HashMap底层的实现原理
Posted ACGkaka_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap底层的实现原理相关的知识,希望对你有一定的参考价值。
目录
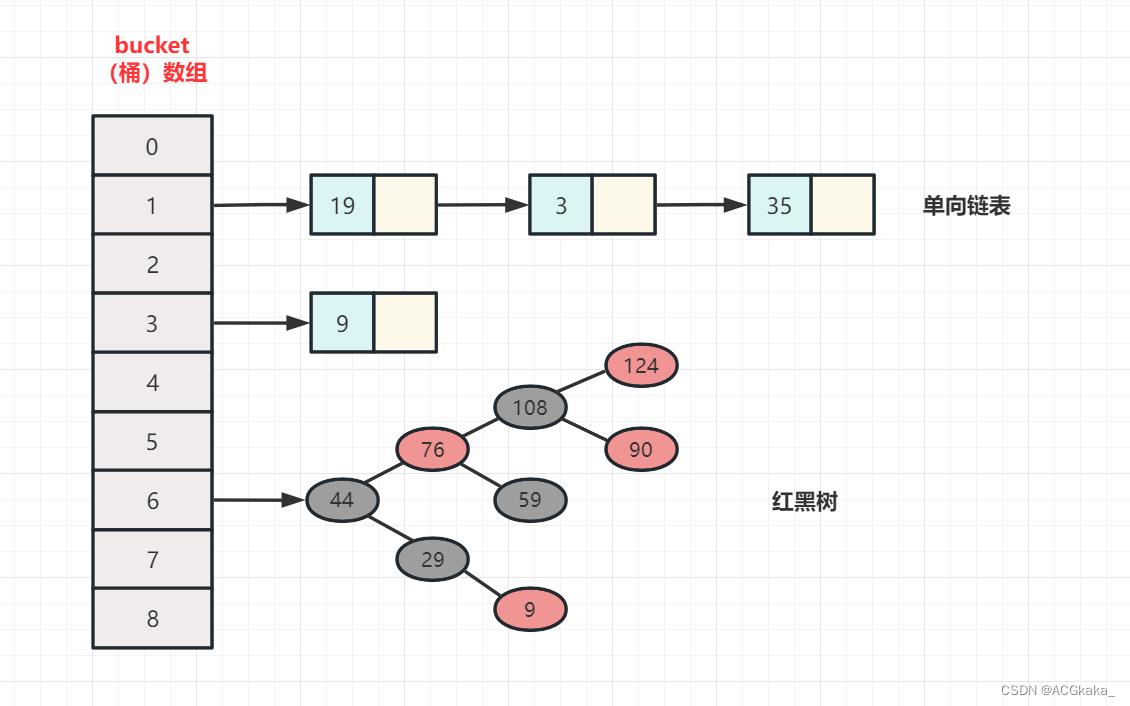
HashMap的底层是通过
数组+单向链表/红黑树实现的。
一、知识点回顾
数组特点:
- 存储区间是连续的,且占用内存严重,空间复杂度也很大,时间复杂度为 O(1)。
- 优点: 随机读取效率很高,原因是数组是连续的(随机访问性强,查找速度快)。
- 缺点: 插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中要后移,且大小固定不易动态扩展。
链表特点:
- 区间离散,占用内存宽松,空间复杂度小,时间复杂度 O(n)。
- 优点: 插入删除速度快,内存利用率高,没有大小固定,扩展灵活。
- 缺点: 不能随机查找,每次都是从第一个开始遍历(查询效率低)。
哈希表特点:
以上数组和链表,大家都知道各自优缺点。那么我们能不能把以上两种结合在一起使用,从而实现查询效率高和删除插入效率也高的数据结构呢?答案是可以滴,那就是哈希表可以满足,接下来我们一起复习下 HashMap 中的 put() 和 get() 方法实现原理。
二、HashMap 的 put() 和 get() 的实现
2.1 map.put(k, v) 实现原理
-
第1步,首先将 k, v 封装到 Node 对象当中(节点)。
-
第2步,它的底层会调用 K 的 hashCode() 方法得出 hash 值。
-
第3步,通过哈希表函数/哈希算法,将 hash 值转换成数组的下标:
- 下标位置上如果没有任何元素,就把 Node 添加到这个位置上;
- 如果说下标对应的位置上有链表,就会拿着 k 和链表上每个节点的 k 进行 equals:
- 如果所有的 equals 方法返回都是 false,那么这个新的节点将被添加到链表的末尾;
- 如其中有一个 equals 返回了 true,那么这个节点的 value 将会被覆盖。

2.2 map.get(k) 实现原理
- 第1步,先调用 k 的 hashCode() 方法得出哈希值,并通过哈希算法转换成数组的下标。
- 第2步,通过上一步哈希算法转换成数组的下标之后,再通过数组下标快速定位到链表所在位置上。
- 如果这个位置上什么都没有,则返回 null;
- 如果这个位置上有单向链表,那么它就会拿着参数 k 和单向链表上的每一个节点的 k 进行 equals:
- 如果所有 equals 方法都返回 false,则 get 方法返回 null;
- 如果其中一个节点的 k 和参数 k 进行 equals 返回 true,那么此时该节点的 value 就是我们要找的 value 了,get 方法最终返回这个要找的 value。

2.3 为何随机增删、查询效率都很高?
