intel:spectre&Meltdown侧信道攻击
Posted 第七子007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了intel:spectre&Meltdown侧信道攻击相关的知识,希望对你有一定的参考价值。
只要平时对安全领域感兴趣的读者肯定都听过spectre&Meltdown侧信道攻击,今天简单介绍一下这种攻击的原理( https://www.bilibili.com/video/av18144159?spm_id_from=333.788.b_765f64657363.1 这里有详细的视频介绍,墙裂推荐)。
1、CPU顺序执行指令
众所周知,程序是由一条条指令顺序排列构成的,老的cpu也是逐行执行指令;随着cpu的技术发展(著名的摩尔定律),cpu执行指令的速度越来越快,和内存读写速度的差距越来越大。理论上,CPU执行一条指令耗时纳秒左右,但从内存读一次数据需要耗时约100纳秒(参考这里:https://zhuanlan.zhihu.com/p/24726196),理论上相差了百倍,业界称为冯诺依曼瓶颈;这个速度差异不解决,CPU执行速度再快都没用;由此衍生出了近年来CPU的一个重要特性:乱序执行
2、乱序执行:如下所示,比如有个if分支。正常情况下,如果MEM==0才会执行if分支;但CPU由于速度百倍于内存,等把这块内存的数据读出来,下面那4条指令早就执行完了,所以先不判断if条件是否成立,CPU会先执行这4条指令;等前面的指令执行完毕,轮到执行if 的时候,才会从内存读mem的数据,然后判断是否为0. 如果是,说明if这个分支本来就该执行,由于前面已经执行完毕,所以整个效率大大提升;退一步说,就算if条件不成立,cpu白执行了4条指令,这时只需要回退(主要是寄存器的值)即可,和以前的顺序执行比也没啥损失。这种提前预测分支执行的方法截至目前至少看起来没啥损失,还有一定的概率提升整体效率了!这个就是业界所谓的speculative execution!

3、缓存cache
前面说了,CPU执行指令的速度和从内存读数据的速度差了百倍。如果每次执行指令前都要从内存读取数据,CPU会闲死的;为了解决这个问题,衍生出了cpu另一个非常重要的功能:缓存;第一次从内存读取数据后,cpu会先把这些数据存放在内部缓存。下次再需要用这些数据时,不会立刻从内存读,而是先看看自己的缓存种是否已经有了,没有才会继续去内存读取;此种思想方法也能在一定程度上提升程序的执行效率和速度,但问题也随之而来:
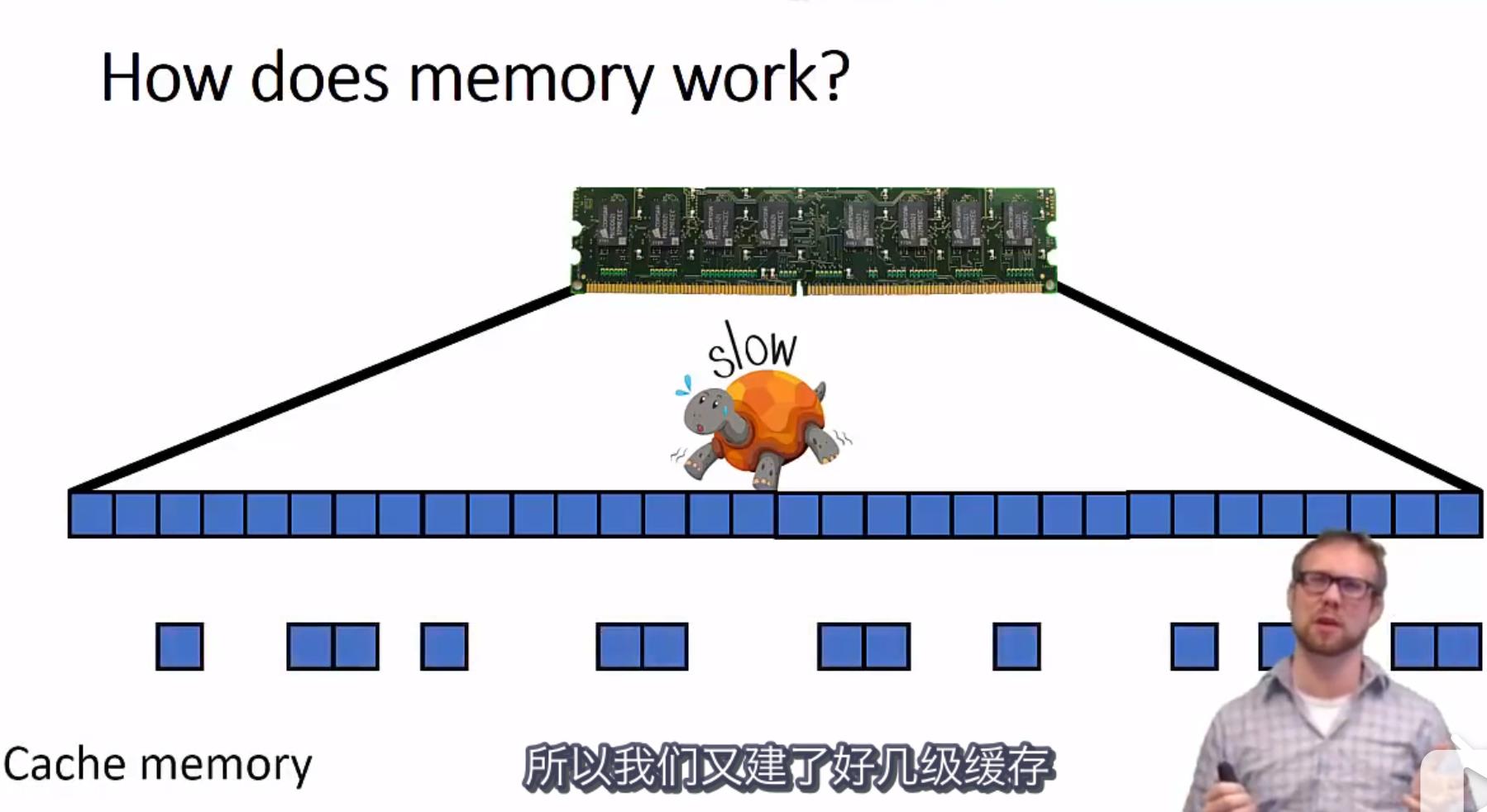
cpu的缓存是否有该数据,直接影响了从内存读取该数据的效率,理论上差了近百倍,这个差异是非常明显的,这就给黑客留下了“把柄”;
4、meltdown和side-channel attack
(1)利用时间差,可以做的攻击有很多,先举一个通俗易懂的栗子:暴力猜密码
