分布式爬虫
Posted 一只小鱼儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式爬虫相关的知识,希望对你有一定的参考价值。
这个分布式爬虫是以前自己和同学一起合作的,后来在这个基础上改进了一些特性,同样的只是提供一个大概的思路,欢迎大家提出建议(注:爬虫代码仅供学习参考,须在法律允许范围内使用)
github链接:https://github.com/colabin/distributed_spider_demo
功能简介:
这个爬虫是一个可拓展的分布式爬虫,采用主从的通信模式,在主机端维护url队列,当从机与主机打招呼后,主机会分发url给从机,从机得到url后进行解析,再返回解析结果给主机持久化,然后主机再分配一个url给从机循环该过程,整个过程就是这样。
遇到的一些问题:
在之前的面试中,面试官问道从机每爬取一次就返回给主机,这样不会造成主机压力比较大?于是当时也考虑了不同的方案,一种方案是从机接收到url后就一直在本地循环解析,url加入队列,再持久化的过程,这样就只需要和主机打个招呼拿个url就完了,但是这样会造成一个问题,就是url的过滤,因为目前方案中url过滤在主机端进行,主机会过滤掉已爬取的url和重复的url,采用这种方案会导致从机之间不知道对方爬了哪些网页,如果在从机之间增加通信则会大大增加这个爬虫的复杂度,也考虑过为每个从机分配一个hash值,根据hash值判断要不要爬取url,这样从机爬取的url就不会重复,这个方案有一定的可行性,也是可以改进的一种方案。考虑到实际情况,当前爬虫的瓶颈主要是网络请求这一块,所以还是采取当前的通信模式了
还有一个问题就是连接的问题,当前主机和从机采取的是短连接的方式,就是从机每请求一次url都会建立一个新连接请求,从机爬取完后传回主机就断开连接,下次继续发起新的请求获取url。考虑过长连接,这样就不必接连不断地发起请求,但是长连接和短连接哪个性能好一点我还没试,希望有大神能够讲解一下。
这个爬虫作品目前来说是理想型的,没有考虑丢包情况下从机如何处理,从代码可以看出是从机发送一个请求过去会默认一定可以接受到主机的回复,如果发给主机的包丢失或者主机发回的包丢失那么从机就会处于阻塞状态,目前想法是通过线程休眠和轮询实现超时重新发起请求,重传3次失败则抛出异常,以后有时间我会改进一下,或者大家有更好的建议可以提出来。
为了提高容错性,我们在主机端维护了一个任务队列,当分配给从机一个任务后,如果从机10s内没有返回任务结果(可能是从机抛错等各种异常),则主机会将该任务从任务队列中移除并将url重新加入待爬取队列分配给其他从机
关于爬虫入门的一系列文章中提到的问题,这个爬虫里面也有了解决方案对应的代码,有些代码还不是很完善,也只是给大家提供一个大致的思路(部分解决方案的代码也是从网上搜索找来的,如果有作者看到是自己的代码请联系我,我会补充上作者信息)
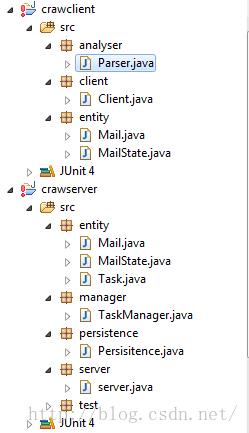
项目结构图如下:
下面我贴出部分关键代码:
server client共用类
Mail类:作为主机和从机之间的通信类(部分getter,setter函数省略掉,太占篇幅)
public class Mail implements Serializable {
private static final long serialVersionUID = 1L;
private final MailState Type; //消息类型分为3类:握手,爬取内容,挥手
private String urlList = "";
private List<String> extractedContent = new ArrayList<String>();
private String taskId;
}
MailState类:消息类型
public enum MailState {
Greeting,Passage,Bye;
}
server :
Task类:任务对象
public class Task {
String taskId;
String url;
String createTime;
}
TaskManager类:维护url的去重和任务队列的监控
public class TaskManager extends java.util.TimerTask {
public LinkedList<String> urlToCrawList = new LinkedList<>();
public HashSet<String> urlCrawedHashSet = new HashSet<>();
public List<Task> taskQueueList = new LinkedList<>();
public Task getTaskById(String id){
for(Task task: taskQueueList ){
if(task.getTaskId().equals(id)){
return task;
}
}
return null;
}
@Override
public void run() {
// TODO Auto-generated method stub
Date now = new Date();
for(Task task : taskQueueList){
String createTime = task.getCreateTime();
SimpleDateFormat df = new SimpleDateFormat("yyyyMMddhhmmss");
Date cDate = null;
try {
cDate = df.parse(createTime);
} catch (ParseException e) {
e.printStackTrace();
}
long dif = (now.getTime() - cDate.getTime())/1000 ;
if(dif>7){ //运行时间超过7s,判定任务无效,重新加入等待执行队列
urlToCrawList.add(task.getUrl());
taskQueueList.remove(task);
System.err.println("因任务超时,url"+task.getUrl()+"被重新加回待爬取队列,任务"+task.getTaskId()+"被从监听队列移除");
}
}
}
}
server类 :
public class server {
Lock lock = new Lock();
Persisitence persistence = new Persisitence();
boolean isListen = true; // 表示服务器是否继续接收链接
int downMes = 0; // 提取到的网页数量
int clientNum = 0 ; //连接的客户端数量
