HadoopHadoop MR 自定义分组 Partition机制
Posted junneyang 的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HadoopHadoop MR 自定义分组 Partition机制相关的知识,希望对你有一定的参考价值。
1、概念
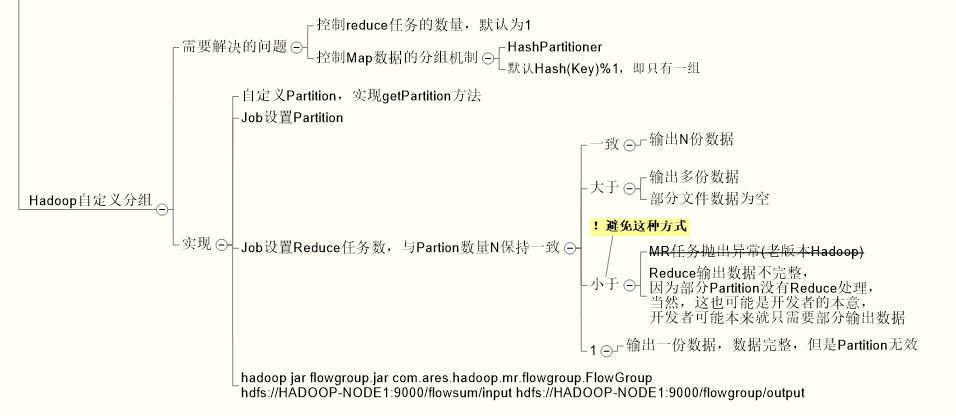
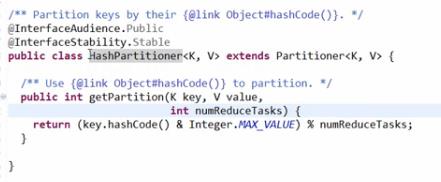
2、Hadoop默认分组机制--所有的Key分到一个组,一个Reduce任务处理
3、代码示例
FlowBean
package com.ares.hadoop.mr.flowgroup; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class FlowBean implements WritableComparable<FlowBean>{ private String phoneNum; private long upFlow; private long downFlow; private long sumFlow; public FlowBean() { // TODO Auto-generated constructor stub } // public FlowBean(String phoneNum, long upFlow, long downFlow, long sumFlow) { // super(); // this.phoneNum = phoneNum; // this.upFlow = upFlow; // this.downFlow = downFlow; // this.sumFlow = sumFlow; // } public String getPhoneNum() { return phoneNum; } public void setPhoneNum(String phoneNum) { this.phoneNum = phoneNum; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } @Override public void readFields(DataInput in) throws IOException { // TODO Auto-generated method stub phoneNum = in.readUTF(); upFlow = in.readLong(); downFlow = in.readLong(); sumFlow = in.readLong(); } @Override public void write(DataOutput out) throws IOException { // TODO Auto-generated method stub out.writeUTF(phoneNum); out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } @Override public String toString() { return "" + phoneNum + "\\t" + upFlow + "\\t" + downFlow + "\\t" + sumFlow; } @Override public int compareTo(FlowBean o) { // TODO Auto-generated method stub return sumFlow>o.getSumFlow()?-1:1; } }
FlowGroup
package com.ares.hadoop.mr.flowgroup; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.StringUtils; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import org.apache.log4j.Logger; import com.ares.hadoop.mr.exception.LineException; import com.ares.hadoop.mr.flowgroup.FlowBean;; public class FlowGroup extends Configured implements Tool { private static final Logger LOGGER = Logger.getLogger(FlowGroup.class); enum Counter { LINESKIP } public static class FlowGroupMapper extends Mapper<LongWritable, Text, Text, FlowBean> { private String line; private int length; private final static char separator = \'\\t\'; private String phoneNum; private long upFlow; private long downFlow; //private long sumFlow; private Text text = new Text(); private FlowBean flowBean = new FlowBean(); @Override protected void map( LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub //super.map(key, value, context); String errMsg; try { line = value.toString(); String[] fields = StringUtils.split(line, separator); length = fields.length; if (length != 11) { throw new LineException(key.get() + ", " + line + " LENGTH INVALID, IGNORE..."); } phoneNum = fields[1]; upFlow = Long.parseLong(fields[length-3]); downFlow = Long.parseLong(fields[length-2]); //sumFlow = upFlow + downFlow; text.set(phoneNum); flowBean.setPhoneNum(phoneNum); flowBean.setUpFlow(upFlow); flowBean.setDownFlow(downFlow); //flowBean.setSumFlow(sumFlow); context.write(text, flowBean); } catch (LineException e) { // TODO: handle exception LOGGER.error(e); System.out.println(e); context.getCounter(Counter.LINESKIP).increment(1); return; } catch (NumberFormatException e) { // TODO: handle exception errMsg = key.get() + ", " + line + " FLOW DATA