分布式ID生成服务,真的有必要搞一个
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式ID生成服务,真的有必要搞一个相关的知识,希望对你有一定的参考价值。
目录
阐述背景
Leaf snowflake 模式介绍
Leaf segment 模式介绍
Leaf 改造支持 RPC
阐述背景
不吹嘘,不夸张,项目中用到 ID 生成的场景确实挺多。比如业务要做幂等的时候,如果没有合适的业务字段去做唯一标识,那就需要单独生成一个唯一的标识,这个场景相信大家不陌生。
很多时候为了图方便可能就是写一个简单的 ID 生成工具类,直接开用。做的好点的可能单独出一个 Jar 包让其他项目依赖,做的不好的很有可能就是 Copy 了 N 份一样的代码。
单独搞一个独立的 ID 生成服务非常有必要,当然我们也没必要自己做造轮子,有现成开源的直接用就是了。如果人手够,不差钱,自研也可以。
今天为大家介绍一款美团开源的 ID 生成框架 Leaf,在 Leaf 的基础上稍微扩展下,增加 RPC 服务的暴露和调用,提高 ID 获取的性能。
Leaf 介绍
Leaf 最早期需求是各个业务线的订单 ID 生成需求。在美团早期,有的业务直接通过 DB 自增的方式生成 ID,有的业务通过 redis 缓存来生成 ID,也有的业务直接用 UUID 这种方式来生成 ID。以上的方式各自有各自的问题,因此我们决定实现一套分布式 ID 生成服务来满足需求。
具体 Leaf 设计文档见:https://tech.meituan.com/2017/04/21/mt-leaf.html[1]
目前 Leaf 覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
snowflake 模式
snowflake 是 Twitter 开源的分布式 ID 生成算法,被广泛应用于各种生成 ID 的场景。Leaf 中也支持这种方式去生成 ID。
使用步骤如下:
修改配置 leaf.snowflake.enable=true 开启 snowflake 模式。
修改配置 leaf.snowflake.zk.address 和 leaf.snowflake.port 为你自己的 Zookeeper 地址和端口。
想必大家很好奇,为什么这里依赖了 Zookeeper 呢?
那是因为 snowflake 的 ID 组成中有 10bit 的 workerId,如下图:
snowflake组成
一般如果服务数量不多的话手动设置也没问题,还有一些框架中会采用约定基于配置的方式,比如基于 IP 生成 wokerID,基于 hostname 最后几位生成 wokerID,手动在机器上配置,手动在程序启动时传入等等方式。
Leaf 中为了简化 wokerID 的配置,所以采用了 Zookeeper 来生成 wokerID。就是用了 Zookeeper 持久顺序节点的特性自动对 snowflake 节点配置 wokerID。
如果你公司没有用 Zookeeper,又不想因为 Leaf 去单独部署 Zookeeper 的话,你可以将源码中这块的逻辑改掉,比如自己提供一个生成顺序 ID 的服务来替代 Zookeeper。
segment 模式
segment 是 Leaf 基于数据库实现的 ID 生成方案,如果调用量不大,完全可以用 mysql 的自增 ID 来实现 ID 的递增。
Leaf 虽然也是基于 Mysql,但是做了很多的优化,下面简单的介绍下 segment 模式的原理。
首先我们需要在数据库中新增一张表用于存储 ID 相关的信息。
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT ‘‘,
`max_id` bigint(20) NOT NULL DEFAULT ‘1‘,
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;biz_tag 用于区分业务类型,比如下单,支付等。如果以后有性能需求需要对数据库扩容,只需要对 biz_tag 分库分表就行。
max_id 表示该 biz_tag 目前所被分配的 ID 号段的最大值。
step 表示每次分配的号段长度。
下图是 segment 的架构图:
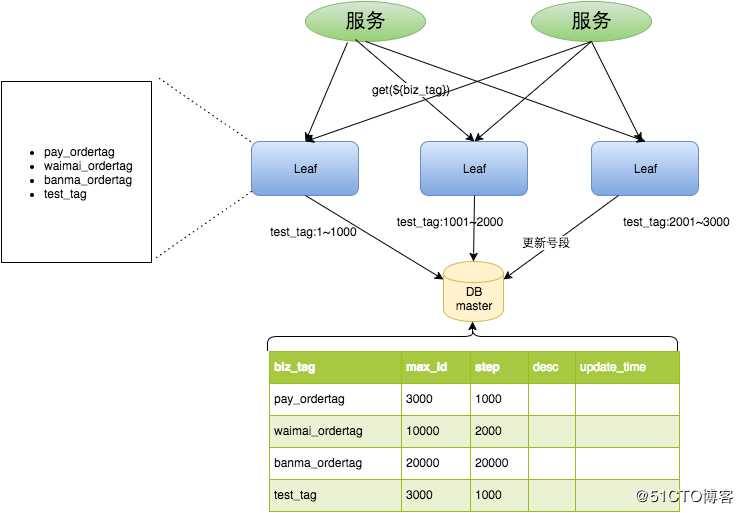
segment架构
从上图我们可以看出,当多个服务同时对 Leaf 进行 ID 获取时,会传入对应的 biz_tag,biz_tag 之间是相互隔离的,互不影响。
比如 Leaf 有三个节点,当 test_tag 第一次请求到 Leaf1 的时候,此时 Leaf1 的 ID 范围就是 1~1000。
当 test_tag 第二次请求到 Leaf2 的时候,此时 Leaf2 的 ID 范围就是 1001~2000。