比如我设置了一个登陆密码“cnblogs”,用户输入密码后,后台验证的逻辑是逐个字符比对。比如用户输入djgnyd,第一个字符就不对,直接返回false;比如用户输入cjhtsf,第一个字符对了,再继续比对第二个,结果发现第二个错了,再次返回。这就给了黑客可乘之机:多次随机输入密码,利用不同的返回时间差猜测输入的密码是否正确!这就是业界俗称的side-channel attack;
(2)meltdown和side-channel attack
接下来介绍本文的重点:利用spectre和meltdown读取任意内存的数据,而不受任何权限限制;计算机的整个内存种,我们自己程序能用的只是一部分,还有很多内存是不能用的,比如部分内核的内存、其他进程的内存、其他虚拟机的内存(以下简称victim memory),操作系统会通过各种机制确保我们的程序无法访问(比如保护模式下的0~3环+CPL/DPL/RPL等机制控制、操作系统对内存rwx属性的管理)。如果不慎读到这些内存,windows会弹出c000005内存访问错误;如下:
(2.1)假设蓝色是我们能正常使用的内存,红色是无法使用的victim内存;我们在蓝色区域开辟一个数组A(绿色表示),只有两个元素A[0]和A[1]; 通过A指针访问这两个元素是ok的;但是要想通过A+X越界直接访问victim内存是不行的,cpu或操作系统会直接阻止,并抛出异常或弹框报错;
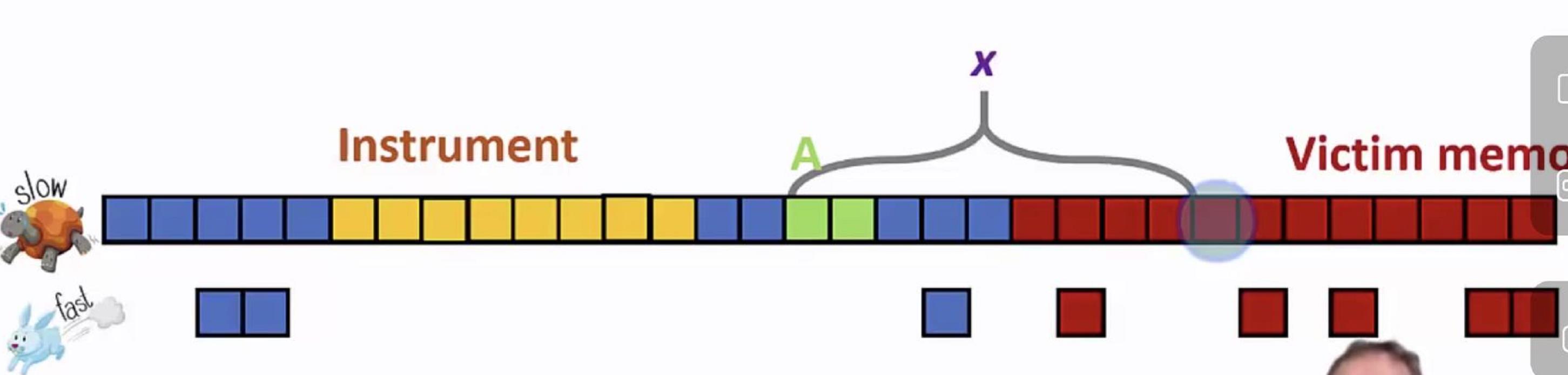
(2.2)同时继续再在蓝色区域开辟一个instrument 的数组,该数据所有数据一律不能存放cpu缓存(后面会解释原因);
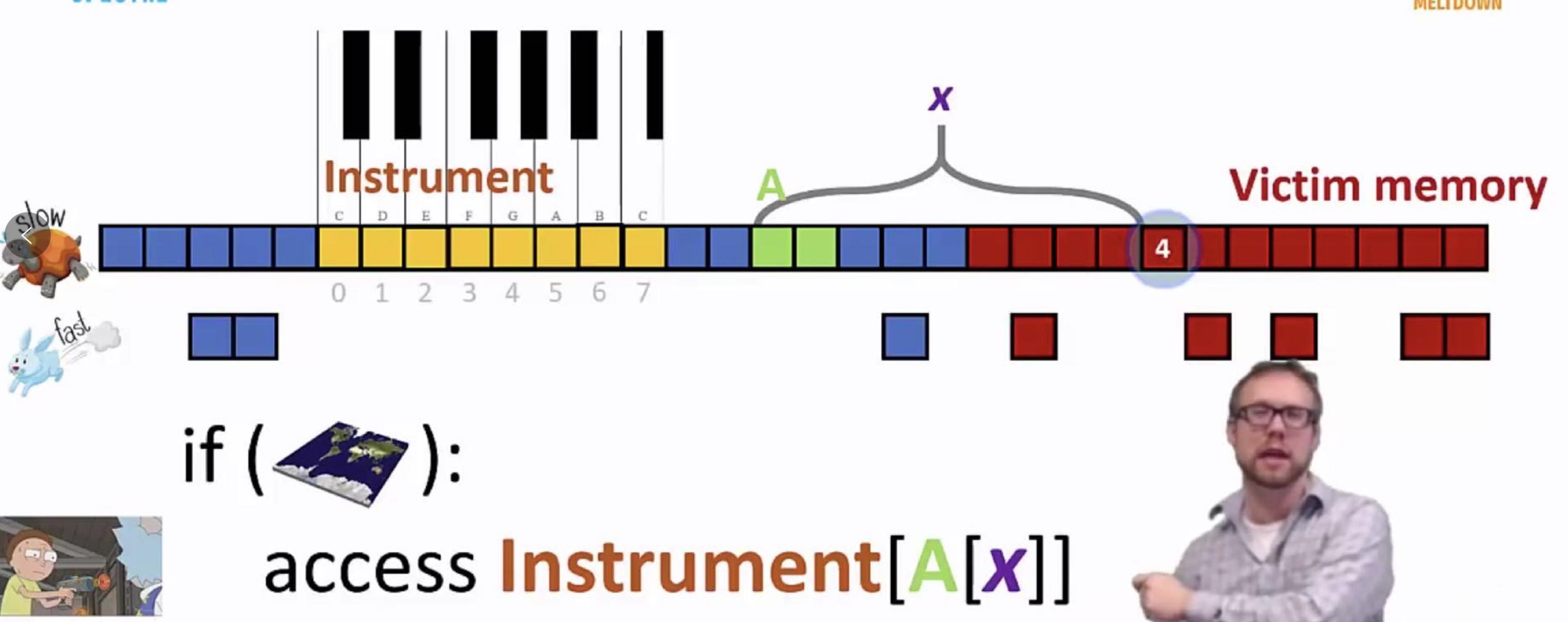
(2.3)接下来最关键的点来了:if(xxx) access Instrument[A[x]]
如果直接执行A[x],由于越界到victim内存,会被终止;但这个指令在if条件分支,cpu的乱序执行特性会先不判断if条件是否成立,而是直接access Instrument[A[x]];此时也不会检查A[x]是否越界,而是直接读取该内存数据;假如读取的数据是4,那么Instrument[A[x]] = G,这个G会被存到CPU缓存;然后又从Instrument0开始一致读取到7,判断哪个数据读取的速度最快(上面有解释:没在缓存的只能从内存读,理论速度差了近百倍),很明显第4个单元的耗时最断,反推出A[x]=4,导致该victim的内存数据泄露;
有读者肯定会问:就算是预测分支乱序执行,为啥不检查A[x]是否越界了?整个攻击最核心的点就在这里啊!个人猜测:这和是cpu、操作系统的分工不明确导致的;cpu提前预测分支指令执行,这时if条件是否成立还不知道了,又怎么去判断A[x]是否越界了? 所以cpu spectaculative设计人员把这个验证的事情甩给了操作系统内核,希望正常执行到该命令时操作系统内核能检查一下是否越界,如果有,再kill程序、抛出异常;但等到操作系统验证时为时已晚,access Instrument[A[x]] 这条指令已经被执行,对应内存的数据已经被读取到了cpu的缓存. 就算if条件不成立,回退的是寄存器的值,cpu缓存的值还是存在的.......
