SparkCentOS7.5之Spark2.3.1HA安装
Posted bky-summer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkCentOS7.5之Spark2.3.1HA安装相关的知识,希望对你有一定的参考价值。
一 下载安装包
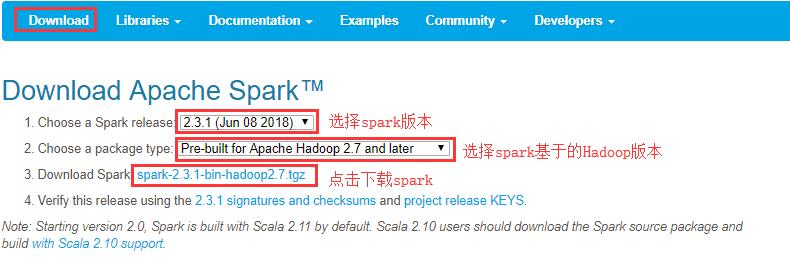
1 官方下载
官方下载地址:http://spark.apache.org/downloads.html
2 安装前提
- Java8 安装成功
- zookeeper 安装成功
- hadoop 安装成功
- Scala 安装成功
注意:从Spark2.0版开始,默认使用Scala 2.11构建。Scala 2.10用户应该下载Spark源包并使用Scala 2.10支持构建 。
3 集群规划
| 节点名称 | Zookeeper | Master | Worker |
| node21 |
QuorumPeerMain |
主Master | |
| node22 |
QuorumPeerMain |
备Master | Worker |
| node23 |
QuorumPeerMain |
Worker |
二 集群安装
1 解压缩
[admin@node21 software]$ tar zxvf spark-2.3.1-bin-hadoop2.7.tgz -C /opt/module/ [admin@node21 module]$ mv spark-2.3.1-bin-hadoop2.7 spark-2.3.1
2 修改配置文件
(1)进入配置文件所在目录

[admin@node21 ~]$ cd /opt/module/spark-2.3.1/conf/ [admin@node21 conf]$ ll total 36 -rw-rw-r-- 1 admin admin 996 Jun 2 04:49 docker.properties.template -rw-rw-r-- 1 admin admin 1105 Jun 2 04:49 fairscheduler.xml.template -rw-rw-r-- 1 admin admin 2025 Jun 2 04:49 log4j.properties.template -rw-rw-r-- 1 admin admin 7801 Jun 2 04:49 metrics.properties.template -rw-rw-r-- 1 admin admin 870 Jul 4 23:50 slaves.template -rw-rw-r-- 1 admin admin 1292 Jun 2 04:49 spark-defaults.conf.template -rwxrwxr-x 1 admin admin 4861 Jul 5 00:25 spark-env.sh.template
(2)复制spark-env.sh.template并重命名为spark-env.sh
[admin@node21 conf]$ cp spark-env.sh.template spark-env.sh [admin@node21 conf]$ vi spark-env.sh
编辑并在文件末尾添加如下配置内容
#指定默认master的ip或主机名 export SPARK_MASTER_HOST=node21 #指定maaster提交任务的默认端口为7077 export SPARK_MASTER_PORT=7077 #指定masster节点的webui端口 export SPARK_MASTER_WEBUI_PORT=8080 #每个worker从节点能够支配的内存数 export SPARK_WORKER_MEMORY=1g #允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用核心) export SPARK_WORKER_CORES=1 #每个worker从节点的实例(可选配置) export SPARK_WORKER_INSTANCES=1 #指向包含Hadoop集群的(客户端)配置文件的目录,运行在Yarn上配置此项 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop #指定整个集群状态是通过zookeeper来维护的,包括集群恢复 export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node21:2181,node22:2181,node23:2181 -Dspark.deploy.zookeeper.dir=/sparkmaster"
(3)复制slaves.template成slaves,并修改配置内容
[admin@node21 conf]$ cp slaves.template slaves [admin@node21 conf]$ vi slaves