int numToCraw = 10; // 限制爬取数量
int depthToCraw = 3; // 限制爬取层数
ServerSocket clientListener;
int port; // 监听端口
TaskManager taskManager = new TaskManager();
ExecutorService executor = Executors.newFixedThreadPool(50); // 创建固定容量大小的缓冲池
public server3(int por, String url) throws Exception {
this.port = por;
taskManager.urlToCrawList.add(url);
}
public void setNumToCraw(int numToCraw) {
this.numToCraw = numToCraw;
}
public void setDepthToCraw(int depthToCraw) {
this.depthToCraw = depthToCraw;
}
public void start() throws IOException {
clientListener = new ServerSocket(port);
while (true) {
System.out.println("主线程等待客户端连接");
Socket socket = clientListener.accept();
// 开启一个线程
executor.execute(new CreateServerThread(socket));
// 不断轮训判断是否满足爬取条件
// if (downMes >= numToCraw ||depthToCraw >=5 ) {
// isListen = false; // 此时服务器主动与客户端挥手
// }
// if (clientNum<= 0 ) {
// return;
// }
}
}
class Lock {
} // 用于同步对任务队列的访问
class CreateServerThread implements Runnable {
private Socket client;
ObjectInputStream is = null;
ObjectOutputStream os = null;
Mail2 send ;
Mail2 get ;
public CreateServerThread(Socket s) throws IOException {
client = s;
}
@Override
public void run () {
System.out.println("进入服务器端子线程并和"+client.getInetAddress()+"开始通信");
try {
is = new ObjectInputStream(new BufferedInputStream(
client.getInputStream()));
os = new ObjectOutputStream(client.getOutputStream());
String contentExtracted = null ;
Mail2 get = (Mail2) is.readObject();
if (!isListen) {
os.writeObject(new Mail2(MailState.Bye)); // 客户端可能还会传链接过来客户端进入END状态开始上传
clientNum -- ;
is.close();
os.close();
return ;
}
switch (get.getType()) {
case Greeting:
clientNum++ ; //客户端连接数量+1
if (taskManager.urlToCrawList.size() != 0) {
synchronized (lock) { sendURL();}
}
else{
Thread.sleep(10000);
if (taskManager.urlToCrawList.size() != 0){
synchronized (lock) { sendURL();}
}
else{
os.writeObject(new Mail2(MailState.Bye)); // 客户端可能还会传链接过来客户端进入END状态开始上传
os.close();
}
}
// Timer timer = new Timer(); // 定时扫描任务队列,清楚超时的任务
// timer.schedule(taskManager, 1000, 5000); // 1s后执行,每5s扫描一次
break;
case Passage:
List<String> extractedContent2 = get.getExtractedContent();
System.err.println("服务器获得的网页内容————————————————————"+extractedContent2.toString());
//持久化
downMes++;
String[] links = get.getUrlList().split(" ");
for (String a : links) {
System.err.println("传来的链接数"+links.length);
// if (!taskManager.urlCrawedHashSet.contains(a)&& !taskManager.urlToCrawList.contains(a)) // 保护客户端以前没有爬取过和待爬取队列不重复
taskManager.urlToCrawList.offerLast(a); // 将客户端发过来的链接全部压入队列
System.err.println("传来url压入队列,目前待爬取url队列数量"+taskManager.urlToCrawList.size());
}
String taskid = get.getTaskId();
Task t = taskManager.getTaskById(taskid);
taskManager.taskQueueList.remove(t); // 从执行队列里移除
System.err.println("url压入队列完毕,任务Id:"+t.getTaskId()+"url:"+t.getUrl()+"完成并从任务队列移除");
taskManager.urlCrawedHashSet.add(t.getUrl()); // 将url添加到已爬取队列
System.err.println("url:"+t.getUrl()+"加入到已爬取url队列");
//从队列里面取url,对队列的访问要加锁
if (taskManager.urlToCrawList.size() != 0) {
