mybatis学习第天
Posted guoDaXia的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mybatis学习第天相关的知识,希望对你有一定的参考价值。
Mybatis第二天 高级映射 查询缓存
关于与spring的整合和反转工程我偷懒了,下次看。
使用的sql:


CREATE TABLE USER( id INT PRIMARY KEY AUTO_INCREMENT, username VARCHAR(32) NOT NULL, -- 用户名称 birthday DATE, -- 生日 sex CHAR(1), -- 性别:1表示男,2表示女 address VARCHAR(256) -- 地址 ); CREATE TABLE orders( id INT PRIMARY KEY AUTO_INCREMENT, user_id INT NOT NULL, -- 下单用户id number VARCHAR(32) NOT NULL, -- 订单号 createtime DATETIME NOT NULL, -- 创建订单时间 note VARCHAR(100) -- 备注 ); CREATE TABLE orderdetail( id INT PRIMARY KEY AUTO_INCREMENT, orders_id INT NOT NULL, -- 订单id items_id INT NOT NULL, -- 商品id item_nu INT -- 商品购买数量 ); CREATE TABLE items( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(32) NOT NULL, -- 商品名称 price FLOAT(10,1) NOT NULL, -- 商品定价 detail TEXT, -- 商品描述 pic VARCHAR(512), -- 商品图片 createtime DATETIME -- 生产日期 ); ALTER TABLE orders ADD CONSTRAINT pk_orders_user_id FOREIGN KEY (user_id) REFERENCES USER(id); ALTER TABLE orderdetail ADD CONSTRAINT pk_orderdetail_orders_id FOREIGN KEY (orders_id) REFERENCES orders(id); ALTER TABLE orderdetail ADD CONSTRAINT pk_orderdetail_items_id FOREIGN KEY (items_id) REFERENCES items(id);
INSERT INTO USER VALUES(NULL,\'宋江\',\'2011-10-8\',\'1\',\'梁山泊\'); INSERT INTO USER VALUES(NULL,\'李逵\',\'2013-1-8\',\'1\',\'梁山泊\'); INSERT INTO USER VALUES(NULL,\'扈三娘\',\'2008-10-7\',\'2\',\'祝家庄\'); INSERT INTO USER VALUES(NULL,\'李青\',\'2011-8-2\',\'1\',\'万安寺\'); INSERT INTO USER VALUES(NULL,\'貂蝉\',\'2013-10-9\',\'2\',\'公主府\'); INSERT INTO USER VALUES(NULL,\'西施\',\'2001-11-8\',\'2\',\'女儿国\'); INSERT INTO USER VALUES(NULL,\'张三\',\'2011-10-8\',\'1\',\'清风寨\'); INSERT INTO USER VALUES(NULL,\'李四\',\'2011-10-8\',\'1\',\'清风寨\'); INSERT INTO USER VALUES(NULL,\'王五\',\'2011-10-8\',\'1\',\'清风寨\'); INSERT INTO USER VALUES(NULL,\'赵六\',\'2011-10-8\',\'1\',\'清风寨\'); INSERT INTO items VALUES(NULL,\'胡萝卜\',25.3,\'兔子很喜欢吃\',NULL,NULL); INSERT INTO items VALUES(NULL,\'香菇\',40,\'干货\',NULL,NULL); INSERT INTO items VALUES(NULL,\'银耳\',45,\'美味营养\',NULL,NULL); INSERT INTO