算法分析-堆排序 Heap Sort
Posted 暗影侠客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法分析-堆排序 Heap Sort相关的知识,希望对你有一定的参考价值。
堆排序的是集合了插入排序的单数组操作,又有归并排序的时间复杂度,完美的结合了2者的优点。
堆的定义
n个元素的序列{k1,k2,…,kn}当且仅当满足下列关系之一时,称之为堆。
情形1:ki <= k2i 且ki <= k2i+1 (最小化堆或小顶堆)
情形2:ki >= k2i 且ki >= k2i+1 (最大化堆或大顶堆)
其中i=1,2,…,n/2向下取整;

若将和此序列对应的一维数组(即以一维数组作此序列的存储结构)看成是一个完全二叉树,则堆的含义表明,完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值。
由此,若序列{k1,k2,…,kn}是堆,则堆顶元素(或完全二叉树的根)必为序列中n个元素的最小值(或最大值)。
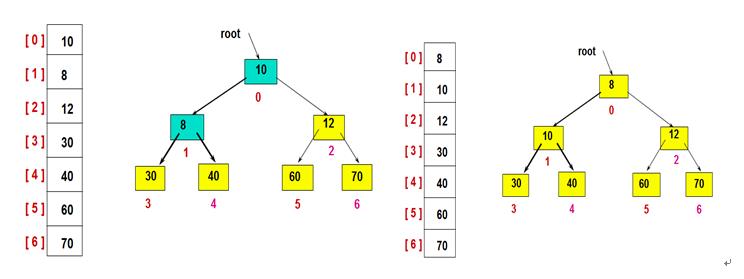
例如,下列两个序列为堆,对应的完全二叉树如图:
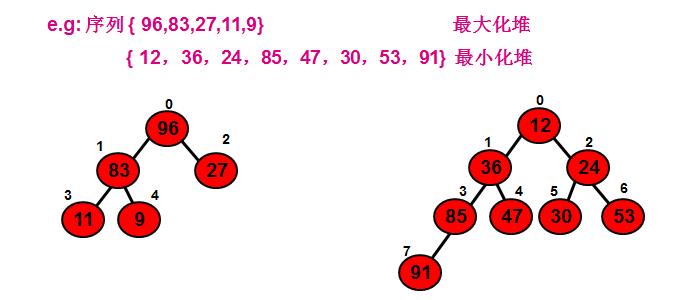
若在输出堆顶的最小值之后,使得剩余n-1个元素的序列重又建成一个堆,则得到n个元素的次小值。如此反复执行,便能得到一个有序序列,这个过程称之为堆排序。
堆排序(Heap Sort)只需要一个记录元素大小的辅助空间(供交换用),每个待排序的记录仅占有一个存储空间。
堆的存储
一般用数组来表示堆,若根结点存在序号0处, i结点的父结点下标就为(i-1)/2。i结点的左右子结点下标分别为2*i+1和2*i+2。
(注:如果根结点是从1开始,则左右孩子结点分别是2i和2i+1。)
如第0个结点左右子结点下标分别为1和2。
如最大化堆如下:
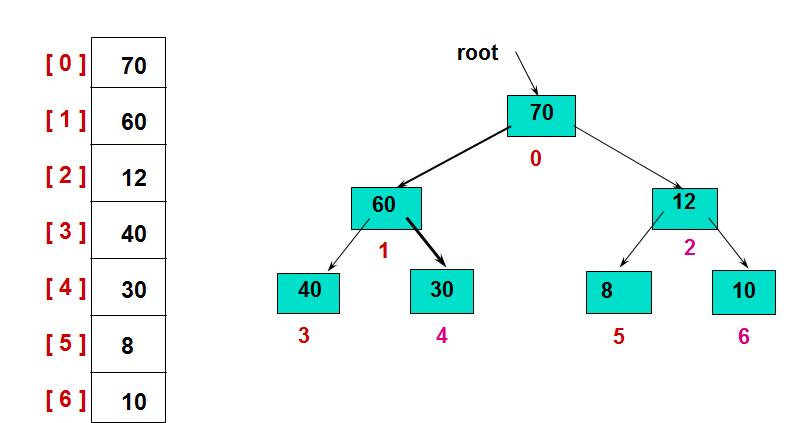
左图为其存储结构,右图为其逻辑结构。
堆排序的实现
实现堆排序需要解决两个问题:
1.如何由一个无序序列建成一个堆?
