性能测试中关键指标的监控与分析
Posted gracetest
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能测试中关键指标的监控与分析相关的知识,希望对你有一定的参考价值。
一、软件性能测试需要监控哪些关键指标?
软件性能测试的目的主要有以下三点:
Ø 评价系统当前性能,判断系统是否满足预期的性能需求。
Ø 寻找软件系统可能存在的性能问题,定位性能瓶颈并解决问题。
Ø 判定软件系统的性能表现,预见系统负载压力承受力,在应用部署之前,评估系统性能。
而对于用户来说,则最关注的是当前系统:
Ø 是否满足上线性能要求?
Ø 系统极限承载如何?
Ø 系统稳定性如何?
因此,针对以上性能测试的目的以及用户的关注点,要达到以上目的并回答用户的关注点,就必须首先执行性能测试并明确需要收集、监控哪些关键指标,通常情况下,性能测试监控指标主要分为:资源指标和系统指标,如下图所示,资源指标与硬件资源消耗直接相关,而系统指标则与用户场景及需求直接相关。
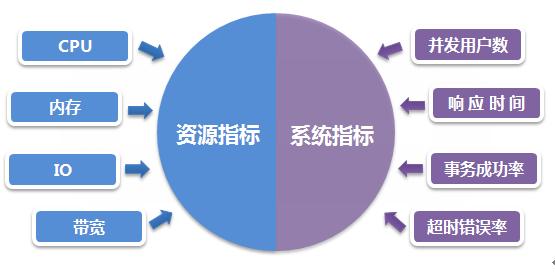
性能测试监控关键指标说明:
Ø 资源指标
CPU使用率:指用户进程与系统进程消耗的CPU时间百分比,长时间情况下,一般可接受上限不超过85%。
内存利用率:内存利用率=(1-空闲内存/总内存大小)*100%,一般至少有10%可用内存,内存使用率可接受上限为85%。
磁盘I/O: 磁盘主要用于存取数据,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据的时候对应的是写IO操作,取数据的时候对应的是是读IO操作,一般使用% Disk Time(磁盘用于读写操作所占用的时间百分比)度量磁盘读写性能。
网络带宽:一般使用计数器Bytes Total/sec来度量,Bytes Total/sec表示为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较。
Ø 系统指标:
并发用户数:某一物理时刻同时向系统提交请求的用户数。
在线用户数:某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求。
平均响应时间:系统处理事务的响应时间的平均值。事务的响应时间是从客户端提交访问请求到客户端接收到服务器响应所消耗的时间。对于系统快速响应类页面,一般响应时间为3秒左右。
事务成功率:性能测试中,定义事务用于度量一个或者多个业务流程的性能指标,如用户登录、保存订单、提交订单操作均可定义为事务,如下图所示:
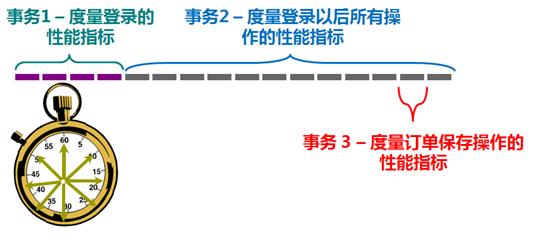
单位时间内系统可以成功完成多少个定义的事务,在一定程度上反应了系统的处理能力,一般以事务成功率来度量,计算公式如下所示:
超时错误率:主要指事务由于超时或系统内部其它错误导致失败占总事务的比率。
二、如何监控关键指标?
