jdk1.8 HashMap 实现 数组+链表/红黑树
Posted todayjust
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jdk1.8 HashMap 实现 数组+链表/红黑树相关的知识,希望对你有一定的参考价值。
转载至 http://www.cnblogs.com/leesf456/p/5242233.html
一、前言
在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Java8的HashMap对之前做了较大的优化,其中最重要的一个优化就是桶中的元素不再唯一按照链表组合,也可以使用红黑树进行存储,总之,目标只有一个,那就是在安全和功能性完备的情况下让其速度更快,提升性能。好~下面就开始分析源码。
二、HashMap数据结构
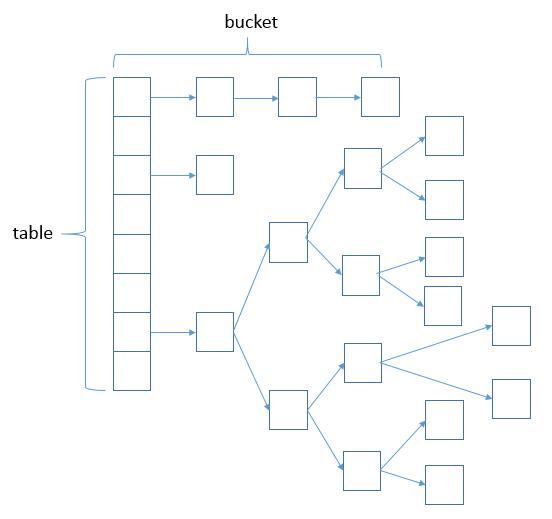
说明:上图很形象的展示了HashMap的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树的引入是为了提高效率。所以可见,在分析源码的时候我们不知不觉就温习了数据结构的知识点,一举两得。
三、HashMap源码分析
3.1 类的继承关系
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
可以看到HashMap继承自父类(AbstractMap),实现了Map、Cloneable、Serializable接口。其中,Map接口定义了一组通用的操作;Cloneable接口则表示可以进行拷贝,在HashMap中,实现的是浅层次拷贝,即对拷贝对象的改变会影响被拷贝的对象;Serializable接口表示HashMap实现了序列化,即可以将HashMap对象保存至本地,之后可以恢复状态。
3.2 类的属性
 View Code
View Code
说明:类的数据成员很重要,以上也解释得很详细了,其中有一个参数MIN_TREEIFY_CAPACITY,笔者暂时还不是太清楚,有读者知道的话欢迎指导。
3.3 类的构造函数
1. HashMap(int, float)型构造函数
View Code说明:tableSizeFor(initialCapacity)返回大于initialCapacity的最小的二次幂数值。
View Code说明:>>> 操作符表示无符号右移,高位取0。
2. HashMap(int)型构造函数。
View Code3. HashMap()型构造函数。
View Code4. HashMap(Map<? extends K>)型构造函数。
View Code说明:putMapEntries(Map<? extends K, ? extends V> m, boolean evict)函数将m的所有元素存入本HashMap实例中。
View Code3.4 重要函数分析
1. putVal函数
View Code说明:HashMap并没有直接提供putVal接口给用户调用,而是提供的put函数,而put函数就是通过putVal来插入元素的。
2. getNode函数
View Code说明:HashMap并没有直接提供getNode接口给用户调用,而是提供的get函数,而get函数就是通过getNode来取得元素的。
3. resize函数
View Code说明:进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
在resize前和resize后的元素布局如下
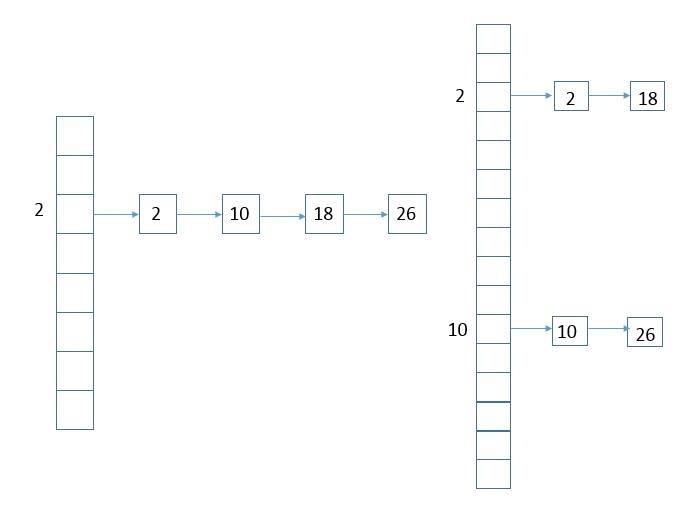
说明:上图只是针对了数组下标为2的桶中的各个元素在扩容后的分配布局,其他各个桶中的元素布局可以以此类推。
四、针对HashMap的思考
4.1. 关于扩容的思考
从putVal源代码中我们可以知道,当插入一个元素的时候size就加1,若size大于threshold的时候,就会进行扩容。假设我们的capacity大小为32,loadFator为0.75,则threshold为24 = 32 * 0.75,此时,插入了25个元素,并且插入的这25个元素都在同一个桶中,桶中的数据结构为红黑树,则还有31个桶是空的,也会进行扩容处理,其实,此时,还有31个桶是空的,好像似乎不需要进行扩容处理,但是是需要扩容处理的,因为此时我们的capacity大小可能不适当。我们前面知道,扩容处理会遍历所有的元素,时间复杂度很高;前面我们还知道,经过一次扩容处理后,元素会更加均匀的分布在各个桶中,会提升访问效率。所以,说尽量避免进行扩容处理,也就意味着,遍历元素所带来的坏处大于元素在桶中均匀分布所带来的好处。如果有读者有不同意见,也欢迎讨论~
以上是关于jdk1.8 HashMap 实现 数组+链表/红黑树的主要内容,如果未能解决你的问题,请参考以下文章