原因: 增删是在链表上完成的,而查询主要是通过数组定位,然后扫描部分链表,所以效率高。
HashMap 集合的 key,会先后调用两个方法:hashCode() 和 equals() 方法,所以当对象充当 key 时,这两个方法都需要重写。
2.4 为什么放在 HashMap 集合 key 部分的元素需要重写 equals 方法?
原因: 因为 equals 默认比较的是两个对象的内存地址,如果想根据对象的属性来判断,则需要重写。
2.5 HashMap总结
问题1: HashMap 的 key 为什么是无序的?
答: 因为不一定挂到哪一个单向链表上,因此加入顺序和取出也不一样。
问题2: HashMap 怎么保持不可重复?
答: 使用 equals 方法来保证 HashMap 的 key 不可重复。如果 key 重复的话,value 就会覆盖。存放在 HashMap 集合中的 key,其实就是存放在 HashSet 集合中,所以 HashSet 集合也需要重写 equals() 和 hashCode() 方法。
问题3: HashMap 是如何扩容的?
答: HashMap 集合的默认初始化容量为16,默认加载因子为 0.75,也就是说当 HashMap 集合底层数组的容量达到 75% 时,数组就开始扩容。HashMap 集合初始化容量是 2 的倍数,是为了达到散列均匀,提高 HashMap 集合的存取效率。
2.6 JDK8 之后,HashMap的改变
JDK8 之后,如果哈希表单向链表中元素超过 8 个,那么单向链表这种数据结构会变成红黑树数据结构。当红黑树上的节点数量小于 6 个,会重新把红黑树变成单向链表数据结构。
2.7 HashMap 的哈希碰撞
如果 key1 和 key2 的哈希值相同,就会存放到同一个单向链表上。
如果 key1 和 key2 的哈希值不同,但由于哈希算法执行结束之后转换的数组下标可能相同,此时会发生哈希碰撞。
2.8 HashMap 的 key 允许为 null 吗?
允许
JDK8 中 HashMap 的 put() 方法:
public V put(K key, V value)
// 采用 hash(key) 来计算 key 的 hashCode 值
return putVal(hash(key), key, value, false, true);
static final int hash(Object key)
int h;
// 当 key 为 null 的时候,不走 hashCode() 方法
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
HashMap 中使用 hash() 方法来计算 key 的哈希值,当 key 为 null 时,直接令 key 的哈希值为0,不走 key.hashCode() 方法,所以即使为 null 也不会抛出空指针异常。
整理完毕,完结撒花~ 🌻
参考地址:
1.来复习一波,HashMap底层实现原理解析,https://baijiahao.baidu.com/s?id=1665667572592680093&wfr=spider&for=pc
2.java中的hashMap允许key为null的原因,https://blog.csdn.net/weixin_46984636/article/details/120606095
以上是关于HashMap底层的实现原理的主要内容,如果未能解决你的问题,请参考以下文章