synchronized (lock) { sendURL();}
}
else{
Thread.sleep(10000);
if (taskManager.urlToCrawList.size() != 0){
synchronized (lock) { sendURL();}
}
else{
os.writeObject(new Mail2(MailState.Bye)); // 客户端可能还会传链接过来客户端进入END状态开始上传
os.close();
}
}
default:
return ;
} // 结束switch
} catch (Exception e) {
e.printStackTrace();
}
}
private void sendURL() throws IOException {
String url = taskManager.urlToCrawList.poll();
Task task = new Task(url);
String createTime = new SimpleDateFormat("yyyyMMddhhMMss").format(new Date()); // 生成加入队列时间
task.setCreateTime(createTime);
taskManager.taskQueueList.add(task); // 加入任务队列
Mail2 mail = new Mail2(MailState.Linking);
mail.setUrlList(url);
mail.setTaskId(task.getTaskId());
System.err.println("任务Id:"+task.getTaskId()+"url:"+task.getUrl()+"被加入到任务监听队列");
System.err.println("任务Id:"+task.getTaskId()+"url:"+task.getUrl()+"被发送到client");
os.writeObject(mail);
os.flush();
}
}
public static void main(String[] args) throws Exception{
server3 s = new server3(9000, "http://www.qq.com");
s.setDepthToCraw(1);
s.setNumToCraw(1);
s.start();
}
}
client :
parser类:解析url和网页源码(提取规则根据具体抓取需求自行实现)
public class Parser {
public static String proxyIPList[] = {"ec2-50-16-197-120.compute-1.amazonaws.com"};
public static int proxyPortList[] = { 8001};
WebBrowser webBrowser = new WebBrowser();
List<String> nextPageLinks = new ArrayList<String>();
public String getUrlContent(String url) throws Exception {
URL urlToDownload = new URL(url);
HttpURLConnection conn = (HttpURLConnection) urlToDownload.openConnection();
conn.setRequestProperty("User-agent","Mozilla/5.0 (Windows NT 6.1; rv:16.0) Gecko/20100101 Firefox/16.0");
// conn.setRequestProperty("Cookie",""); //模拟登录功能
conn.setConnectTimeout(3000);
conn.setReadTimeout(3000);
for (int i = 1; i <= 3; i++) { //抛错则减慢爬取速率,重试3次
try {
conn.connect();
int code = conn.getResponseCode();
// ip被限制,切换ip代理
if (code == HttpStatus.SC_FORBIDDEN) {
for (int j = 0; i < proxyIPList.length; i++) {
if (testProxyServer(url, proxyIPList[i], proxyPortList[i])) { // 代表有可以用的代理ip
return getUrlContent(url);
}
if (i == proxyIPList.length) {
return null;
}
}
}
// 页面重定向
if (code == HttpStatus.SC_MOVED_PERMANENTLY
|| code == HttpStatus.SC_MOVED_TEMPORARILY
|| code == HttpStatus.SC_SEE_OTHER
|| code == HttpStatus.SC_TEMPORARY_REDIRECT) {
// 读取新的URL地址
String location = conn.getHeaderField("location");
// 再根据location爬取一遍
getUrlContent(location);
}
if (code == HttpStatus.SC_OK) { // 如果获取到网页字符集
String line = null;
StringBuffer bf = new StringBuffer();
if (conn.getContentEncoding() != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(conn.getInputStream(),
conn.getContentEncoding()));
while ((line = reader.readLine()) != null) {
bf.append(line);
}
return bf.toString();
} else {
BufferedReader reader = new BufferedReader(
new InputStreamReader(conn.getInputStream(), "gbk"));
while ((line = reader.readLine()) != null) {
bf.append(line);
}
return bf.toString();
}
}
//成功则
} catch (Exception e) {
try {
if(i==3){
