逻辑斯谛回归
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑斯谛回归相关的知识,希望对你有一定的参考价值。
逻辑斯谛分布
设X是连续随机变量,X服从逻辑斯谛分布是指X服从如下分布函数和密度函数:
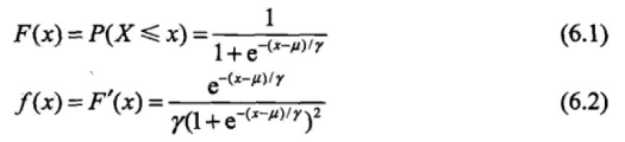
其中,为位置参数,> 0 为形状参数。
密度函数f(x)和分布函数F(x)的图形如图所示:
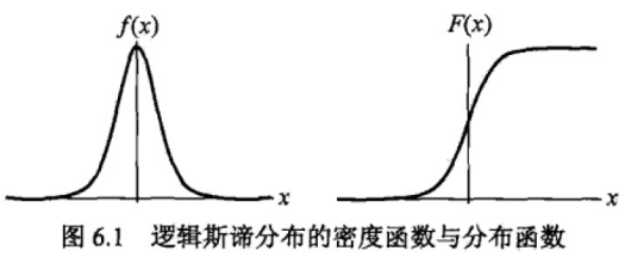
分布函数属于逻辑斯谛函数,其图形是一条S形曲线,该曲线以点(μ,½)为中心对称,即满足;
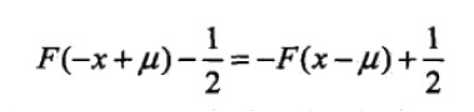
曲线在中心附近增长速度较快,在两端增长速度较慢,形状参数γ的值越小,曲线在中心附近增长的越快。
二项逻辑斯谛回归模型
是一种分类模型,由条件概率分布表示,形式为参数化的逻辑斯谛分布。随机变量x的取值为实数,随机变量y的取值为1或0,通过监督学习的方法来估计模型参数。
其条件概率模型如下:
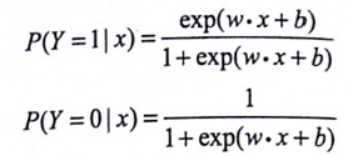
其中x∈Rn是输入,y∈{0,1}输出,w,b是模型参数——w是权值向量,b称作偏置,w·x是向量内积。
比较两个条件概率值的大小,将实例x分到概率值较大的那一类。
为了方便将权值向量w和输入向量x加以拓充w=(w(1),w(2),…w(n),b)T,x=(x(1),…x(n),1)T,此时逻辑斯谛模型可以表示为:
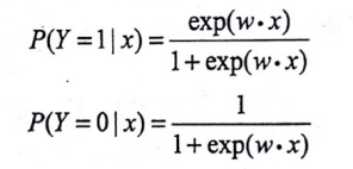
事件发生的几率
是指该事件发生的概率和事件不发生的概率的比值。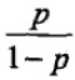
定义对数几率:
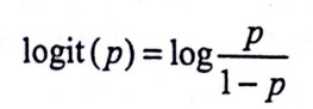
对逻辑斯蒂而言:
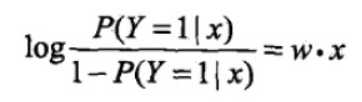
即输出Y=1的对数几率是输入x的线性函数。或者说输出Y=1的对数几率是由输入x的线性函数表示的模型,即逻辑斯蒂回归模型。
换一个角度,通过逻辑斯谛回归模型可以将线性函数w•x转换为概率:
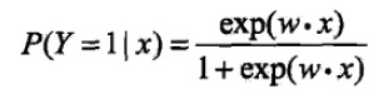
线性函数w·x的值越接近正无穷,概率值越接近1,越接近负无穷,概率值越接近0。这样的模型就是逻辑斯谛回归模型。
模型参数估计
逻辑斯谛回归模型学习时,可以应用极大似然估计法估计模型参数,从而得到逻辑斯谛回归模型。(极大似然估计法参见附录)
在模型学习的时候,对于给定训练集T = {(x1,y1)…(xN,yN)},x∈Rn,y∈{0,1}
设
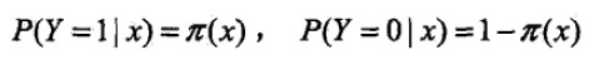
似然函数为
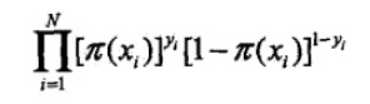
则有对数似然函数
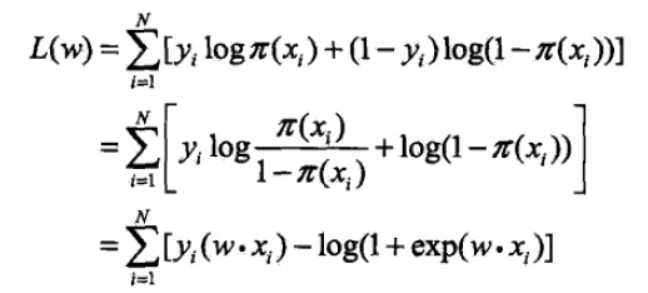
对L(w)求极大值,得到w的估计值。这样问题就变成了以对数似然函数为目标函数的最优化问题。逻辑斯谛回归中通常采用的方法是梯度下降法及拟牛顿法。
多项逻辑斯谛回归
上面介绍的二分类模型可以推广到用于多分类的多项模型。假设随机变量的取值集合是{1,2,3.......K},那么多项逻辑斯谛回归模型是
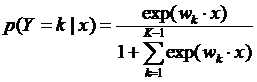
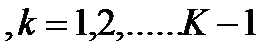
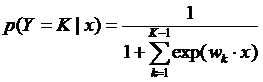
附录:极大似然估计法
它是建立在极大似然原理的基础上的一个统计方法,极大似然原理的直观想法是:一个随机试验如有若干个可能的结果A,B,C,…。若在仅仅作一次试验中,结果A出现,则一般认为试验条件对A出现有利,也即A出现的概率很大。一般地,事件A发生的概率与参数theta相关,A发生的概率记为P(A,theta),则theta的估计应该使上述概率达到最大,这样的theta顾名思义称为极大似然估计。
求极大似然函数估计值的一般步骤:
(1) 写出似然函数;
(2) 对似然函数取对数,并整理;
(3) 求导数 ;
(4) 解似然方程 。
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。极大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
当然极大似然估计只是一种粗略的数学期望,要知道它的误差大小还要做区间估计。
参考:
《统计学习方法》
http://www.hankcs.com/ml/the-logistic-regression-and-the-maximum-entropy-model.html
百度百科
以上是关于逻辑斯谛回归的主要内容,如果未能解决你的问题,请参考以下文章