这是核心的js代码:如果操作系统或浏览器没打补丁,理论上用户在浏览网页的时候,黑客可以通过这种方式从内存读取所有数据,导致密码等敏感数据泄露;

5、最后怎么避免自己的程序乱序执行代码了?VS里面把这里设置成已启用就行;

6、简化的代码如下(精华都在注释了),几个核心的函数:
(1)_mm_clflush:清除内存某个单元在cpu中的L1、L2、L3所有的缓存
(2)__rdtscp:开始计时
(3)_mm_mfence:后面的指令只能顺序执行
#include <intrin.h> #include <stdio.h> #include <Windows.h> #define SHIFT_NUMBER 0x0C #define PAGE_SIZE 4096 #define BLOCK_SIZE (1 << SHIFT_NUMBER)//0x1000,一个页 /* (LPBYTE)_aligned_malloc(256 * BLOCK_SIZE, PAGE_SIZE)这里申请了256个页;用flush函数 将这256个页在cpu中的缓存失效 详细解释可以看这了:http://scc.qibebt.ac.cn/docs/optimization/VTune(TM)%20User\'s%20Guide/mergedProjects/analyzer_ec/mergedProjects/reference_olh/instruct32_hh/vc31.htm https://zhuanlan.zhihu.com/p/141144249 */ void CacheLineFlush(LPBYTE lpArray, UINT index) { _mm_clflush(&(lpArray[index << SHIFT_NUMBER])); } void CacheLineFlush_all(LPBYTE lpArray) { for (UINT i = 0; i < 256; i++) CacheLineFlush(lpArray, i); } /************************************************************************/ /* 统计各个块的访问速度,并返回最快的那个块的索引 */ /************************************************************************/ BYTE GetAccessByte(LPBYTE lpArray) { UINT64 speed[256]; UINT64 start, min; UINT index, junk; BYTE result; //为min赋初始值 min = 0; //测试访问速度 for (int i = 0; i < 256; i++) { //获取array[index]的地址;也就是页的索引 index = i << SHIFT_NUMBER; //mfence指令用于序列化内存访问,即让乱序执行无效化。 //后面的指令必须在前面的内存读写完成后再开始发射执行。 _mm_mfence(); //记录开始周期 start = __rdtscp(&junk); junk = *(LPDWORD)(&lpArray[index]);//记录读取每个单元的时间 _mm_mfence(); speed[i] = __rdtscp(&junk) - start; //如果是初始值,或者比当前值还小 if ((min == 0) || (speed[i] < min)) { min = speed[i]; result = (BYTE)i; } } return result; } /************************************************************************/ /* 用index作为数组索引,访问array的某个元素 */ /************************************************************************/ BYTE AccessArray(LPBYTE lpArray, UINT index) { return lpArray[index << SHIFT_NUMBER];//左移12位,效果相当于乘以4096;那么可以把index看成是页的索引,这里访问index指向页开头的第一个字节; } int main() { //假定的kernel内存 BYTE kernel[4]; //array是用户可控制的内存 LPBYTE array; kernel[0] = 0x55; kernel[1] = 0xAA; kernel[2] = 0xF0; kernel[3] = 0x0F; /* 分配256个页,作用相当于视频中的instrument;为什么是256了?内存中每个最小单元是1字节,能表示从0~255一共256个数; 后续会挨个读取这256个页开头的第一个字节,如果速度快,说明cpu里面已经有缓存了,kernel单元(也就是视频中的victim单元) 大概是是这个数; */ array = (LPBYTE)_aligned_malloc(256 * BLOCK_SIZE, PAGE_SIZE); /* 实现原理: kernel假定是受保护的内存数据 (本demo里可访问)。 array为用户可控制的一个数组,一共分为256个块,每个块的大小为2的整数倍: (1 << SHIFT_NUMBER)。 然后从kernel中读取一个byte,以这个byte为索引,去访问array所对应的块。 之后立刻循环读取一遍array的各个块,如果之前访问成功了,那么对应的块应该还在缓存中,对应的访问时间要少很多。 统计各个块的访问周期数,最快的块,他的索引就是受保护的那个byte。 CacheLineFlush_all 函数用于把整个数组从缓存中清除出去,这样不至于污染访问速度。 AccessArray 函数用于以一个索引去访问一个数组。 GetAccessByte 函数用于测试数组的各个块的访问速度,返回最快的那个块的索引。 */ CacheLineFlush_all(array);//清空自己申请的256页在cpu的缓存,避免影响后续的读取计时 AccessArray(array, kernel[0]);//这里为了突出重点说明侧信道攻击,并没有用if分支预测执行,而是直接用kernel的元素做下标访问,让这个数写入cpu缓存 printf("Access fastest: 0x%02X\\n", (DWORD)GetAccessByte(array));//看看哪个内存单元读取的速度最快,由此反推出kernel元素的值 CacheLineFlush_all(array); AccessArray(array, kernel[1]); printf("Access fastest: 0x%02X\\n", (DWORD)GetAccessByte(array)); CacheLineFlush_all(array); AccessArray(array, kernel[2]); printf("Access fastest: 0x%02X\\n", (DWORD)GetAccessByte(array)); CacheLineFlush_all(array); AccessArray(array, kernel[3]); printf("Access fastest: 0x%02X\\n", (DWORD)GetAccessByte(array)); getchar(); return 0; }
参考:https://www.freebuf.com/articles/system/159811.html 一步一步理解CPU芯片漏洞:Meltdown与Spectre
https://meltdownattack.com/ 官网
https://www.bilibili.com/video/av18144159?spm_id_from=333.788.b_765f64657363.1 15分钟读懂英特尔熔断幽灵漏洞-Emory
https://www.fortinet.com/blog/threat-research/into-the-implementation-of-spectre (中文翻译:https://zhuanlan.zhihu.com/p/33635193)Spectre 攻击详解(详细的demo代码)
https://bbs.pediy.com/thread-224040.htm 简短的demo代码,非常适合入门学习原理
https://www.cnblogs.com/zenny-chen/archive/2013/03/28/2986527.html 与Cache相关的控制
https://bbs.pediy.com/thread-254288.htm spectre跨进程泄露敏感信息
以上是关于intel:spectre&Meltdown侧信道攻击的主要内容,如果未能解决你的问题,请参考以下文章
Centos打补丁解决intel的Spectre和Meltdown漏洞
CPU特性漏洞测试(Meltdown and Spectre)
Spectre & Meltdown Checker – CPU芯片漏洞检查脚本Linux版