项目:文件的压缩与解压
Posted 岩枭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目:文件的压缩与解压相关的知识,希望对你有一定的参考价值。
文件压缩
开发平台:Visual Studio 2015
开发技术:堆排序,哈夫曼树
项目描述:
1.统计文件中字符出现的次数,利用数据结构中的堆建造Huffman树,字符出现次数多的编码短,出现次数少的编码长;
2.根据建造好的Huffman树形成编码,以对文件进行压缩;
3.将文件中出现的字符以及他们出现的次数写入配置文件,以便后续的解压缩;
4.根据配置文件读取相关信息,重建Huffman树,对压缩后的文件进行译码。
先看如下两张图,了解一点背景知识:

图一

图二
哈弗曼树的原理:
如果有一些结点的权值分别是1,2,3,4,5,6 ,构建出来的哈弗曼树,如下图:

思想:每次从数组中取两个当前权值最小的数去创建结点,并作为叶子结点,它们的根节点的权值是两者之和,把它再放回数组,第一次选择1,2;第二次选择3,3;第三次选择4,5;~~~~ ~~
文件压缩的原理:
文件压缩真正要用到的是哈夫曼编码,对于上面那棵树,它的哈弗曼编码是怎么来的呢? 根据上图,同理可得:
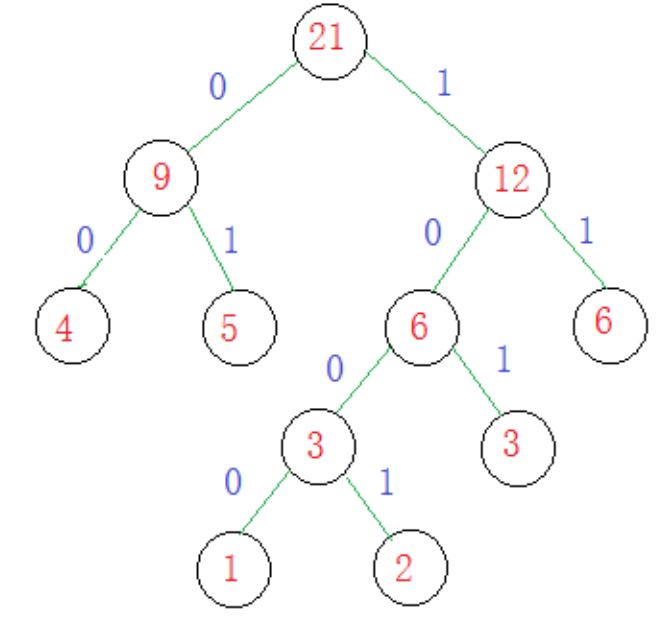
权值为1的结点的哈夫曼编码就是1000
权值为2的结点的哈夫曼编码就是1001
权值为3的结点的哈夫曼编码就是101
权值为4的结点的哈夫曼编码就是00
权值为5的结点的哈夫曼编码就是01
权值为6的结点的哈夫曼编码就是11
注意:哈夫曼编码只是对叶子节点编码
可以发现一个规律:权值越小的,它的哈夫曼编码越长,权值越大的,哈夫曼编码越短。
那么如何运用到文件压缩中呢?
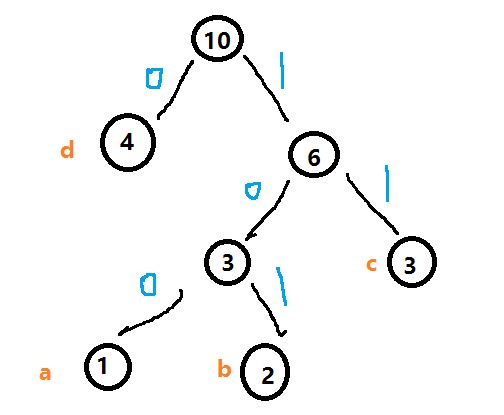
假设有一个文件的内容是“abbcccdddd“,‘a’出现的次数是1,‘b’出现的次数是2,‘c’出现的次数是3,‘d’出现的次数是4,以各字符出现的次数构建一个哈夫曼树,并为各字符编码,结果是:
‘a’:100; ‘b’:101; ‘c’:11; ‘d’:0;
如下图:
以编码的形式按照原字符的顺序写入压缩文件,如下:
1001011011111110000
这里0或1代表一个二进制位,那压缩文件是多大呢?压缩文件一共19个bit位,不够的位补齐,只占3个字节 ;
原文件是多大呢?原字符串“abbcccdddd“有10个字符,占10个字节;这就是文件压缩的原理。
项目主要思路:
1.统计:首先读取一个文件,统计出256个字符中各个字符出现的次数以及字符出现的总数;
2.建树:按照字符出现的次数,并以次数作为权值建立哈夫曼编码树,建好树后找出各个字符的编码;
3.压缩:再次读取文件,按照该字符对应的编码压缩文件;
4.加工:将文件的长度,文件中各个字符以及它们出现的次数,写进配置文件中;
5.解压:利用压缩文件和配置文件恢复出原文件;
6.测试:首先观察解压的文件和原文件是否相同,再通过Beyond Compare 4软件进行对比,验证程序的正确性。
文件压缩的过程:
首先要统计待压缩文件中各字符出现的次数,然后构造哈弗曼编码,把编码写入压缩文件,不够一个字节的就在后面补零,因为要解压缩,所以还得写一个配置文件,配置文件里面写每个字符出现的次数。
具体过程:
a.读取文件,将每个字符,该字符出现的次数和权值构成哈夫曼树;
b.哈夫曼树是利用小堆构成,字符出现次数少的节点指针存在堆顶,出现次数多的在堆底;
c.每次取堆顶的两个数,再将两个数相加进堆,直到堆被取完,这时哈夫曼树也建成;
d.从哈夫曼树中获取哈夫曼编码,然后再根据整个字符数组,来获取出现了的字符的编码;
e.获取编码后每次凑满8位就将编码串写入到压缩文件;
f.写好配置文件,统计每个字符及其出现次数,保存到配置文件中。
文件解压的过程:
先去读配置文件,构建哈弗曼树和哈弗曼编码,用压缩文件里的编码去哈弗曼树里面找,找到叶子结点,就把叶子节点的字符写入解压缩文件中。
具体过程:
a.读取配置文件,统计所有字符的个数;
b.构建哈夫曼树,读解压缩文件,将所读到的编码字符的这个节点所含的字符,写入到解压缩文件中,直到将压缩文件读完;
c.解压缩完成之后,利用Beyond Compare 4软件,进行文件的测试。
项目测试:
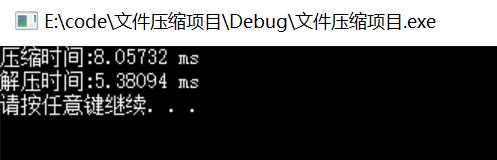
通过Beyond Compare 4软件,对文件压缩前和压缩后的内容进行对比,验证程序的正确性。 性能测试,在release版本下会更高效一些,时间会缩短很多,因为 Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序,也就是博主编程用的版本;Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用。
完整项目代码链接:https://github.com/yaoyaoyanxiao/wenjianyasuo
运行结果:
测试用例:
原文件为“穿过落雁修竹,看过月升日落 你说总有一日会名扬天下实现你抱负”(名为1.txt),经过压缩(1.huff),解压后(1_Com.txt)的文件的内容如下:
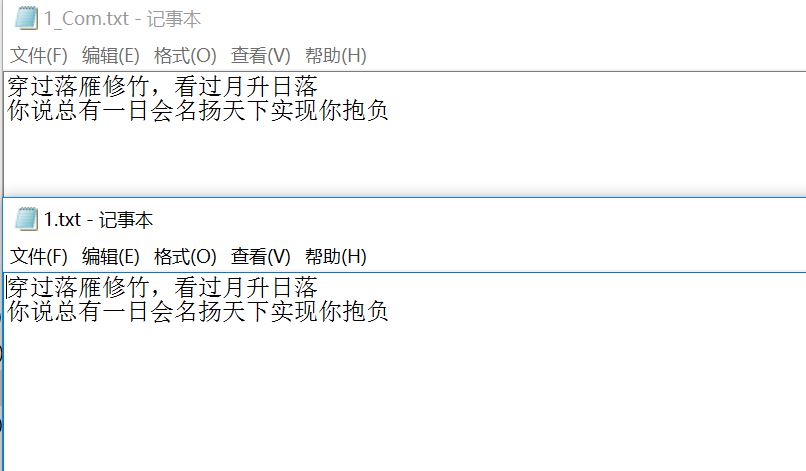
图三