items VALUES(NULL,\'莲子\',52,\'补血\',NULL,NULL); INSERT INTO items VALUES(NULL,\'当归\',200,\'良人当归即好\',NULL,NULL); INSERT INTO items VALUES(NULL,\'葡萄\',10.5,\'紫葡萄\',NULL,NULL); INSERT INTO items VALUES(NULL,\'香蕉\',6.5,\'不要想歪了啊\',NULL,NULL); INSERT INTO items VALUES(NULL,\'西瓜\',3,\'凉爽解渴\',NULL,NULL); INSERT INTO orders VALUES(NULL,1,UUID(),\'2016-08-21\',NULL); INSERT INTO orders VALUES(NULL,1,UUID(),\'2016-08-21\',NULL); INSERT INTO orders VALUES(NULL,10,UUID(),\'2016-08-25\',NULL); INSERT INTO orders VALUES(NULL,10,UUID(),\'2016-08-25\',NULL); INSERT INTO orders VALUES(NULL,2,UUID(),\'2016-08-27\',NULL); INSERT INTO orders VALUES(NULL,2,UUID(),\'2016-08-27\',NULL); INSERT INTO orders VALUES(NULL,4,UUID(),\'2016-08-30\',NULL); INSERT INTO orders VALUES(NULL,4,UUID(),\'2016-08-30\',NULL); INSERT INTO orderdetail VALUES(NULL,10000,1,3); INSERT INTO orderdetail VALUES(NULL,10000,2,3); INSERT INTO orderdetail VALUES(NULL,10002,3,1); INSERT INTO orderdetail VALUES(NULL,10002,8,2); INSERT INTO orderdetail VALUES(NULL,10004,1,3); INSERT INTO orderdetail VALUES(NULL,10002,2,3); INSERT INTO orderdetail VALUES(NULL,10005,6,2); INSERT INTO orderdetail VALUES(NULL,10003,2,3); INSERT INTO orderdetail VALUES(NULL,10005,1,1); INSERT INTO orderdetail VALUES(NULL,10007,2,3);
课程复习:
Mybatis是什么?
Mybatis是一个持久层框架,mybatis是一个不完全的orm框架,sql语句需要自己编写,但是mybatis也有映射(输入映射和输出映射)
Mybatis入门门槛不高,学习成本低,让程序员把精力放在sql语句上,对sql语句优化非常方便,适用于需求变化较大的项目,比如:互联网项目
Mybatis的执行过程:
1、 首先配置mybatis配置文件,SqlMapConfig(名称不固定)
2、 通过配置文件,加载mybatis运行环境,创建SqlSessionFactory会话工厂,SqlSessionFactory用单例管理
3、 通过SqlSessionFactory创建SqlSession
SqlSession是一个面向用户接口(提供操作数据库方法),SqlSession是线程不安全的,建议sqlSession应用场合在方法体内。
4、 调用sqlSession的方法去操作数据库。如果需要提交事务,执行sqlSession的commit()方法
5、 释放资源,关闭sqlSession
Mybatis开发dao的方法:
1、 原始dao的方法
a) 需要程序员编写dao接口和实现类
b) 需要在dao的实现类中注入sqlSessionFactory工厂
2、 Mapper代理开发方法(建议使用)
a) 只需要程序员编写mapper接口(就是dao接口)
b) 程序员在编写mapper.xml和mapper.java需要遵循一个开发原则
i. 在mapper.xml中的namespace就是mapper.java的类的全路径
ii. Mapper.xml中的statement的id对应mapper.java 中的方法名
iii. Mapper.xml中的statement的输入参数类型parameterType指定的输入参数类型和mapper.java 中方法的输入参数一致