System.out.println("3次重试均失败");
break ;
}
Thread.sleep(i * 3000);
e.printStackTrace();
System.out.println("正在等待重试");
continue;
} catch (InterruptedException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
}
return conn.getResponseMessage();
}
/**
* 设置代理
*/
public void setProxy(String proxyIP, int proxyPort) {
// 有些代理在授权用户访问因特网之前,要求用户输入用户名和口令。如果您使用位于防火墙之内的Web浏览器,您就可能碰到过这种情况。以下是执行认证的方法:
// URLConnection connection=url.openConnection(); String password="username:password";
// String encodedPassword=base64Encode(password);
// connection.setRequestProperty("Proxy-Authorization",encodedPassword);
// 设置爬取的代理(外网环境下注释掉就可以)
System.getProperties().put("proxySet", "true");
System.getProperties().put("proxyHost", proxyIP);
System.getProperties().put("proxyPort", proxyPort);
}
private boolean testProxyServer(String url, String proxyIP, int proxyPort) {
// TODO Auto-generated method stub
setProxy(proxyIP, proxyPort);
try {
HttpURLConnection conn = (HttpURLConnection) new URL(url).openConnection();
conn.connect();
int statusCode = conn.getResponseCode();
if (statusCode == 403) {
return false;
}
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
/**
* 获取网页编码
* @param url
* @return
*/
public String getCharset(String url) throws Exception {
// log.info("进入读页面的关键词:" + keyword);
String charset = "";
URL httpurl = new URL(url);
HttpURLConnection httpurlcon = (HttpURLConnection) httpurl
.openConnection();
// google需要身份
httpurlcon.setRequestProperty("User-agent", "Mozilla/4.0");
charset = httpurlcon.getContentType();
// 如果可以找到
if (charset.indexOf("charset=") != -1) {
charset = charset.substring(charset.indexOf("charset=")
+ "charset=".length(), charset.length());
return charset;
} else {
return null;
}
}
/**
*
* 动态加载js页面
* @param url
* @return
*/
private String dynamicDownLoad(String url) throws Exception {
//webBrowser.setURL(new URL(url));
// webBrowser .addWebBrowserListener(new WebBrowserListener() {
// public void documentCompleted(WebBrowserEvent event) { }
// public void downloadStarted(WebBrowserEvent event) {}
// public void downloadCompleted(WebBrowserEvent event) { }
// public void downloadProgress(WebBrowserEvent event) { }
// public void downloadError(WebBrowserEvent event) { }
// public void titleChange(WebBrowserEvent event) { }
// public void statusTextChange(WebBrowserEvent event) { }
// public void windowClose(WebBrowserEvent arg0) { }
// }); //添加监听事件
String jscript = "function getAllhtml() {" + "var a='';"
+ "a = '<html><head><title>';" + "a += document.title;"
+ "a += '</title></head>';" + "a += document.body.outerHTML;"
+ "a += '</html>';" + "return a;" + "}" + "getAllHtml();";
String result = webBrowser.executeScript(jscript);
return null;
}
/**
* @param number 提取分页的个数
* @return
*/
public List<String> extracLinks(String content,int number) throws Exception {
Document doc = Jsoup.parse(content);
if(number==0){ //不需要进行分页爬取
//TODO 制定规则提取链接
return null ;
}
else{
if(number==0){ //达到提取分页的个数,停止爬取
return null;
}
else{
//TODO 制定规则提取下一页链接,深度遍历