Ø 资源指标监控
主要针对各服务器系统平台(Windows、Linux、Unix等)资源使用进行监控。
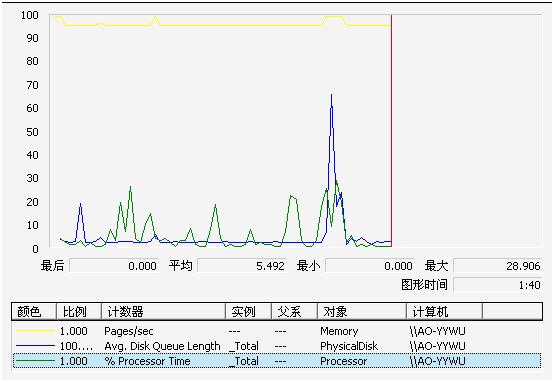
可以使用系统自带的性能监控工具或者第三方工具进行监控,如Windows系统自带的“系统性能监视器”,如下图所示:
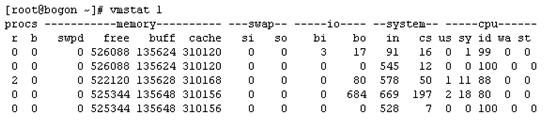
Linux系统下,free、vmstat、sar、iostat等命令监控内存、CPU、磁盘IO等的使用情况,如下图所示:
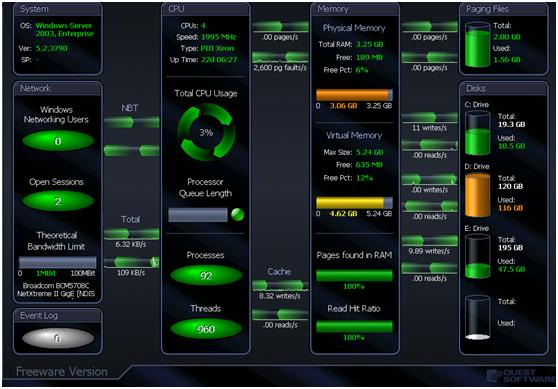
第三方监控工具,如spotlight,spotlight是quest公司开发的一款可以针对多种系统平台及数据库进行监控的可视化工具,如下图所示:
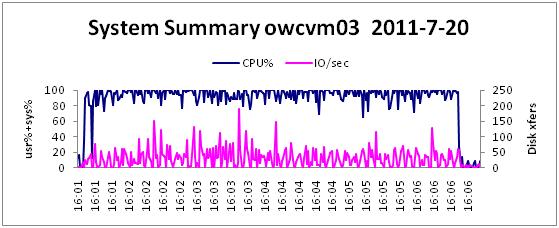
Nmon是IBM提供的监控AIX和Linux系统资源的免费工具,可以对收集的资源信息通过Excel进行统计分析形成直观的统计图,如下图所示:
Ø 系统指标监控
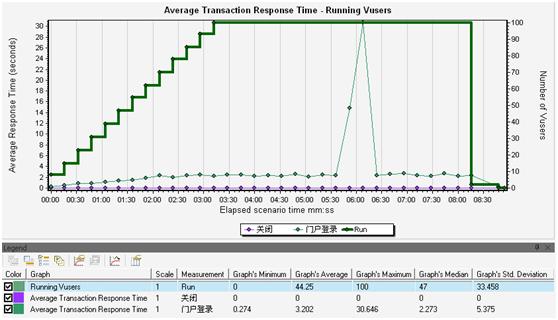
系统指标监控一般通过性能测试工具(如LoadRunner、Jmeter等)以图形化方式监控,如下图所示,并发用户数与平均响应时间关系图。
三、如何分析监控的关键指标?
通过第二部分监控收集到性能度量关键指标,如何进行分析,并判断是否存在性能瓶颈呢?以下主要从资源指标与系统指标两方面进行阐述。
Ø 资源指标分析
判断CPU是否是瓶颈的方法:一般情况下CPU满负荷工作,有时候并不能判定为CPU出现瓶颈,比如Linux总是试图要CPU尽可能的繁忙,使得任务的吞吐量最大化,即CPU尽可能最大化使用。因此,一般判断CPU为瓶颈,主要从两方面:一是CPU空闲持续为0,二是运行队列大于CPU核数(经验值3-4倍),即可判定存在瓶颈,对于CPU高消耗主要由什么引起的,可能是应用程序不合理造成,也可能是硬件资源不足,需要具体问题具体分析,比如问题SQL语句引起,则需要跟踪并优化引起CPU使用过高的SQL语句。
判断内存是否是瓶颈的方法:一般至少有10%可用内存,内存使用率可接受上限为85%。当空闲内存变小时,系统开始频繁地调动磁盘页面文件,空闲内存过小可能是内存不足或内存泄漏引起,需要根据系统实际情况监控分析。
vmstat 命令添加时间参数,可以按自定义时间间隔和次数动态获取系统内存等信息,未加任何参数只获取一次数据信息。
swap:虚拟内存使用情况
free:空闲的内存
cache:文件缓存
si:内存与磁盘的交互
so:内存与磁盘的交互
bi:读磁盘
bo:写磁盘
si和so表示内存交换的频繁程度,如果数值长期很大,表示内存不够。
判断磁盘I/O是否是瓶颈的方法:磁盘I/O对于数据库服务器、文件服务器、流媒体服务器系统来说,更容易成为瓶颈,一般从以下几个方面对磁盘I/O进行分析判断:
① 计算每磁盘I/O数
每磁盘I/O数可用来与磁盘的I/O能力进行对比,如果经过计算得到的每磁盘I/O数超过了磁盘标称的I/O能力,则说明确实存在磁盘的性能瓶颈,每磁盘I/O计算方法如下表:
|
RAID类型 |
计算方法 |
|
RAID0 |
