关于C中struct和union长度的详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于C中struct和union长度的详解相关的知识,希望对你有一定的参考价值。
这几天看《代码大全》中的第十三章---不常见的数据类型,里面讲解到了C语言中的struct以及对指针的解释,联想到以前看过相关的关于C语言中stuct长度的文章,只是现在有些淡忘了,因此今天把保存的资料重新拿出来温习一遍,同时写下这篇文章,对以前相关资料总结的同时顺便梳理一下已有的知识。
一、基本数据类型在内存中的长度
关于基本的数据类型,在不同的机器上占据的长度不一样。为了能够对数据的组合类型(这里只包括了struct和union)能够有一个清晰地认识,这里首先对基本的数据类型在不同位数(32位和64位)的机器上占据的位数做一个简单的总结。简单的数据类型一般就是语言内置的数据类型,常用的一般分为:char, short, int, long, float, double, long double, longlong。即使系统都是64位或者32位,但是仍然可能产生不同的结果,其主要原因在于编译器的不同。在64位的VS2013环境下编译器设置为X32和X64两种情况,得到的结果如图1所示;在32位系统下无法将编译器的环境设置为64位,此时运行程序将会报错,在32位机器上不同类型的数据占据的字节数如图2所示。
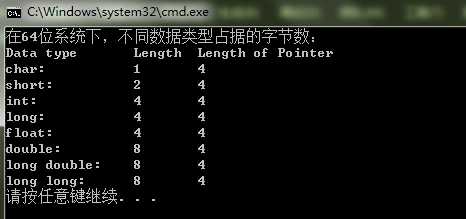
图1 (a)64位系统,设置编译器位32位环境下数据类型占据的字节数
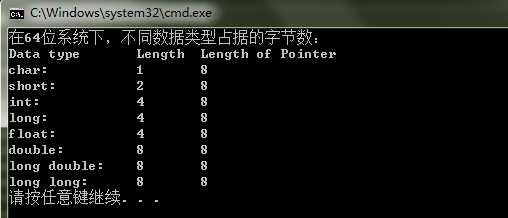
图1 (b)64位系统,设置编译器为X64位环境下数据类型占据的字节数
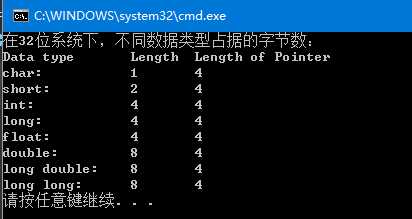
图2 32位机器系统下数据类型占据的字节数
当然,如果是不同版本的64位编译器中long和int有可能占据8个字节的长度,这取决于编译器的环境。关于不同的数据类型占据的不同字节数,另有解释如表 1:
| LP64 | ILP64 | LLP64 | ILP32 | LP32 | |
|
char |
8 | 8 | 8 | 8 | 8 |
| short | 16 | 16 | 16 | 16 | 16 |
| int | 32 | 64 | 32 | 32 | 16 |
| long | 64 | 64 | 32 | 32 | 32 |
| float | 32 | 32 | 32 | 32 | 32 |
| double | 64 | 64 | 64 | 64 | 64 |
| long double | 64 | 64 | 64 | 64 | 64 |
| long long | N/A | N/A | 64 | N/A | N/A |
| pointer | 64 | 64 | 64 | 32 | 32 |
表1 不同环境下不同数据类型所占据的长度
在这张表中,LP64,ILP64,LLP64是64位环境下的字长模型,ILP32和LP32是32位环境下的字长模型。LP64的意思是Long和pointer占据64位;ILP64代表int,long,pointer占据64位;LLP64是long long和pointer占据64位;ILP32代表int,long和pointer占据32位;LP32代表long和pointer占据32位。
32位的windows环境使用的是ILP32字长模型;64位windows采用的是LLP64字长模型,因此出现在在64位和32位环境下只有指针和long long类型所占据的字节数不一致的情况。
还有一点值得说明的是:在具体的环境平台中,指针所占据的字节数与数据类型无关,至于平台有关。这是因为,指针只是保存了某个变量的起始地址而已,只有具有特定类型的指针才能够被解释。
二、struct的长度
在不支持基于类的编程的语言中,使用结构体变量能够带来以下好处:
- 结构体可以明确数据关系;
- 结构体简化对数据块的操作,如赋值;
- 结构体简化参数列表,函数的形参可以用结构体代替众多的形参;
- 结构可可以简化对代码的维护难度;
在说明,结构体的长度之前首先要说明计算机中的数据地址的对齐概念。什么是数据地址的对齐,以及为什么要将数据的地址进行对齐?
对齐:现代计算机中内存的空间都是按照byte划分的,从理论上来讲似乎对任何类型的变量的访问可以从任何的地址开始,但是实际情况是在访问特定的变量的时候经常在特定的内存地址访问,这就需要各类型的数据按照一定的规则在空间上排雷,而不是顺序的一个接一个的存放,这就是对齐。
原因:各个硬件平台对存储空间的处理有很大的不同。一些平台对某些特定类型的数据只能从特定地址开始存取。其他平台可能没有这些情况,但是最常见的情况时如果不按照适合其平台要求的方式对数据进行存取,会在存取效率上带来损失。比如有些平台每次读都是懂欧迪芝开始,如果一个int型(32位系统)的存放地址是从欧迪芝开始的,那么一个周期就可以将其读出来;如果存放在奇地址开始的地方,就可能需要两个周期才能读出来,显然降低了读取的效率。这也就是空间和时间的博弈。
对齐的算法:
由于各个编译器的不同,现在已64位编译器为例将对齐的方式做一个梳理。
设结构体有如下的定义:
struct A{
int a;
char b;
short c;
};
结构体A包含了一个4个字节长度的int类型、一个1个字节长度的char类型、一个两个字节长度的short类型,所以需要的总的有效的存储空间为7 bytes,但是由于编译器的对齐,造成sizeof(A)=8,如图3所示。

