Hadoop-2.2.0 (传 hadoop-2.2.0.tar.gz)
Posted wq3435
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop-2.2.0 (传 hadoop-2.2.0.tar.gz)相关的知识,希望对你有一定的参考价值。
配置hadoop
2.1 上传hadoop包
2.2 解压hadoop包
首先在根目录下创建一个cloud目录
mkdir /cloud
tar -zxvf hadoop-2.2.0.tar.gz -C /cloud/
tar: 打包和解包
-z:用来处理gz格式
x:代表释放 c:代表创建
v:显示解压过程详情
f:file
-c:把文件解压到什么地方
2.3 配置hadoop伪分布式(要修改5个配置文件)
/cloud/hadoop-2.2.0/etc/hadoop
修改配置文件
第一个:hadoop-env.sh hadoop依赖jdk
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_60
在底行模式可以执行,查看java_home
:echo ${JAVA_HOME}
第二个:core-site.xml
vim core-site.xml
<configuration>
<!-- 用来指定HDFS的老大(NameNode的地址) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cloud01:9000</value>(这里写主机名,经过host文件配置过,也可以写ip地址)
</property>
<!-- 用来指定Hadoop运行时产生文件的存放目录,配置linux上某个具体的目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/cloud/hadoop-2.2.0/tmp</value>
</property>
</configuration>
第三个:hdfs-site.xml
<configuration>
<!-- 指定HDFS保存数据副本的数量 ,如果不配置默认副本数为3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
第四个:mapred-site.xml
目录下没有mapred-site.xml,只有mapred-site.xml.template
需要改名
mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 告诉hadoop以后MR运行在YARN上 YARN是一个资源调度系统,
不仅仅可以运行MapReduce,还可以运行Storm,Spark等计算框架 -->
<property>
<name>mapreduce.frameword,name</name>
<value>yarn</value>
</property>
</configuration>
第五个:yarn-site.xml
vim yarn-site.xml
<configuration>
<!-- NodeManager 获取数据的方式是 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的老大(ResourceManager) 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>cloud01</value>
</property>
</configuration>
2.4 将hadoop的bin 添加到环境变量中,
可以再任何目录下都可以运行
vim etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_60
export HADOOP_HOME=/cloud/hadoop-2.2.0/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
#刷新配置
source etc/profile
.配置免密码登录
免密码登录可以在任意一台机器上输入命令,可以启动所有机器上的进程
如果不做免密码登录,需要在每一台机器上输入启动进程命令
配置201上的免密码登录
在201上生成秘钥
ssh-keygen -t dsa -P \'\' -f ~/.ssh/id_dsa
在.ssh目录下生成
[root@bogon .ssh]# ls authorized_keys id_dsa id_dsa.pub known_hosts [root@bogon .ssh]#
id_dsa 为私钥,id_dsa.pub为公钥
配置单台机器的免密码登录
执行下列命令
$ ssh-keygen -t dsa -P \'\' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
配置跨节点的免密码登录
先执行
$ ssh-keygen -t dsa -P \'\' -f ~/.ssh/id_dsa
生成id_dsa.pub公钥
将id_dsa.pub拷贝到将要免密码登录的那台机器上
scp id_dsa.pub root@192.168.1.202:~
在 192.168.1.202 上将id_dsa.pub追加到 authorized_keys 日子文件上
$ cat ~/id_dsa.pub >> ~/.ssh/authorized_keys
使用 more authorized_keys 查看
在201上使用 ssh 192.168.1.202:22 登录到202上
需要先做本地免密码登录,然后做跨节点免密码登录
配置结果为 201-->202,201-->203, 如果需要相反,则主要重复上边相反过程
2.5 初始化文件HDFS(格式化文件系统)
#hadoop namenode -format(过时了,但还可以用)
#格式化只需要一次
[root@cloud01 bin]# hdfs namenode -format
#格式化后会产生tmp目录
2.6 启动HDFS和YARN
cd /sbin
./start-all.sh(过时了 This script is Deprecated. Instead use start-dfs.sh
and start-yarn.sh)
#有个小问题(需要多次输密码)
可以通过 jps 的方式验证(jps是java 的命令,在bin下)
还可以通过浏览器的方式验证
http://192.168.1.201:50070/ (hdfs管理界面)
http://192.168.1.201:8088/ (yarn管理界面)
Live Nodes : 代表DataNode存活的节点
Browse th filesystem: 浏览文件系统
使用主机名 需要在windows上 配置映射关系
c:/windows/system32/dirvers/etc/host
2.7 测试HDFS
jps
NameNode: HDFS的老大,HA(High Ability,高可靠性)集群中NameNode是多个
DataNode:HDFS的小弟
SecondaryNameNode:NameNode的助理,完成数据的同步,但是不是实时的
ResourceManager:YARN的老大,负责资源的调度
NodeManager:YARN的小弟,负责干活
文件的上传
上传Linux上的文件到HDFS上
hadoop fs -put /root/jdk-7u60-linux-i586.gz hdfs://cloud01:9000/jdk
上传成功后可以再http://192.168.1.201:50070/ (hdfs管理界面)查看
文件的下载
从 HDFS 下载文件到本地
hadoop fs -get hdfs://cloud01:9000/jdk /home/jdk1.7
2.8 测试 MR 和 YARN
HDFS块的大小
Hadoop 1.0 块的大小默认 64M 67108864字节
Hadoop 2.0 块的默认大小 128M 134217728字节
问什么要进行分块存储?