当 test_tag 第三次请求到 Leaf3 的时候,此时 Leaf3 的 ID 范围就是 2001~3000。
比如 Leaf1 已经知道自己的 test_tag 的 ID 范围是 1~1000,那么后续请求过来获取 test_tag 对应 ID 时候,就会从 1 开始依次递增,这个过程是在内存中进行的,性能高。不用每次获取 ID 都去访问一次数据库。
问题一
这个时候又有人说了,如果并发量很大的话,1000 的号段长度一下就被用完了啊,此时就得去申请下一个范围,这期间进来的请求也会因为 DB 号段没有取回来,导致线程阻塞。
放心,Leaf 中已经对这种情况做了优化,不会等到 ID 消耗完了才去重新申请,会在还没用完之前就去申请下一个范围段。并发量大的问题你可以直接将 step 调大即可。
问题二
这个时候又有人说了,如果 Leaf 服务挂掉某个节点会不会有影响呢?
首先 Leaf 服务是集群部署,一般都会注册到注册中心让其他服务发现。挂掉一个没关系,还有其他的 N 个服务。问题是对 ID 的获取有问题吗? 会不会出现重复的 ID 呢?
答案是没问题的,如果 Leaf1 挂了的话,它的范围是 1~1000,假如它当前正获取到了 100 这个阶段,然后服务挂了。服务重启后,就会去申请下一个范围段了,不会再使用 1~1000。所以不会有重复 ID 出现。
Leaf 改造支持 RPC
如果你们的调用量很大,为了追求更高的性能,可以自己扩展一下,将 Leaf 改造成 Rpc 协议暴露出去。
首先将 Leaf 的 Spring 版本升级到 5.1.8.RELEASE,修改父 pom.xml 即可。
<spring.version>5.1.8.RELEASE</spring.version>
然后将 Spring Boot 的版本升级到 2.1.6.RELEASE,修改 leaf-server 的 pom.xml。
<spring-boot-dependencies.version>2.1.6.RELEASE</spring-boot-dependencies.version>
还需要在 leaf-server 的 pom 中增加 nacos 相关的依赖,因为我们 kitty-cloud 是用的 nacos。同时还需要依赖 dubbo,才可以暴露 rpc 服务。
<dependency>
<groupId>com.cxytiandi</groupId>
<artifactId>kitty-spring-cloud-starter-nacos</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.cxytiandi</groupId>
<artifactId>kitty-spring-cloud-starter-dubbo</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
</dependency>在 resource 下创建 bootstrap.properties 文件,增加 nacos 相关的配置信息。
spring.application.name=LeafSnowflake
dubbo.scan.base-packages=com.sankuai.inf.leaf.server.controller
dubbo.protocol.name=dubbo
dubbo.protocol.port=20086
dubbo.registry.address=spring-cloud://localhost
spring.cloud.nacos.discovery.server-addr=47.105.66.210:8848
spring.cloud.nacos.config.server-addr=${spring.cloud.nacos.discovery.server-addr}Leaf 默认暴露的 Rest 服务是 LeafController 中,现在的需求是既要暴露 Rest 又要暴露 RPC 服务,所以我们抽出两个接口。一个是 Segment 模式,一个是 Snowflake 模式。
Segment 模式调用客户端
/**
* 分布式ID服务客户端-Segment模式
*
* @作者 尹吉欢
* @个人微信 jihuan900
* @微信公众号 猿天地
* @GitHub https://github.com/yinjihuan
* @作者介绍 http://cxytiandi.com/about
* @时间 2020-04-06 16:20
*/
@FeignClient("${kitty.id.segment.name:LeafSegment}")
public interface DistributedIdLeafSegmentRemoteService {
@RequestMapping(value = "/api/segment/get/{key}")
