: 照步骤做 4.2
3 Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\\bin\\winutils.exe in the
2016-10-24 20:42:03,603 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2016-10-24 20:42:03,709 ERROR [main] util.Shell (Shell.java:getWinUtilsPath(373)) - Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\\bin\\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:355) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:370) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:363) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79) at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:116) at org.apache.hadoop.security.Groups.<init>(Groups.java:93) at org.apache.hadoop.security.Groups.<init>(Groups.java:73) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:293)
原因:hadoop 2.6 windows插件包没配置好
解决:安装步骤3.2中配置
Z 总结:
加油,干得好。
后续:
照着参考里面的程序,跑一下,测试直接跑程序能否成功 done
有空弄明白 log4j.properties配置中各个参数含义
将Hadoop源码包导入项目中,以便跟踪调试
C 参考:
c.1 安装: Win7+Eclipse+Hadoop2.6.4开发环境搭建
c.2 安装: Hadoop学习笔记(4)-Linux ubuntu 下 Eclipse下搭建Hadoop2.6.4开发环境
c.3 错误处理:关于使用Hadoop MR的Eclipse插件开发时遇到Permission denied问题的解决办法
c.4 错误处理: 解决Exception: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z 等一系列问题
以上是关于[0008] Windows 7 下 eclipse 的hadoop2.6.4 插件安装使用的主要内容,如果未能解决你的问题,请参考以下文章