nextPageLinks.add("下一页link");
number--;
extracLinks("下一页链接",number);
}
return nextPageLinks ;
}
}
public String extractContent(String content) throws Exception {
Document doc = Jsoup.parse(content);
//TODO 制定规则提取要抓取内容
return null;
}
}
client类:
public class client {
Socket ServerConnection;
int port;
String ip;
Parser parser = new Parser(); // 用于获取网页的内容
Mail2 get ;
Mail2 send;
client3( String ip,int port) {
TimeZone tz = TimeZone.getTimeZone("ETC/GMT-8");
TimeZone.setDefault(tz);
this.port = port;
this.ip = ip;
}
public void handing() throws Exception{
ServerConnection = new Socket(ip, port);
ObjectOutputStream os = new ObjectOutputStream(ServerConnection.getOutputStream());
ObjectInputStream is = new ObjectInputStream(new BufferedInputStream(ServerConnection.getInputStream()));
send = new Mail2(MailState.Greeting);
os.writeObject(send);
os.flush();
get = (Mail2)is.readObject(); //获得链接
String msgType = get.getType().toString();
System.err.println("第一次打招呼,服务器传回的消息类型"+msgType);
handleMessage(get);
is.close();
os.close();
ServerConnection.close();
}
public void run() throws Exception {
handing();
work();
}
private void work() {
while (true) {
try {
System.err.println("尝试连接服务器");
ServerConnection = new Socket(ip,port);
ObjectOutputStream os = new ObjectOutputStream(ServerConnection.getOutputStream());
ObjectInputStream is = new ObjectInputStream(new BufferedInputStream(ServerConnection.getInputStream()));
System.err.println("连接成功");
System.out.println("现在开始将链接和内容上传,待上传链接" + send.getUrlList());
os.writeObject(send); // 将爬取到的链接发送到server
os.flush();
System.out.println("上传完毕" );
Mail2 get = (Mail2)is.readObject(); //服务器接收到一个url链接可能会返回一个待爬取的url,也可能是bye
handleMessage(get);
is.close();
os.close();
ServerConnection.close();
}
catch (Exception e) {
e.printStackTrace();
System.out.println("Connection Error:" + e);
}
}
}
private void handleMessage(Mail2 get2) throws Exception {
// TODO Auto-generated method stub
if(get.getType()==MailState.Bye){ //bye则停止工作
return ;
}
String url = get.getUrlList(); //服务端传回url, 先默认url是一个,以后改成多个以逗号连接的url则需要循环调用 parser.getUrlContent(url)
String taskId = get.getTaskId();
System.out.println("服务器传来的待爬取url:"+url+" taskid:"+taskId);
//提取传来url中的链接保存到待上传队列
String content = parser.getUrlContent(url);
List<String> linksExtracted = parser.extracLinks(content,0);
String contentExtracted = parser.extractContent(content);
send = new Mail2(MailState.Passage);
send.getExtractedContent().add(contentExtracted);
StringBuffer link_list = new StringBuffer();
for (String str : linksExtracted) {
link_list.append(str).append(",");
}
send.setUrlList(link_list.toString());
send.setTaskId(taskId); //默认上传玩提取链接后才算任务完成
System.err.println("链接抓取和内容抓取完成");
}
@Test
public static void main(String[] args) throws Exception{
client3 cli1=new client3("127.0.0.1",9000);
cli1.run();
}
}
要指出的是限制爬取深度这个功能暂时是为实现的,不过理论上来说按照前文说的给url附加个深度属性,服务器进行判断达到限定深度即可停止爬取是可以实现的,以后有时间我会完善这一部分
关键代码片段如上,一些细节部分留待大家去分析,有什么建议和疑问都可以告诉我~
以上是关于分布式爬虫的主要内容,如果未能解决你的问题,请参考以下文章