iv. Mapper.xml中的statement中的resultType输出结果类型和mapper.java方法的返回值一致
SqlMapConfig配置文件:properties属性,别名,mapper加载…
输入映射:
parameterType:输入参数乐意是简单类型,pojo,hashmap…
对于综合查询,使用包装的pojo更易于系统可维护性
输出映射:
resultType:
查询到的列名和resultType的属性名一致才能映射成功,如果不完全一致,可以生成元素,但是不一致的一列为null,如果全部不一致,返回null
resultMap:
通过resultMap完成一些高级映射。
如果查询到的列名和最终要映射的属性名不一致的时候,我们可以通过resultMap设置列名和属性名之间的对应关系,这样就可以完成映射。
高级映射:
将关联查询的列映射到一个pojo属性中
将关联查询的列映射到一个List<pojo>中
动态sql:
Where、If、Choose、set、forEach
Sql片段
课程安排:
对订单数据模型进行分析
高级映射:
实现一对一查询、一对多、多对多查询
延迟加载
查询缓存
一级缓存
二级缓存(了解mybatis二级缓存使用场景)
1、订单商品数据模型
1、数据模型分析思路
1、 每张表所记录的数据的内容
分模块对每张表所记录的内容进行熟悉 相当于学习你系统需求的过程
2、 每张表(重要的,非空字段绝对重要,有外键的字段)数据库字段的设置
3、 数据库级别表与表之间的关系
外键关系
4、 表与表之间的业务关系
数据模型分析
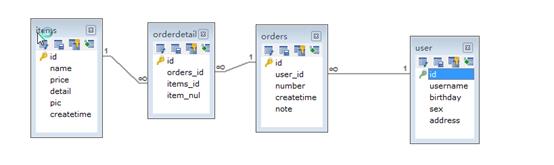
用户表user:
记录了购买商品的用户信息
订单表:orders
记录了用户所创建的订单(购买商品的订单)
订单明细表:ordersdetail
记录了订单的详细信息即购买商品的信息
商品表:items
记录了商品信息
表与表之间的业务关系:
在分析表鱼鳔之间的业务关系时需要建立在某个业务意义基础上去分析。
先分析数据级别有关系的表的业务关系。
User和orders
Useràorders:一个用户可以创建多个订单,一对多
Orders—>users:一个订单只由一个用户创建,一对一
Orders和orderdetail:
Orders—>orderdetail:一个订单可以包括多个订单明细,因为一个订单可以购买多个商品,每个商品的购买讯息在ordertail中记录,一对多关系
Orderdetail—>orders:一个明细只能在一个订单中,一对一
Orderdetail和items:
Orderdetailàitems:一条明细值对应一个商品信息,一对一
Itemsàorderdetail:一个商品可以包括在多个订单明细中,一对多
再分析数据库级别没有关系的表之间有没有业务关系
Orders和items:
Orders和items之间可以通过orderdetail建立关系
2、一对一查询
1、需求
查询订单信息,关联查询创建订单的用户信息
2、resultType
a) sql语句
i. 确定主表:订单表
ii. 确定关联表:用户表
- 关联查询使用内连接还是外连接
- 由于在orders表中有一个外键,并且是user_id.我们通过外键查询用户只能查询出一条记录,所以我们大胆使用内连接
SELECT orders.*,
user.username,
user.sex,
user.address
FROM orders,USER WHERE orders.user_id=user.id
b) Pojo
i. 将上面查询的所有结果集映射到pojo中。我们知道我们的Orders类无法装载我们查询的所有信息。所以我们需要映射的pojo可以是orders的增强类:
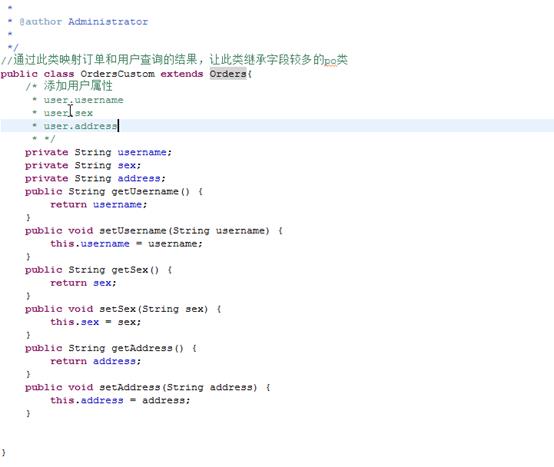
Mapper.xml
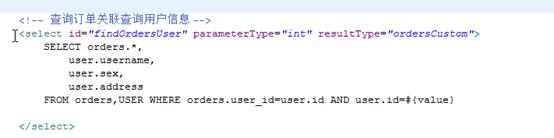
Mapper.java
测试代码:
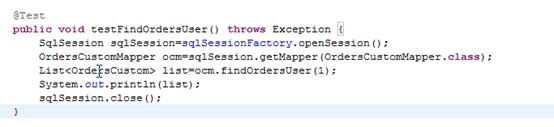
3、 resultMap
sql语句:
和前面的相同
使用resultMap的思路:
将结果中的订单信息映射到orders这个对象中,所以需要在orders这个类中添加User属性,将关联查询出来的用户信息映射到orders对象中的user属性中。
增强的orders类:
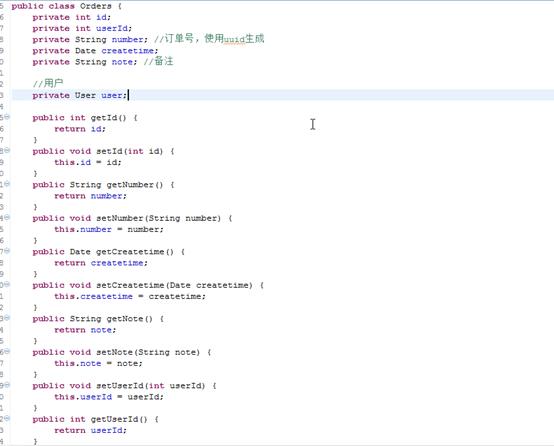
定义resultMap:
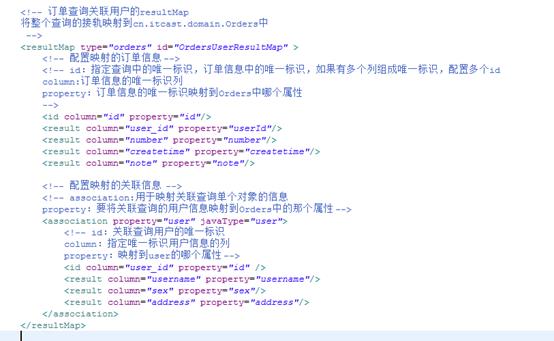
使用resultMap:

Mapper.java:

测试代码:

4、 resultType和resultMap使用小结
实现一对一查询:
resultType:列名和字段名要一一对应,使用resultType实现比较简单,如果pojo中不包括查询出来的列名,需要增加列名对应的属性,即可完成映射。
如果没有查询结果的特殊要求建议使用resultType。
resultMap:需要单独定义resultMap,实现有点麻烦,如果有对查询结果有特殊要求,使用resultMap可以完成将关联查询映射到pojo属性中
resultMap可以实现延迟加载,resultType无法实现这个效果。
3、 一对多查询
1、需求:
查询订单以及订单明细的信息
2、sql语句:
主查询表:订单表
关联查询表:订单明细表
SELECT orders.*,
orderdetail.id orderdetail_id,
orderdetail.orders_id,
orderdetail.items_id,
orderdetail.items_nu
FROM orders,orderdetail WHERE orders.id=orderdetail.orders_id;
发现我们现在需要修改orders类:
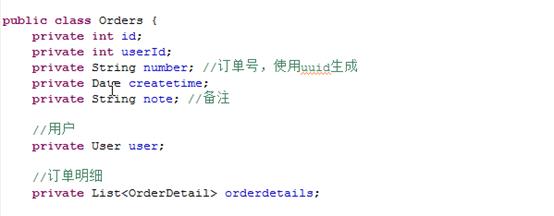
通过数据库中的查询我们可以发现得到的数据会有orders的id相同但是orderdetail不同的数据,这样的话与我们的想法不同,所以简单是用resultType无法达到效果。
Mapper.xml:


Mapper.java:

测试代码:
如果sql语句是这样的:
SELECT orders.*,
user.username,
user.sex,
user.address,
orderdetail.id orderdetail_id,
orderdetail.orders_id,
orderdetail.items_id,
orderdetail.items_nu
FROM orders,USER,orderdetail WHERE orders.user_id=user.id AND orders.id=orderdetail.orders_id;
也就是说我的sql是在原来sql上面上修改得到的,我得到订单对象的需要加载多个订单detail还需要加载对用的user。
Mapper.xml:
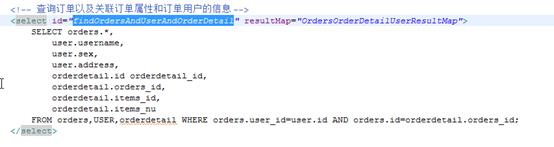
生成resultMap:(如果使用的好多键值对是前面resultMap中的,可以使用extends继承前面resultMap的属性,至于不同的可以覆盖)
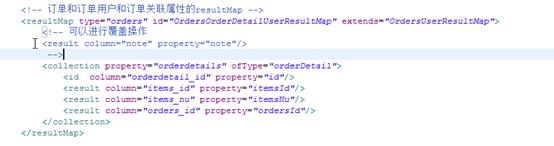
Mapper.java:

测试代码:
小结:
Mybatis使用collection对关联查询的多条记录映射到list集合的属性中
如果使用resultType,得到的结果是含重复的,所以我们需要自行处理,双重for循环进行更改
4、多对多查询
1、需求:
查询用户以及用户购买商品信息。
2、分析:
查询主表是:用户表
关联表:由于用户和商品没有直接关联,通过订单和订单明细进行关联,所以关联表:
Orders、orderdetail、items
3、sql语句
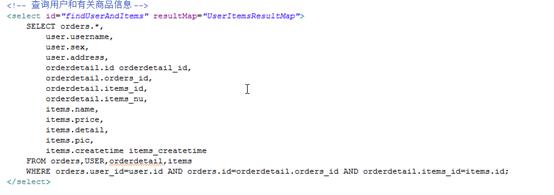
SELECT orders.*,
user.username,
user.sex,
user.address,
orderdetail.id orderdetail_id,
orderdetail.orders_id,
orderdetail.items_id,
orderdetail.items_nu,
items.id items_id,
items.name,
items.price,
items.detail,
items.pic,
items.createtime
FROM orders,USER,orderdetail,items
WHERE orders.user_id=user.id AND orders.id=orderdetail.orders_id AND orderdetail.items_id=items.id;
4、映射思路
将用户信息映射到user中。
在user类中添加订单列表属性List<Orders> orderslist;
在Orders中添加订单明细属性List<OrderDetail> orderdetails
在OrderDetail中添加属性List<Items> items
5、 Mapper.xml:

Mapper.java:

测试代码:
多对多查询总结:
多对多就是由一对一一对多等拼接起来的。(我的理解)
一对多是多对多的特例,如下需求:
查询用户购买的商品信息,用户和商品的诶关系是多对多关系。
需求1:
将查询用户购买的商品信息明细清单,(用户名、用户地址、购买商品名称,购买商品名称,购买商品数量)
针对上面的需求就是用resultType将查询到的记录映射到一个扩展的pojo中,很简单实现明细清单的功能
需求2:
查询字段:用户账号、用户姓名、购买商品数量、商品明细(鼠标移动上显示明细),使用resultMap将用户购买的商品明细列表映射到user对象中。
总结:
使用resultMap是针对那些对查询结果映射有特殊要求的功能。
5、延迟加载
1、什么是延迟加载?
resultMap可以实现高级映射(使用association、collection实现一对一、一对多的映射),association和collection具备延迟加载的功能。
需求:
要查询订单并且关联查询用户信息。如果先查询订单信息即可满足要求,当我们需要查询用户信息时再查询用户信息。对把用户信息按需查询就是延迟加载。
延迟加载:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表比查询多张表速度要快。
2、使用association实现延迟加载
需求:
查询订单并关联查询用户信息
Sql语句:
SELECT * FROM orders;
SELECT * FROM USER WHERE id=userId;
Mapper.xml:

Mapper.java:

测试思路:
1、执行上边的mapper方法(findOrdersUserLazyLoading),内部调用cn.itcast.mapper.OrdersMapperCustom中的findOrdersUserLazyLoading只查询orders信息(单表)。
2、在程序中去遍历上一步骤查询出的List<Orders>,当我们调用Orders中的getUser方法时,开始进行延迟加载
3、 延迟加载,去调用UserMapper.xml中的findUserById这个方法获取用户信息。
测试:
3、Mybatis开启延迟加载:


4、延迟加载的思考:
不使用mybatis提供的association和collection中的延迟加载功能,我们如何实现延迟加载?
实现方法如下:
定义两个mapper方法:
1、 查询订单列表
2、 根据用户id查询用户信息
实现思路:
先调用第一个方法获取订单列表,在service中,当需要用户信息的时候再调用第二个方法。
总之:
使用延迟加载方法,先查询简单的sql(最好单表,也可以关联查询),再按需求加载关联查询的其他信息。
哈哈哈!框架是方便程序,优化实现的本质也是为了达到功能实现,所以我们应该不忘初心!
6、查询缓存
1、什么是查询缓存
Mybatis提供查询缓存,用于减轻数据压力,提高数据库性能。
Mybatis提供一级缓存和二级缓存。
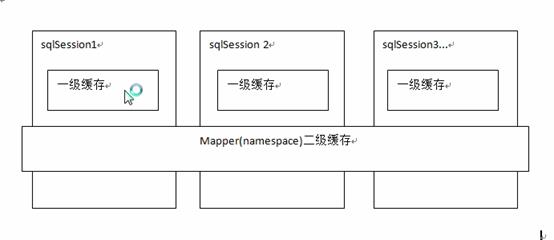
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造SqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的SqlSession之间的缓存数据区域(HashMap)是互相不影响的。
二级缓存是mapper级别的缓存,多喝SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
为什么要用缓存?
如果缓存中有数据就不用从数据库中获取,大大提高系统性能。
2、一级缓存
原理:
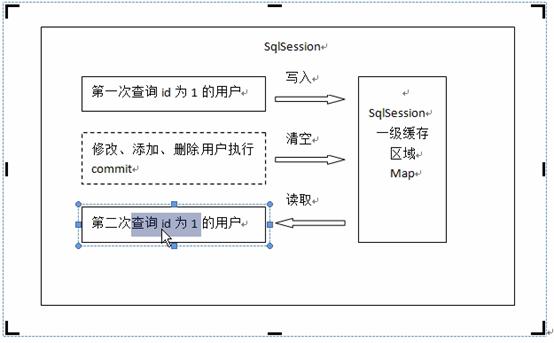
第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。
得到用户信息,将用户信息存储到一级缓存中。
如果sqlSession去执行commot操作(执行更新、删除、插入操作),清空SqlSession中的一级缓存,这样做的目的是让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户id为1的用户信息,先去缓存中查找是否有id为1的用户信息,缓存中有的话直接从缓存中湖区用户信息。
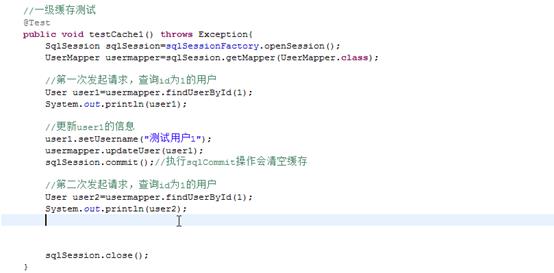
3、一级缓存测试
Mybatis默认支持一级缓存
按照上面的一级缓存的原理步骤去测试。
4、二级缓存
1、原理:
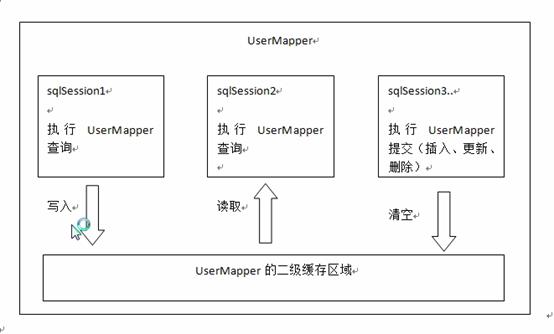
首先开启mybatis的二级缓存
sqlSession1去查询用户id为1的用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果sqlSession3去执行相同mapper下sql,执行commit提交,清空该mapper下的二级缓存区域的数据。
sqlSession2去查询用户id为1的用户信息去缓存中找是否存在数据,如果存在直接从缓存中读取数据
二级缓存与一级缓存的区别:二级缓存的范围更大,多个sqlSession可以共享一个UserMapper的二级缓存区域,UserMapper有一个二级缓存区域(按namespace分),其他mapper也有自己的二级缓存区域(按namespace分)。
每一个namespace的mapper都有一个二级缓存区域,两个mapper的namespace如果相同,那么这两个mapper执行sql查询到的数据将存在相同的mapper中。
2、开启二级缓存
Mybatis中的二级缓存是mapper范围级别,除了在SqlMapConfig.xml设置二级缓存的总开关,还有在具体的mapper.xml中开启二级缓存。
在核心配置文件SqlMapConfig.xml中加入