图四
项目中出现的问题:
(1)测试的时候发现如果待压缩文件中出现中文,程序就会崩溃,将错误定位到构造哈弗曼编码的函数处,通过单步调试发现是数组越界所致,因为如果只是字符,它的范围是-128~127,程序中通过一个char类型的变量作为数组的下标(0~127),是没有问题的,但汉字的编码是两个字节(只能收录2万多的汉字,但在本项目中已经够用了,这里不进行深究),所以会发生数组越界,解决方法是将char强转为unsigned char,可表示范围为0~255。
(2)为什么要使用配置文件?
在项目中,将字符对应的编码转化为位,在unsigned char中填充位,填满后就写入到压缩文件中。
问题1:最后一个字节是不是很有可能没有填满,该如何判断他是否填满以及填了几个字符的编码?
问题2:若依次压缩一些文件,压缩完后再去解压,那么编码此时已经没有了,该如何解压?
上面的两个问题可通过配置文件解决,假如要压缩的文件叫xxx,那么可生成一个xxx.config的配置文件,在该配置文件中写入<文件的总长度>(恢复时知道应该恢复多少个字符),<char-times>(字符以及其出现的次数,用于解压时重建哈夫曼树),利用该配置文件即可解决这两个问题。
(3)在文件恢复的时候需要注意哪些问题?
有些特殊字符的处理需要注意一下,比如 '\\n',我的程序中有一个函数就是读取一行字符,但是若是该字符本身就是'\\n'呢,我们写入的<char-times>的char就是\\n呢?那么就比较棘手了,对于这个问题,千万不能漏掉,否则就不能恢复出原来的文件。读取配置文件的时候若读到’\\n‘,则说明该字符就是'\\n',应该继续读取它的次数。
有问题可微信扫码咨询:

以上是关于项目:文件的压缩与解压的主要内容,如果未能解决你的问题,请参考以下文章