爬虫--Scrapy-CrawlSpider&分布式爬虫
Posted foremostxl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫--Scrapy-CrawlSpider&分布式爬虫相关的知识,希望对你有一定的参考价值。
CrawlSpider
CrawlSpider: 问题:如果我们想要对某一个网站的全站数据进行爬取? 解决方案: 1. 手动请求的发送 2. CrawlSpider(推荐)
之前的事基于Spider类
CrawlSpider概念:CrawlSpider其实就是Spider的一个子类。CrawlSpider功能更加强大(链接提取器,规则解析器)。 代码: 1. 创建一个基于CrawlSpider的爬虫文件 a) scrapy genspider –t crawl 爬虫名称 起始url
-------
scrapy.spiders.CrawlSpider 创建项目:scrapy startproct 创建爬虫:scrapy genspider –t crawl 核心处理规则: from scrapy.spiders import CrawlSpider, Rule 核心处理提取: from scrapy.linkextractors import LinkExtractor
创建工程scrapy startproject crawlSpiderPro
cd crawlSpiderPro
创建爬虫文件 scrapy genspider -t crawl chouti dig.chouti.com
基于scrapySpider爬虫文件的和基于spider的不同之处
爬虫文件chouti.py
class ChoutiSpider(CrawlSpider): name = ‘chouti‘ #allowed_domains = [‘dig.chouti.com‘] start_urls = [‘https://dig.chouti.com/‘] #实例化了一个链接提取器对象 #链接提取器:用来提取指定的链接(url) #allow参数:赋值一个正则表达式 #链接提取器就可以根据正则表达式在页面中提取指定的链接 #提取到的链接会全部交给规则解析器 link = LinkExtractor(allow=r‘/all/hot/recent/d+‘) rules = ( #实例化了一个规则解析器对象 #规则解析器接受了链接提取器发送的链接后,就会对这些链接发起请求,获取链接对应的页面内容,就会根据指定的规则对页面内容中指定的数据值进行解析 #callback:指定一个解析规则(方法/函数) #follow:是否将链接提取器继续作用到连接提取器提取出的链接所表示的页面数据中 Rule(link, callback=‘parse_item‘, follow=), ) def parse_item(self, response): print(response)
# 对应的编写response.xpath()---存到items ----将items传给管道---在管道进行持久化存储
# follow=True 所有的页面数据
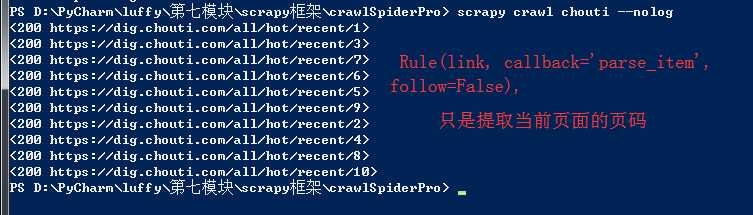

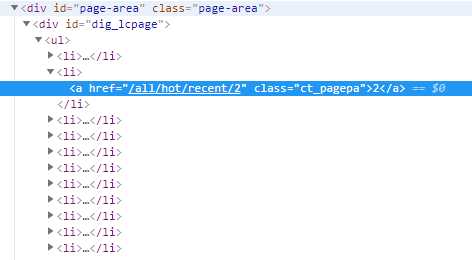
link = LinkExtractor(allow=r‘/all/hot/recent/d+‘)
---------------------------------------------
Rule(link, callback=‘parse_item‘, follow=True),
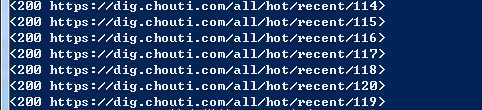
分布式爬虫
分布式爬虫:
1. 概念:多台机器上可以执行同一个爬虫程序,实现网站数据的分布爬取。
2. 原生的scrapy是不可以实现分布式爬虫?
a) 调度器无法共享
b) 管道无法共享
3. scrapy-redis组件:专门为scrapy开发的一套组件。该组件可以让scrapy实现分布式。
a) 下载:pip install scrapy-redis
4. 分布式爬取的流程:
a) redis配置文件的配置:
i. bind 127.0.0.1 进行注释
ii. protected-mode no 关闭保护模式
b) redis服务器的开启:基于配置配置文件----

c) 创建scrapy工程后,创建基于crawlSpider的爬虫文件 d) 导入RedisCrawlSpider类,然后将爬虫文件修改成基于该类的源文件 e) 将start_url修改成redis_key = ‘XXX’ f) 在配置文件中进行相应配置:将管道配置成scrapy-redis集成的管道 g) 在配置文件中将调度器切换成scrapy-redis集成好的调度器 h) 执行爬虫程序:scrapy runspider xxx.py i) redis客户端:lpush 调度器队列的名称 “起始url” 【补充】 #如果redis服务器不在自己本机,则需要在setting中进行如下配置 REDIS_HOST = ‘redis服务的ip地址‘ REDIS_PORT = 6379
【注意】近期糗事百科更新了糗图板块的反爬机制,更新后该板块的页码链接/pic/page/2/s=5135066,末尾的数字每次页面刷新都会变化,
因此爬虫文件中链接提取器的正则不可写为/pic/page/d+/s=5135066而应该修改成/pic/page/d+
以上是关于爬虫--Scrapy-CrawlSpider&分布式爬虫的主要内容,如果未能解决你的问题,请参考以下文章