在UserMapper中开启二级缓存:
这样里面的sql会将信息存储到二级缓存

3、调用pojo实现序列化接口:
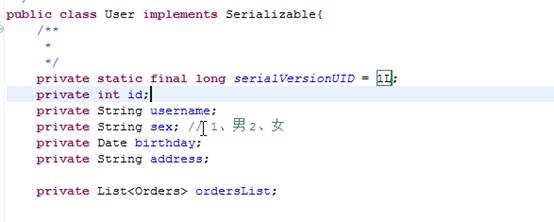
为了将缓存数据取出执行反序列化操作,因为二级缓存的存储介质多种多样,数据不一定存储在内存中。
4、二级缓存测试
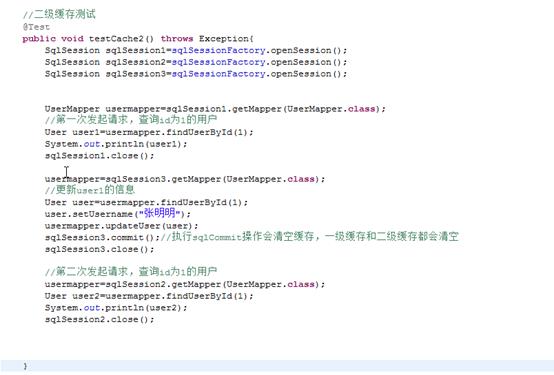
5、禁用二级缓存(useCache配置)
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql语句,默认情况下是true,即sql使用二级缓存。

6、刷新缓存(就是清空缓存)
在mapper的同一个namespace中,如果有其他insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。
设置statement配置中的flushCache=”true”属性,默认情况下为true即刷新缓存,如果改成false则不会刷新,使用缓存时如果手动修改数据库表中的数据会出现脏读。
如下:
<insert id=”insertUser” parameterType=”user” flushCache=”true”>
总结:一般执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。
5、mybatis整合ehcache
Ehcache是一个分布式缓存框架。
4.1分布缓存
我们系统为了提高系统并发性能,一般对系统进行分布式部署(集群部署方式)。
不使用分布式缓存,缓存的数据在各个服务器单独存储,不方便系统开发。所以要使用分布式缓存对缓存数据进行集中处理。
Mybatis无法实现分布式缓存,需要和其他的分布式缓存框架进行整合。
4.2、整合方法
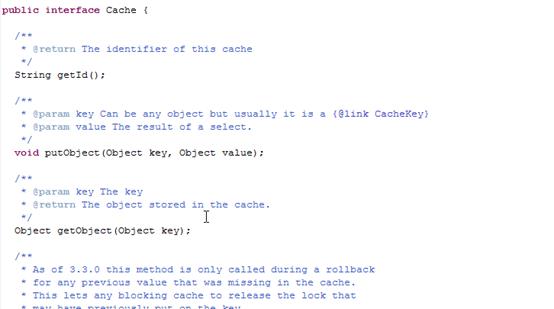
Mybatis提供了一个cache接口,如果要实现自己的缓存逻辑,实现cache接口开发即可。
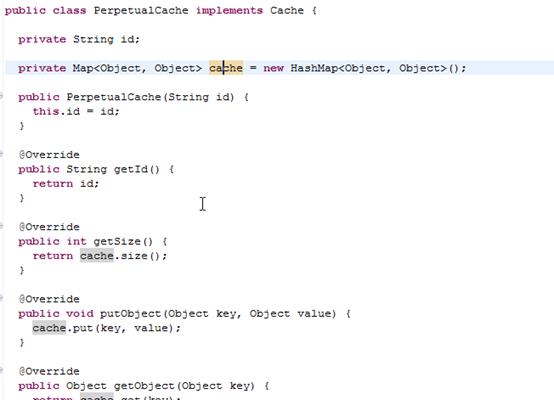
Mybatis和ehcache接口整个,mybatis和ehcache整合包中提供 了一个cache接口的实现类。
Cache接口:
Mybatis cache默认实现类:
1、 加入jar:

2、配置使用ecache

3、在classpath下加入ehcache的配置文件:ehcache.xml
mybatis学习日志二