String getSegmentId(@PathVariable("key") String key);
}Snowflake 模式调用客户端
/**
* 分布式ID服务客户端-Snowflake模式
*
* @作者 尹吉欢
* @个人微信 jihuan900
* @微信公众号 猿天地
* @GitHub https://github.com/yinjihuan
* @作者介绍 http://cxytiandi.com/about
* @时间 2020-04-06 16:20
*/
@FeignClient("${kitty.id.snowflake.name:LeafSnowflake}")
public interface DistributedIdLeafSnowflakeRemoteService {
@RequestMapping(value = "/api/snowflake/get/{key}")
String getSnowflakeId(@PathVariable("key") String key);
}使用方可以根据使用场景来决定用 RPC 还是 Http 进行调用,如果用 RPC 就@Reference 注入 Client,如果要用 Http 就用@Autowired 注入 Client。
最后改造 LeafController 同时暴露两种协议即可。
@Service(version = "1.0.0", group = "default")
@RestController
public class LeafController implements DistributedIdLeafSnowflakeRemoteService, DistributedIdLeafSegmentRemoteService {
private Logger logger = LoggerFactory.getLogger(LeafController.class);
@Autowired
private SegmentService segmentService;
@Autowired
private SnowflakeService snowflakeService;
@Override
public String getSegmentId(@PathVariable("key") String key) {
return get(key, segmentService.getId(key));
}
@Override
public String getSnowflakeId(@PathVariable("key") String key) {
return get(key, snowflakeService.getId(key));
}
private String get(@PathVariable("key") String key, Result id) {
Result result;
if (key == null || key.isEmpty()) {
throw new NoKeyException();
}
result = id;
if (result.getStatus().equals(Status.EXCEPTION)) {
throw new LeafServerException(result.toString());
}
return String.valueOf(result.getId());
}
}扩展后的源码参考:https://github.com/yinjihuan/Leaf/tree/rpc_support[2]
感兴趣的 Star 下呗:https://github.com/yinjihuan/kitty[3]
关于作者:尹吉欢,简单的技术爱好者,《Spring Cloud 微服务-全栈技术与案例解析》, 《Spring Cloud 微服务 入门 实战与进阶》作者, 公众号 猿天地 发起人。个人微信 jihuan900,欢迎勾搭。
参考资料
[1]
mt-leaf.html: https://tech.meituan.com/2017/04/21/mt-leaf.html
[2]
Leaf/tree/rpc_support: https://github.com/yinjihuan/Leaf/tree/rpc_support
[3]
kitty: https://github.com/yinjihuan/kitty
相关推荐
- Kitty中的动态线程池支持Nacos,Apollo多配置中心
- 嘘!异步事件这样用真的好么?
- 一时技痒,撸了个动态线程池,源码放Github了
- 熬夜之作:一文带你了解Cat分布式监控
- 笑话:大厂都在用的任务调度框架我能不知道吗???
后台回复 学习资料 领取学习视频
如有收获,点个在看,诚挚感谢
尹吉欢
我不差钱啊
以上是关于分布式ID生成服务,真的有必要搞一个的主要内容,如果未能解决你的问题,请参考以下文章