hashmap底层实现原理是啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hashmap底层实现原理是啥?相关的知识,希望对你有一定的参考价值。
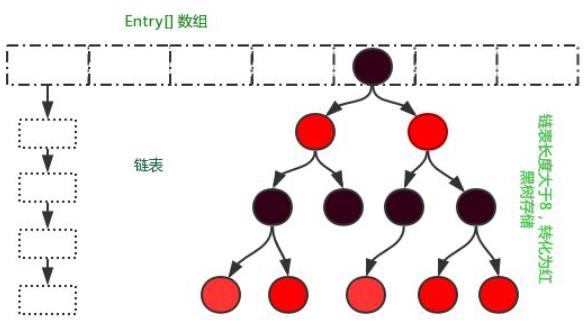
HashMap的实现原理:首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了。
这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。
当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组中。
HashMap 的实例有两个参数影响其性能:
初始容量和加载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。
加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。在Java编程语言中,加载因子默认值为0.75,默认哈希表元为101。
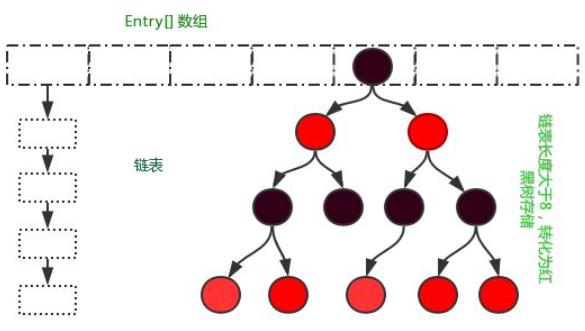
参考技术AHashMap的实现原理:首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了。
这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。
当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组中。
扩展资料
HashMap和Hashtable的区别
1、HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行。
2、HashMap是非synchronized,而Hashtable是synchronized。意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。
3、由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
5、HashMap不能保证随着时间的推移Map中的元素次序是不变的。
以上是关于hashmap底层实现原理是啥?的主要内容,如果未能解决你的问题,请参考以下文章
HashMap的底层实现原理? HashMap 和 Hashtable的异同? 负载因子值的大小,对HashMap有什么影响?