INVALID, IGNORE..."; LOGGER.error(errMsg); System.out.println(errMsg); context.getCounter(Counter.LINESKIP).increment(1); return; } catch (Exception e) { // TODO: handle exception LOGGER.error(e); System.out.println(e); context.getCounter(Counter.LINESKIP).increment(1); return; } } } public static class FlowGroupReducer extends Reducer<Text, FlowBean, FlowBean, NullWritable> { private FlowBean flowBean = new FlowBean(); @Override protected void reduce( Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, FlowBean, NullWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub //super.reduce(arg0, arg1, arg2); long upFlowCounter = 0; long downFlowCounter = 0; for (FlowBean flowBean : values) { upFlowCounter += flowBean.getUpFlow(); downFlowCounter += flowBean.getDownFlow(); } flowBean.setPhoneNum(key.toString()); flowBean.setUpFlow(upFlowCounter); flowBean.setDownFlow(downFlowCounter); flowBean.setSumFlow(upFlowCounter + downFlowCounter); context.write(flowBean, NullWritable.get()); } } @Override public int run(String[] args) throws Exception { // TODO Auto-generated method stub String errMsg = "FlowGroup: TEST STARTED..."; LOGGER.debug(errMsg); System.out.println(errMsg); Configuration conf = new Configuration(); //FOR Eclipse JVM Debug //conf.set("mapreduce.job.jar", "flowsum.jar"); Job job = Job.getInstance(conf); // JOB NAME job.setJobName("FlowGroup"); // JOB MAPPER & REDUCER job.setJarByClass(FlowGroup.class); job.setMapperClass(FlowGroupMapper.class); job.setReducerClass(FlowGroupReducer.class); // JOB PARTITION job.setPartitionerClass(FlowGroupPartition.class); // JOB REDUCE TASK NUMBER job.setNumReduceTasks(5); // MAP & REDUCE job.setOutputKeyClass(FlowBean.class); job.setOutputValueClass(NullWritable.class); // MAP job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // JOB INPUT & OUTPUT PATH //FileInputFormat.addInputPath(job, new Path(args[0])); FileInputFormat.setInputPaths(job, args[1]); FileOutputFormat.setOutputPath(job, new Path(args[2])); // VERBOSE OUTPUT if (job.waitForCompletion(true)) { errMsg = "FlowGroup: TEST SUCCESSFULLY..."; LOGGER.debug(errMsg); System.out.println(errMsg); return 0; } else { errMsg = "FlowGroup: TEST FAILED..."; LOGGER.debug(errMsg); System.out.println(errMsg); return 1; } } public static void main(String[] args) throws Exception { if (args.length != 3) { String errMsg = "FlowGroup: ARGUMENTS ERROR"; LOGGER.error(errMsg); System.out.println(errMsg); System.exit(-1); } int result = ToolRunner.run(new Configuration(), new FlowGroup(), args); System.exit(result); } }
FlowGroupPartition
package com.ares.hadoop.mr.flowgroup; import java.util.HashMap; import org.apache.hadoop.mapreduce.Partitioner; public class FlowGroupPartition<KEY, VALUE> extends Partitioner<KEY, VALUE>{ private static HashMap<String, Integer> groupMap = new HashMap<String, Integer>(); static { groupMap.put("135", 0); groupMap.put("136", 1); groupMap.put("137", 2); groupMap.put("138", 3); } @Override public int getPartition(KEY key, VALUE value, int numPartitions) { // TODO Auto-generated method stub return (groupMap.get(key.toString().substring(0, 3)) == null)?4: groupMap.get(key.toString().substring(0, 3)); } }
以上是关于HadoopHadoop MR 自定义分组 Partition机制的主要内容,如果未能解决你的问题,请参考以下文章
HadoopHadoop MR 性能优化 Combiner机制
hadoophadoop 报错 Operation category READ is not supported in state standby