图3 结构体A的长度
但是如果调换结构体中元素的顺序,那么结构体的长度就会发生一定的变化,现在重新定义结构体B为:
struct B{
char b;
int a;
short c;
}
同样总的有效存储空间为7,但是此时sizeof(B)=12,如图4所示。

图4 结构体B的长度
上面使用的都是默认的对齐方式,如果使用预编译指令#pragma pack(value)来告诉编译器,使用程序员指定的对齐方式来代替默认的对其方式,那么同样的结构体的长度就会再次发生变化。如果在结构体B的定义前加上#pragma pack(2),变为如下定义:
#pragma pack(2) //指定两字节的对齐方式
struct C{
char b;
int a;
short b;
}
#pragma pack() //取消指定的对齐方式,恢复默认
此时,sizeof(C)=8,如图5所示。

图5 指定对齐方式位2字节之后结构体的长度
如果修改对齐方式为1字节,也就是用#pragma pack(1)代替#pragma pack(2),则此时sizeof(C)=7,如图6所示。

图6 指定对齐方式为1字节之后的结构体长度
为了弄清楚上述的变化,现在需要明确四个概念:
- 数据类型的自身对齐值:就是数据类型在内存中所占据的字节数;
- 指定对其值:#pragma pack(value)中指定的对齐值value;
- 结构体的自身对齐值:成员变量中自身对齐值最大的那个值;
- 数据成员、结构体的有效对齐值:自身对齐值和指定对齐值中较小的那个值;
有了这些概念之后我们就可以很方便的讨论具体数据结构的成员和结构体的自身的对齐方式了。下面一段话用于说明对齐的方式,是判定结构体长度的关键性步骤。
有效对齐值是最终用来决定数据存放方式的值,最为重要。有效对齐值N,以N为基础进行对齐。也就是说数据的存放地址应该满足“存放地址%N=0”。结构体的数据变量都是按照定义的先后顺序来存放的,第一个数据变量的起始地址就是数据结构的起始地址。结构体的变量要对齐排放,结构体本身也要根据自身的有效对齐值进行调整(也就是说结构成员变量占用总长度应该是结构体有效对齐值得整数倍)。
这样,就不难理解上面所列出的结构体的长度为何不同了。以struct B为例进行分析。假设B地址从地址空间0x0000开始存放,该例子中没有指定对其值,在笔者的编译器环境下,改值默认为B中占据最大长度的成员变量的自身对其值,也就是占据四个字节的int的自身对齐值。第一个成员变量b的自身对其值为1,比默认的对齐值4小,因此其有效对齐值为1,所以其存放地址0x0000符合0x0000%1=0。第二个成员变量a,其自身的对齐值为4,有效对齐值也是4,所以只能存放在起始地址为0x0004到0x0007这四个连续的字节空间中,符合0x0004%4=0,且紧靠在第一个成员变量之后。第三个成员变量c,自身的对齐值为2,默认的对齐值为4,所以有效对齐值为2,可以放在0x0008到0x0009的空间范围内。再看数据结构B的自身对齐值为其变量中最大对齐值,也就是4,所以结构体的有效对齐值也就是4,根据结构体的调整要求,从0x000A到0x000B也应该为结构体B所占用。因此B占据了从0x0000到0x000B的12个字节,因此sizeof(B)=12.
同样的道理可以分析struct C。C中使用预编译指令#pragma pack(2),指定了对齐值为2。对于第一个成员变量b,其自身的对齐值为1,指定对其值为2,因此有效的对齐值为1。同样假设C从0x0000开始,那么b存放在0x0000开始的位置,符合0x0000%1=0;第二个变量,自身的对齐值为4,指定的对齐值为2,所有有效的对齐值为2,所以顺序存放在0x0002、0x0003、0x0004、0x0005四个连续的字节中,符合0x0002%2=0。第三个变量C的自身对齐值为2,指定对其值为2,因此有效对齐值为2,顺序存放。在0x0006和0x0007中,存放变量C,同样符合0x0006%2=0。所以从0x0000到0x0007共八个字节存放的是C的变量。又因为C的自身对齐值为4,所以C的有效对其值2,而8%2=0,C只占用了0x0000-0x0007共8个字节的空间。
还有需要说明的一点是,结构体之间的组合使用方式下,也就是结构体中包含着另一个结构体。则内部结构体要从其内部最大元素大小的整数倍地址开始存储(如struct E中含有struct F,而struct F中含有char,int,double等元素,那么F应该从8的整数倍开始存储 )。例子如下:
struct F{
char a;
int b;
double c;
};
struct E{
char b;
int a;
short c;
struct F obj;
char e;
};
此时,sizeof(E)=40。