修改从节点
node22 node23
(4)将安装包分发给其他节点
[admin@node21 module]$ scp -r spark-2.3.1 admin@node22:/opt/module/ [admin@node21 module]$ scp -r spark-2.3.1 admin@node23:/opt/module/
修改node22节点上conf/spark-env.sh配置的MasterIP为SPARK_MASTER_IP=node22
3 配置环境变量
所有节点均要配置
[admin@node21 spark-2.3.1]$ sudo vi /etc/profile export SPARK_HOME=/opt/module/spark-2.3.1 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin [admin@node21 spark-2.3.1]$ source /etc/profile
三 启动集群
1 启动zookeeper集群
所有zookeeper节点均要执行
[admin@node21 ~]$ zkServer.sh start
2 启动HDFS集群
[admin@node21 ~]$ start-dfs.sh [admin@node22 ~]$ start-yarn.sh
[admin@node23 ~]$ yarn-daemon.sh start resourcemanager
3 启动Spark集群
启动spark:启动master节点:sbin/start-master.sh 启动worker节点:sbin/start-slaves.sh
或者:sbin/start-all.sh
[admin@node21 spark-2.3.1]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.master.Master-1-node21.out node22: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.worker.Worker-1-node22.out node23: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.worker.Worker-1-node23.out
注意:备用master节点需要手动启动
[admin@node22 spark-2.3.1]$ sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.master.Master-1-node22.out
4 查看进程
[admin@node21 spark-2.3.1]$ jps 1316 QuorumPeerMain 3205 Jps 3110 Master 1577 DataNode 1977 DFSZKFailoverController 1788 JournalNode 2124 NodeManager [admin@node22 spark-2.3.1]$ jps 1089 QuorumPeerMain 1233 DataNode 1617 ResourceManager 1159 NameNode 1319 JournalNode 1735 NodeManager 3991 Master 4090 Jps 1435 DFSZKFailoverController 3918 Worker [admin@node23 spark-2.3.1]$ jps 1584 ResourceManager 1089 QuorumPeerMain 1241 JournalNode 2411 Worker 1164 DataNode 1388 NodeManager 2478 Jps
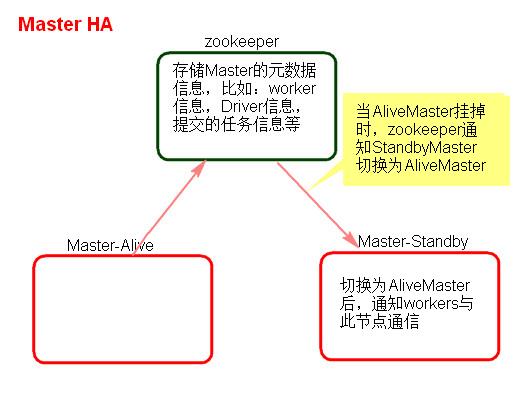
四 验证集群HA
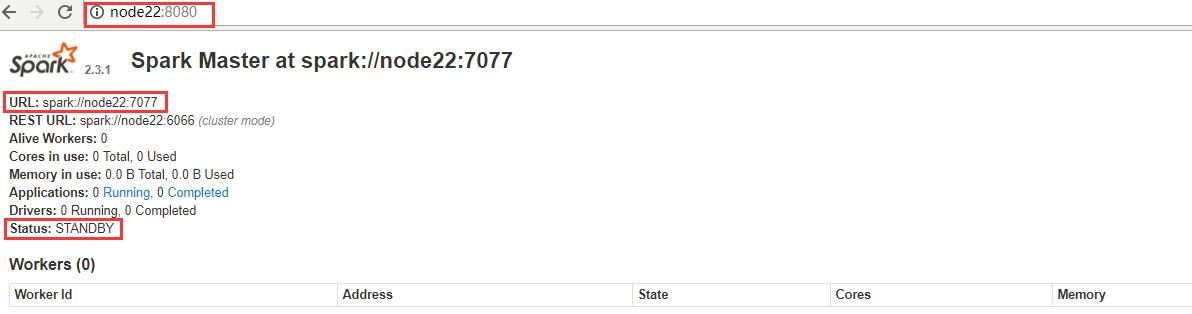
1 看Web页面Master状态
node21是ALIVE状态,node22为STANDBY状态,WebUI查看:http://node21:8080/

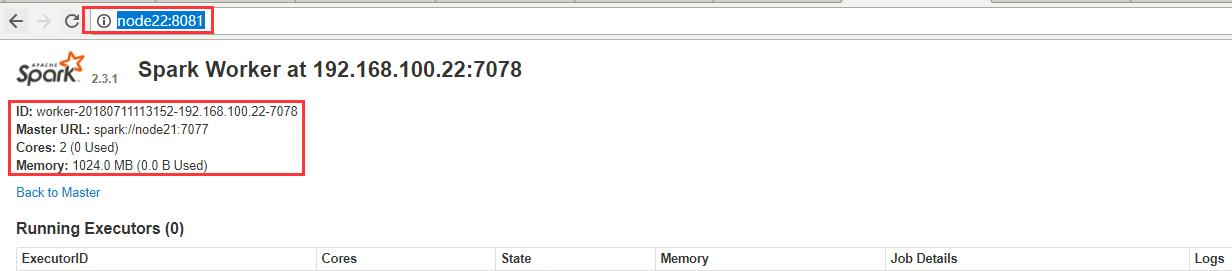
从节点连接地址:http://node22:8081/

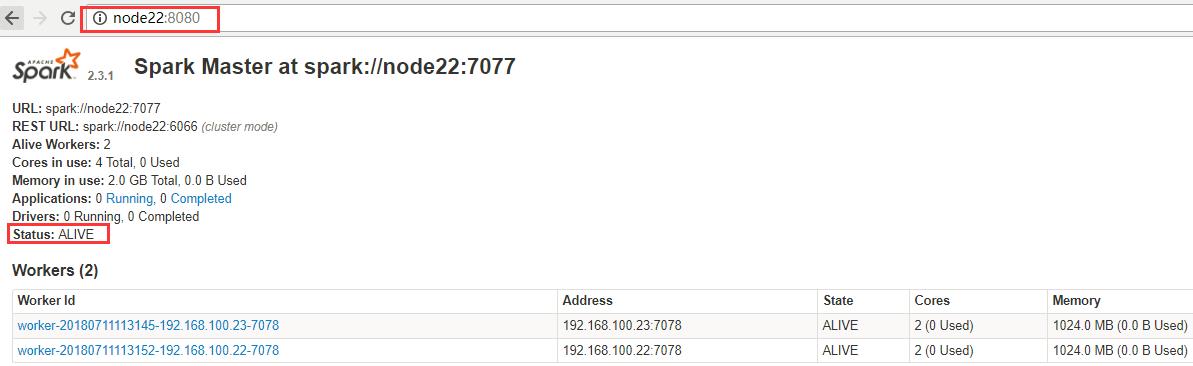
2 验证HA的高可用
手动干掉node21上面的Master进程,node21:8080无法访问,node22:8080状态如下,Master状态成功自动进行切换。
3 HA注意点
- 主备切换过程中不能提交Application。
- 主备切换过程中不影响已经在集群中运行的Application。因为Spark是粗粒度资源调度。
五 配置历史服务器
1 临时配置
对本次提交的应用程序起作用