2.如何在输出堆顶元素之后,调整剩余元素成为一个新的堆?
先考虑第二个问题,一般在输出堆顶元素之后,视为将这个元素排除,然后用表中最后一个元素填补它的位置,自上向下进行调整:首先将堆顶元素和它的左右子树的根结点进行比较,把最小的元素交换到堆顶;然后顺着被破坏的路径一路调整下去,直至叶子结点,就得到新的堆。
我们称这个自堆顶至叶子的调整过程为“筛选”。
从无序序列建立堆的过程就是一个反复“筛选”的过程。
构造初始堆
初始化堆的时候是对所有的非叶子结点进行筛选。
最后一个非终端元素的下标是[n/2]向下取整,所以筛选只需要从第[n/2]向下取整个元素开始,从后往前进行调整。
比如,给定一个数组,首先根据该数组元素构造一个完全二叉树。
然后从最后一个非叶子结点开始,每次都是从父结点、左孩子、右孩子中进行比较交换,交换可能会引起孩子结点不满足堆的性质,所以每次交换之后需要重新对被交换的孩子结点进行调整。
进行堆排序
有了初始堆之后就可以进行排序了。
堆排序是一种选择排序。建立的初始堆为初始的无序区。
排序开始,首先输出堆顶元素(因为它是最值),将堆顶元素和最后一个元素交换,这样,第n个位置(即最后一个位置)作为有序区,前n-1个位置仍是无序区,对无序区进行调整,得到堆之后,再交换堆顶和最后一个元素,这样有序区长度变为2。。。
不断进行此操作,将剩下的元素重新调整为堆,然后输出堆顶元素到有序区。每次交换都导致无序区-1,有序区+1。不断重复此过程直到有序区长度增长为n-1,排序完成。
堆排序实例
首先,建立初始的堆结构如图:
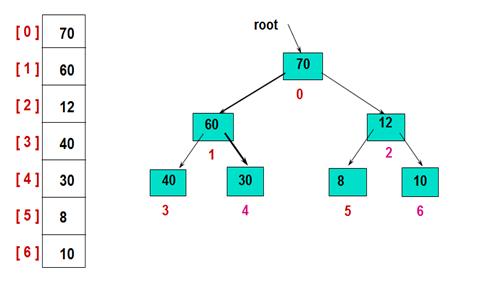
然后,交换堆顶的元素和最后一个元素,此时最后一个位置作为有序区(有序区显示为黄色),然后进行其他无序区的堆调整,重新得到大顶堆后,交换堆顶和倒数第二个元素的位置……
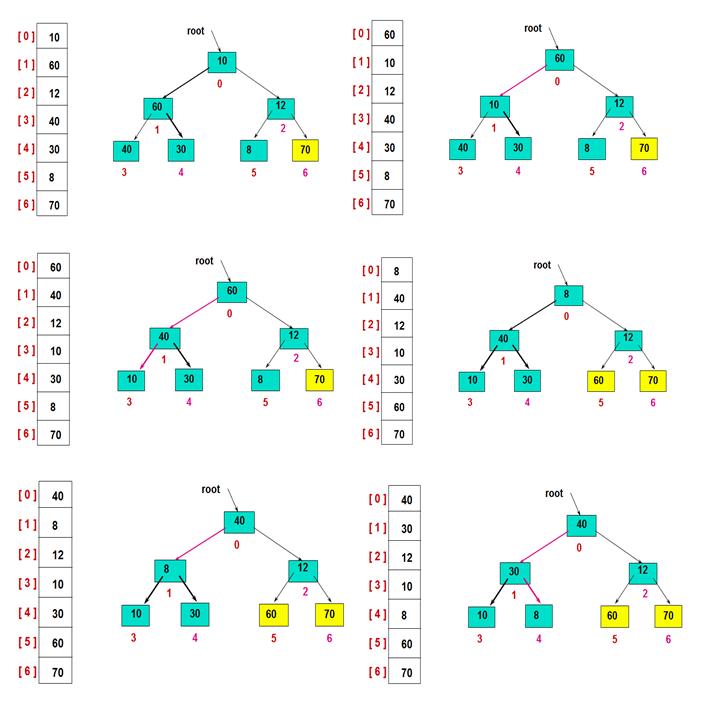
重复此过程:

最后,有序区扩展完成即排序完成:
由排序过程可见,若想得到升序,则建立大顶堆,若想得到降序,则建立小顶堆。
代码
假设排列的元素为整型,且元素的关键字为其本身。
因为要进行升序排列,所以用大顶堆。
根结点从0开始,所以i结点的左右孩子结点的下标为2i+1和2i+2。
1 //将父节点的值和最大值交换 2 Array.prototype.swap = function (i, j) { 3 var temp = this[i]; 4 this[i] = this[j]; 5 this[j] = temp; 6 }; 7 8 //生成以i为根节点的最大堆 9 Array.prototype.MAX_HEAPTIFY = function (i) { 10 var largest = i; 11 var left = i * 2 + 1; //左孩子节点坐标 12 var right = i * 2 + 2; //右孩子节点坐标 13 14 if (left < heap_size && this[left] > this[largest]) { //这其实是一个剪枝的过程,因为heap_size后面都是排序好的。 15 largest = left; 16 } 17 if (right < heap_size && this[right] > this[largest]) { 18 largest = right; 19 } 20 if (largest !