(Reads+Writes)/Numbers of Disks |
|
RAID1 |
(Reads+2*Writes)/2 |
|
RAID5 |
[Reads+(4*Writes)] /Numbers of Disks |
|
RAID10 |
[Reads+(2*Writes)] /Numbers of Disks |
② 监控磁盘读写,如果磁盘长时间进行大数据量读写操作,且cpu等待超过20%,则说明磁盘I/O存在问题,考虑提高磁盘I/O读写性能。
判断网络带宽是否是瓶颈的方法:判断网络带宽是否是系统运行性能瓶颈的首要条件是网络带宽是否会影响系统交易执行性能。例如:减小网络带宽,并发用户数、响应时间与事务通过率等性能指标是否不能接受;或者增加网络带宽,并发用户数、响应时间与事务通过率等性能指标会得到明显提高。
在实际性能测试中,如果发现始终报连接超时,而实际手工访问可以正常访问,可以通过ping应用服务器IP或网关IP,如果出现网络严重延迟或丢包,则说明网络不稳定,需要检查网络。
通过对资源指标四个指标的分析,实际上各个方面都是互相依赖的,不能孤立的单从某个方面进行排查。当一个方面出现性能问题时,往往会引发其他方面的性能问题,例如,大量的磁盘读写势必消耗CPU和IO资源,而内存的不足会导致频繁地进行内存页写入磁盘、磁盘写到内存的操作,造成磁盘IO瓶颈,同时,大量的网络流量也会造成CPU过载,所以,在分析性能问题时,需要从各个方面进行考虑。
Ø 系统指标分析
并发用户数:系统能够支持的用户数是系统容量的重要标志,并发用户数用于度量系统在高并发量访问下,系统的并行处理能力,一般如果系统中存在死锁、资源争用,在并发访问下,由于请求处于队列等待中,系统响应就会随着时间变慢。
一般情况下,选用高吞吐量、高数据库I/O、高商业风险的业务功能进行并发用户访问测试。
判断系统能够承受的最大并发用户数,通常以满足以下条件为准:
1、业务功能操作平均响应时间在合理范围之内
2、事务成功率在合理范围之内
3、 系统运行无故障(无异常宕机)
4、系统资源指标使用在合理范围内
平均响应时间:对于客户端用户来说,最直观的体验就是访问该页面快或者慢,即响应时间的长短。比如在持续并发性能测试过程中,客户感知访问应用很慢,监控到的平均响应时间也逐渐变长,这时就需要先借助于监控到的资源指标,首先排除资源方面的限制因素,再从应用本身进行定位,如可以采用页面细分工具(如httpwatch、Loadrunner Anaysis中的页面组件细分)分析响应比较慢的页面。
事务成功率、超时出错率:事务成功率越高,则表明系统处理能力越大;而失败事务主要由于系统响应慢,导致访问业务功能超时,或者系统业务功能异常,不能正常访问等,需要根据事务错误提示信息,具体分析。
综上所述,软件性能测试是执行、监控—〉分析—〉调优不断进行的过程,即监控是为分析提供更多的参考数据,分析是为了进行调优,调优是解决当前系统存在的性能瓶颈,为用户提供更好、更快的客户体验。由于分析、调优需要根据具体问题进行具体分析,本文未做过多说明,只对通用的关键指标进行监控分析,建议在实际工作中可从资源指标与系统指标两个方面,层层检测、步步排查,性能问题就无处藏身,一旦找到出现问题的原因,性能问题也就迎刃而解!
以上是关于性能测试中关键指标的监控与分析的主要内容,如果未能解决你的问题,请参考以下文章