Spark2.0安装配置文档
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark2.0安装配置文档相关的知识,希望对你有一定的参考价值。
Spark安装指南
该文档是建立在已经安装好hadoop和jdk的基础上,并且已经设置好HADOOP_HOME环境变量以及JAVA_HOME环境变量,测试和现网环境需要在原来的hadoop环境中安装。
1 下载安装包
从scala官网下载scala-2.11.8.tgz、spark-2.0.0-bin-hadoop2.7.tgz两个安装包到集群各个节点机器上。(下面是两个官网地址)
http://www.scala-lang.org/files/archive/scala-2.11.8.tgz
http://d3kbcqa49mib13.cloudfront.net/spark-2.0.0-bin-hadoop2.7.tgz
2 安装Scala
解压安装包:tar -zxvf scala-2.11.8.tgz,可以解压到/usr/local目录下(根据自己需要解压到某个路径),配置环境变量/etc/profile,
添加如下两行:
export SCALA_HOME=/usr/local/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/sbin
测试输入scala命令,返回如下界面,安装成功

3 配置Spark
1、解压添加环境变量
解压安装包:tar -zxvf spark-2.0.0-bin-hadoop2.7.tgz,可以解压到/usr/local/hadoop/下(可根据具体环境修改),配置环境变量/etc/profile,添加如下两行内容。
export SPARK_HOME=/housr/local/hadoop/spark-2.0.0-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
2、修改配置文件 spark-env.sh
在主节点上进入spark安装目录 conf目录执行如下命令:
- cp spark-env.sh.template spark-env.sh
- vi spark-env.sh
- 添加 hadoop、scala 、java环境变量
3、编辑slaves文件,你可以执行如下命令:
- cp slaves.template slaves
- vi slaves
- 添加集群里面所有主机名(注,需在hosts文件中添加各主机的hostname和ip的对应关系)
至此,master节点上的Spark已配置完毕。
把master上Spark相关配置复制到集群从节点中,注意,三台机器spark所在目录必须一致,因为master会登陆到worker上执行命令,master认为worker的spark路径与自己一样。
5 启动
执行如下命令:
1、cd $SPARK_HOME/bin
2、./start-all.sh
6 测试
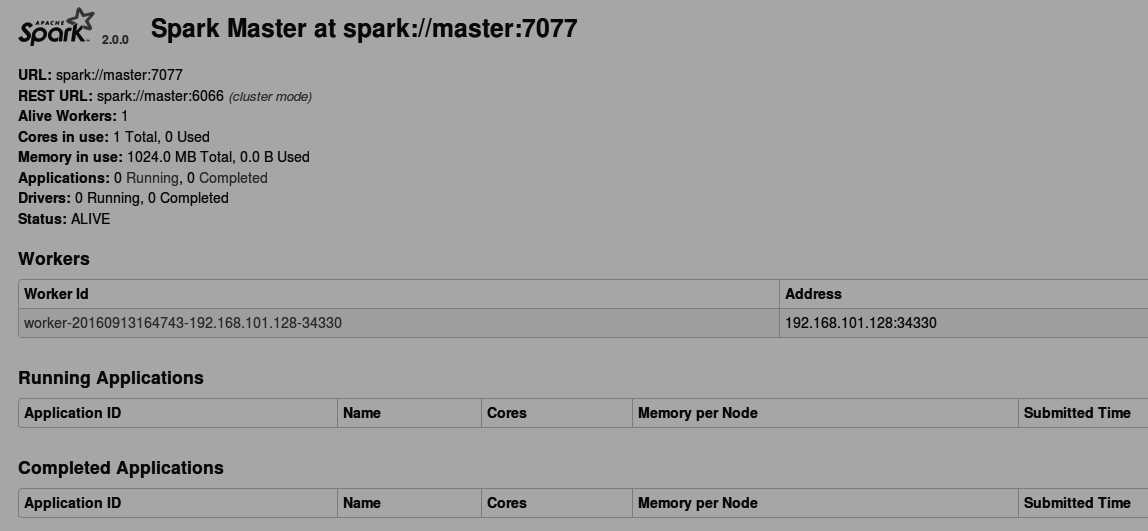
通过浏览器输入 主节点集群ip地址加上默认8080端口号访问,出现如下图所示界面,表示安装成功。
以上是关于Spark2.0安装配置文档的主要内容,如果未能解决你的问题,请参考以下文章
windows 本地构建hadoop-spark运行环境(hadoop-2.6, spark2.0)