图7 组合结构体的大小
首先假设struct E从0x0000开始,按照对B和C的分析可得其中各个变量的自身对齐值、有效对齐值,以及其实地址如表2所示。需要注意的一点是,这里struct E中元素的自身对齐值中最大的是struct F中的元素的c的自身对其值,为8.
| 自身对齐值 | 有效对齐值 | 起始地址 | |
| E.b | 1 | 1 | 0x0000 |
| E.a | 4 | 4 | 0x0004 |
| E.c | 2 | 2 | 0x0008 |
| E.F.a | 1 | 1 | 0x0010 |
| E.F.b | 4 | 4 | 0x0014 |
| E.F.c | 8 | 8 | 0x0018 |
| E.e | 1 | 1 | 0x0020 |
表2 不同元素的自身对其值、有效对齐值以及起始地址
最后一个元素E.e的起始地址为0x0020,因此0x0020存放着E.e,但是struct E的有效对齐值为8,根据调整的原则,从0x0021到0x0028之间的空间也要划归E所占用,因此E的空间总的大小为40。
三、联合体(union)
联合体是一种使用相对使用较少的结构体。联合体中的所有的变量共享同一个内存位置,在不同的时间保存不同的数据类型和不同长度的变量。在union中,所有的联合体成员共用一个空间,并且同一时间只能存储其中一个成员变量的值。当一个联合体被声明的时候,编译程序自动生成一个变量,其长度为联合体中元类型最大的变量长度的整数倍,且要大于等于其最大成员变量所占用的存储空间。
union G
{
char name[30];
double al;
char sex;
int age;
float height;
};
此时,G需要占用空间最大的是元素char name[30],但是元类型中占用空间最大的是double,为8个字节。但是联合体G需要是al的整数倍且大于等于30,因此sizeof(G)=32,如图8所示。

图8 联合体的大小
单个联合体比较容易理解,但是还有两种情况就是联合体重包含着结构体和结构体中包含着联合体,下面分别介绍。
- 联合体中包含结构体
联合体中包含着结构体时,其判定方法和联合体单独联合体相似。其实联合体中的数组可以看成一种特殊的结构体,该结构体中所有的元素具有相同的类型。仍然是取联合体中所有元素的最大值,补齐方式仍然是元类型的变量的最大长度的整数倍。例如:
struct inner{
char a;
double b;
char c;
};
union data{
struct innner a;
int b;
char c;
};
其中sizeof(inner)=24,为data中的占用空间最大的元素;占用空间最大的元类型元素为b,为4字节,因此无需再额外的补全。所以sizeof(inner)=24。

图9 联合体包含结构体的大小
2. 结构体中包含联合体
当在结构体中包含联合体时,联合体在结构体中的对齐地址为联合体本身内部所用的对齐方式。例如:
union H{
int a;
int array[5];
char c;
};
struct I{
int a;
short b;
union H c;
char d[5];
};
根据对union的介绍,union H的大小sizeof(H)=20;在struct I中,a和b占据了前8个字节,c应该从4的整数倍开始排列,因此sizeof(I)=4+2+2(补齐)+20+5+3(补齐)=36。在计算机上的大小以及各个元素的其实地址如图10所示。
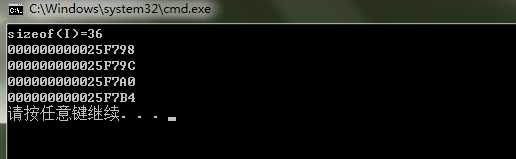
图10 结构体中包含联合体时的大小及各个元素的起始地址
总结:
1.联合体和结构体都是有多个不同的数据类型数据成员组成,但是在同一个时刻,联合体只存放了一个被选中的成员而结构体中的所有成员都存在;
2.对于联合体的不同成员赋值,将会对其他的变量重写,原来变量的值就不存在了,而对于结构体的不同成员赋值,彼此之间是互不影响的;
3.不同类型的成员所占据的内存空间的大小是理解struct大小的基础;
以上是关于关于C中struct和union长度的详解的主要内容,如果未能解决你的问题,请参考以下文章