== i) { 21 this.swap(i, largest); 22 arguments.callee.call(this, largest); 23 } 24 }; 25 26 //生产堆 27 Array.prototype.BUILD_HEAP = function () { 28 var lastP = Math.floor(this.length / 2) - 1; //最后一个非叶子节点。 29 for (var k = lastP; k >= 0; k--) { 30 this.MAX_HEAPTIFY(k); 31 } 32 }; 33 34 //主程序 35 Array.prototype.HEAP_SORT = function () { 36 this.BUILD_HEAP(); //生成最大堆 37 for (var i = this.length - 1; i > 0; i--) { 38 this.swap(0, i); //将最大的数即第一个元素放到最后。 39 heap_size = i; 40 this.MAX_HEAPTIFY(0); 41 } 42 }; 43 44 var A = [3, 4, 5, 1, 2, 6, 8, 3]; 45 var heap_size = A.length; //包括heap_size在内的后面的坐标,都是排序好的。 46 A.HEAP_SORT(); 47 console.log(A);
如果对上诉描述还是不清楚,下面给出算法导论里的习题,方面大家一步步更深的理解:
习题一:当A[i]比其两子女都大的时候,调用MAX-HEAPIFY(A,i)的效果是怎么样?
答案:其实没变化的,我们可以看最后的if(largest!=i),才会递归下去,不然不变。这是算法导论里的伪代码:

习题二:对i>heap-size[A]/2,调用MAX-HEAPIFY(A,i)会怎么样?
分析:我们知道heap-size[A]后面都是排好序的,那heap-size[A]/2的位置便是最后一个非叶子节点,
当i>heap−size[A]/2,结点为叶子结点没有孩子,所以不会有任何改变。
习题三:MAX-HEAPIFY效率虽然高,但是第十行,可能导致某些编译程序产生出低效的代码,请把递归改成迭代:
1 Max-Heapify(A, i) 2 while true 3 l = Left(A, i) 4 r = Right(A, i) 5 if l <= A.heap-size and A[l] > A[i] 6 largest = l 7 else 8 largest = i 9 if r <= A.heap-size and A[r] > A[largest] 10 largest = r 11 if largest != i 12 swap A[i] with A[largest] 13 i = largest 14 else 15 break
整个堆排序的算法:

到此为止,堆排序已经全部讲解完了,我们发现核心的函数就MAX-HEAPTITY,他的时间复杂度其实是和这个二叉树的高度成正比的,我们可以认为是O(lgn).步骤就是先建立一个堆,建完就把第一个元素【最大或者最小】放到最后,如此循环,只到全部排序完毕。
虽然堆排序很优秀,但是快排其实用的更多,但是代表堆排序作用小,最小/最大优先级队列其实是搜索查找的启蒙算法。他就是基于堆排 .