./spark-shell --master spark://node21:7077 --name myapp1 --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs://node21:8020/spark/test
停止程序,在Web Ui中Completed Applications对应的ApplicationID中能查看history。
2 永久配置
spark-default.conf配置文件中配置HistoryServer,对所有提交的Application都起作用
在客户端节点,进入../spark-2.3.0/conf/ spark-defaults.conf最后加入:
//开启记录事件日志的功能 spark.eventLog.enabled true //设置事件日志存储的目录 spark.eventLog.dir hdfs://node21:8020/spark/test //设置HistoryServer加载事件日志的位置 spark.history.fs.logDirectory hdfs://node21:8020/spark/test //日志优化选项,压缩日志 spark.eventLog.compress true
启动HistoryServer:
./start-history-server.sh
访问HistoryServer:node21:18080,之后所有提交的应用程序运行状况都会被记录。
六 故障问题
1 Worker节点无法启动
[admin@node21 spark-2.3.1]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.master.Master-1-node21.out node23: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.worker.Worker-1-node23.out node22: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.worker.Worker-1-node22.out node23: failed to launch: nice -n 0 /opt/module/spark-2.3.1/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 --port 7078 spark://node21:7077 node23: full log in /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.worker.Worker-1-node23.out node22: failed to launch: nice -n 0 /opt/module/spark-2.3.1/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 --port 7078 spark://node21:7077 node22: full log in /opt/module/spark-2.3.1/logs/spark-admin-org.apache.spark.deploy.worker.Worker-1-node22.out
由于之前在conf/spark-env.sh里配置了如下信息
#每个worker从节点的端口(可选配置) export SPARK_WORKER_PORT=7078 #每个worker从节点的wwebui端口(可选配置) export SPARK_WORKER_WEBUI_PORT=8081
可能是由于端口问题去掉上述两项配置,重启成功。
2 启动Spark on YARN报错
Caused by: java.net.ConnectException: Connection refused
[admin@node21 spark-2.3.1]$ spark-shell --master yarn --deploy-mode client
报错原因:内存资源给的过小,yarn直接kill掉进程,则报rpc连接失败、ClosedChannelException等错误。
解决方法:
先停止YARN服务,然后修改yarn-site.xml,增加如下内容
<!--是否将对容器强制实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--设置容器的内存限制时虚拟内存与物理内存之间的比率 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
将新的yarn-site.xml文件分发到其他Hadoop节点对应的目录下,最后在重新启动YARN。
重新执行以下命令启动spark on yarn,启动成功
以上是关于SparkCentOS7.5之Spark2.3.1HA安装的主要内容,如果未能解决你的问题,请参考以下文章