方便存储,MapReduce方便读取
HDFS 的shell
-count 统计文件的个数
hadoop fs -count /
输出文件夹个数 文件个数 大小
hadoop fs -ls -R -h /
-R代表递归查看,-h (humanRead)人类可读 将字节变成带单位的 M 或 K 等
hadoop fs -mkdir /cloud 创建目录
HDFS的文件模仿Linux上
hadoop fs -ls /
-rw-r--r-- 1 root supergroup 39343 2014-06-18 10:33 /in.log
drwxr-xr-x - root supergroup 0 2014-06-18 10:44 /itcast0106
drwxr-xr-x-
(第1位:类型;3位:所属用户权限;3位:所属组权限;3位:其他用户权限)
- 如果是文件夹表示并不存储
1 如果是文件表示文件的副本个数
root 所属用户
supergroup 所属组
39343 大小
最后修改时间
目录/文件名
hadoop fs -rm 可以删除文件,不能删除 目录
hadoop fs -rm -r 可以删除目录
递归的去掉执行权限
hadoop fs -chmod -R -x /wcout (-R 表示递归 x表示执行权限)
hadoop fs -chown supergroup /in.log 修改所属用户
hadoop fs -chgrp root /in.log 修改所属组
一次指令同时修改
hadoop fs -chown supergroup:root /wcout
如果需要递归修改,需要添加 -R
hadoop 2.0
hdfs dfs -ls /
HDFFS架构
元数据存储细节
(内存一份,磁盘一份)
NameNode(FileName,replicas,block-ids,id2host...)
文件 副本数 数据块 每块所在的机器上
test/a.log, 3, {blk_1, blk_2}, [{blk_1: [h0,h1,h3]},{blk_2:[h0,h2,h4]}]
每个文件都有一个校验值,在读取时如果校验值发生变化,说明文件损坏
这里使用CRC32校验算法
NameNode
hdfs-site.xml 的 dfs.name.dir 属性
是整个文件系统的管理节点。维护整个文件系统的文件目录树,文件/目录的
元数据信息和每个文件对应的数据块列表。接收用户的请求操作。
文件包括:
① fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息,保存在磁盘中。
(内存当中MateDate的镜像文件,内存的东西序列化到磁盘中)
② edits:操作日志文件。
(用来记录操作日志的信息)
③ fstime:保存最近一次checkpoint(还原点)的时间
(checkpoint是保存最近一次做还原点的信息)
以上这些文件是保存在linux的文件系统中。
NameNode 始终在内存中保存metedata,用于处理“读请求”
到有“写请求” 到来时,nameNode会首先写editlog到磁盘,即向edits文件中写日志,
成功返回后,才会修改内存,并且向客户端返回
Hadoop会维护一个 fsimage 文件,也就是nameNode中metedata的镜像,但是fsimage不会随时与namenode
内存中的metedata保存一致,而是每隔一段时间通过合并edits文件来更新内容(Hadoop 1.0 与 2.0的伪分布式,)
hadoop2.0会实时进行合并).
SecondaryNameNode就是用来合并fsimage和edits文件来更新NameNode的metedata的(用新的替换旧的).
SecondaryNameNode
HA的一个解决方案.但不支持热备.配置即可。
执行过程:
从NameNode 上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage
默认安装在NameNode 节点上,但这样...不安全
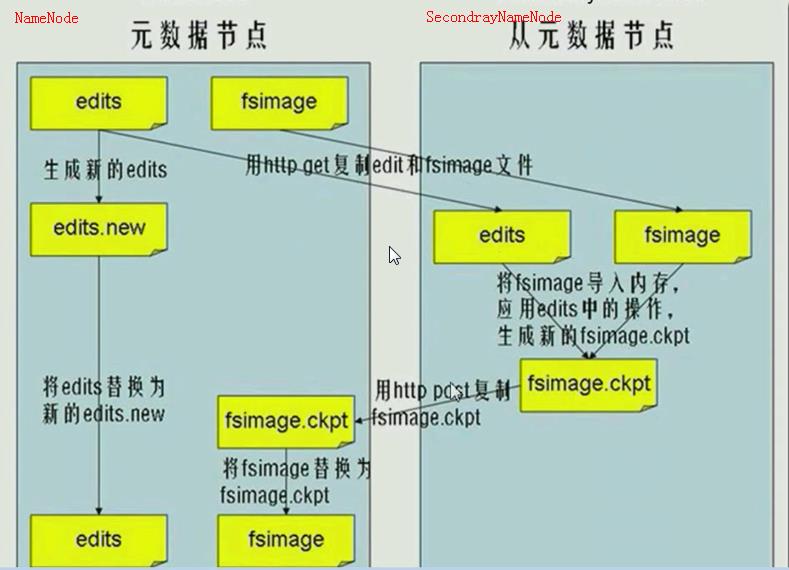
注:
在合并的过程中如果有新的client操作,则产生新的edits.new文件,不在使用之前的edits文件
合并的触发条件(什么时候checkpoint):
fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒
fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否达到最大时间间隔。默认大小是64M。
以上是关于Hadoop-2.2.0 (传 hadoop-2.2.0.tar.gz)的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop-2.2.0中文文档—— 从Hadoop 1.x 迁移至 Hadoop 2.x