1 //生成以i为根节点的最大堆 2 Array.prototype.MAX_HEAPTIFY = function (i) { 3 var largest = i; 4 var left = i * 2 + 1; //左孩子节点坐标 5 var right = i * 2 + 2; //右孩子节点坐标 6 7 if (left < heap_size && this[left] > this[largest]) { //这其实是一个剪枝的过程,因为heap_size后面都是排序好的。 8 largest = left; 9 } 10 if (right < heap_size && this[right] > this[largest]) { 11 largest = right; 12 } 13 if (largest !== i) { 14 this.swap(i, largest); 15 arguments.callee.call(this, largest); 16 } 17 }; 18 19 //将父节点的值和最大值交换 20 Array.prototype.swap = function (i, j) { 21 var temp = this[i]; 22 this[i] = this[j]; 23 this[j] = temp; 24 }; 25 26 //生产最大堆 27 Array.prototype.BUILD_HEAP = function () { 28 var lastP = Math.floor(this.length / 2) - 1; //最后一个非叶子节点。 29 for (var k = lastP; k >= 0; k--) { 30 this.MAX_HEAPTIFY(k); 31 } 32 }; 33 34 //返回集合中子最大的关键字 35 Array.prototype.HEAP_MAXIMUM = function () { 36 return this[0] 37 }; 38 39 //去掉并返回集合中的具有最大关键字的元素 40 Array.prototype.HEAP_EXTRACT_MAX = function () { 41 //if (heap_size2 < 1) { 42 //必须保证有元素 43 if (this.length < 1) { 44 throw new Error("heap underflow"); 45 } 46 var max = this[0]; 47 //this[0] = this[heap_size2]; //把最后一个元素放到最前面, 48 this[0] = this[this.length-1]; //把最后一个元素放到最前面, 49 this.pop(); //将最后一个元素删除 50 // --heap_size2; //此时因为弹出了一个元素,存储就少了 51 this.MAX_HEAPTIFY(0); 52 return max; 53 54 }; 55 //将元素x的关键字的值增加到k 56 Array.prototype.HEAP_INCREASE_KEY = function (i, key) { 57 if (key < this[i]) { 58 throw new Error("太小了"); 59 } 60 this[i] = key; 61 function parent(x) { 62 return Math.floor(x / 2); 63 } 64 65 while (i > 0 && this[parent(i)] < key) { 66 this.swap(parent(i), i); 67 i = parent(i); 68 } 69 }; 70 71 72 //把元素key插入集合 73 Array.prototype.MAX_HEAP_INSERT = function (key) { 74 // heap_size2++; 75 // this[heap_size2] = Number.NEGATIVE_INFINITY; 76 this[this.length] = Number.NEGATIVE_INFINITY; 77 //this.HEAP_INCREASE_KEY(heap_size2, key); 78 this.HEAP_INCREASE_KEY(this.length - 1, key); 79 }; 80 81 82 var A = [4, 9, 3, 11, 7, 22, 6, 8, 33, 57, 2, 5, 8]; 83 var heap_size = A.length; 84 //var heap_size2 = A.length - 1; 85 A.BUILD_HEAP(); 86 console.log(A); 87 console.log(A.HEAP_MAXIMUM()); 88 console.log(A.HEAP_EXTRACT_MAX()); 89 console.log(A); 90 A.MAX_HEAP_INSERT(100); 91 console.log(A); 92 A.HEAP_INCREASE_KEY(1, 99); 93 console.log(A);
以上是关于算法分析-堆排序 Heap Sort的主要内容,如果未能解决你的问题,请参考以下文章