Spark修炼之道(进阶篇)——Spark入门到精通:第十节 Spark SQL案例实战
Posted zhouzhihubeyond
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark修炼之道(进阶篇)——Spark入门到精通:第十节 Spark SQL案例实战相关的知识,希望对你有一定的参考价值。
作者:周志湖
放假了,终于能抽出时间更新博客了…….
1. 获取数据
本文通过将github上的Spark项目git日志作为数据,对SparkSQL的内容进行详细介绍
数据获取命令如下:
[[email protected] spark]# git log --pretty=format:‘{"commit":"%H","author":"%an","author_email":"%ae","date":"%ad","message":"%f"}‘ > sparktest.json格式化日志内容输出如下:
[[email protected] spark]# head -1 sparktest.json
{"commit":"30b706b7b36482921ec04145a0121ca147984fa8","author":"Josh Rosen","author_email":"[email protected]","date":"Fri Nov 6 18:17:34 2015 -0800","message":"SPARK-11389-CORE-Add-support-for-off-heap-memory-to-MemoryManager"}
然后使用命令将sparktest.json文件上传到HDFS上
[root@master spark]#hadoop dfs -put sparktest.json /data/2. 创建DataFrame
使用数据创建DataFrame
scala> val df = sqlContext.read.json("/data/sparktest.json")
16/02/05 09:59:56 INFO json.JSONRelation: Listing hdfs://ns1/data/sparktest.json on driver查看其模式:
scala> df.printSchema()
root
|-- author: string (nullable = true)
|-- author_email: string (nullable = true)
|-- commit: string (nullable = true)
|-- date: string (nullable = true)
|-- message: string (nullable = true)3. DataFrame方法实战
(1)显式前两行数据
scala> df.show(2)
+----------------+--------------------+--------------------+--------------------+--------------------+
| author| author_email| commit| date| message|
+----------------+--------------------+--------------------+--------------------+--------------------+
| Josh Rosen|[email protected]|30b706b7b36482921...|Fri Nov 6 18:17:3...|SPARK-11389-CORE-...|
|Michael Armbrust|[email protected]|105732dcc6b651b97...|Fri Nov 6 17:22:3...|HOTFIX-Fix-python...|
+----------------+--------------------+--------------------+--------------------+--------------------+(2)计算总提交次数
scala> df.count
res4: Long = 13507
下图给出的是我github上的commits次数,可以看到,其结束是一致的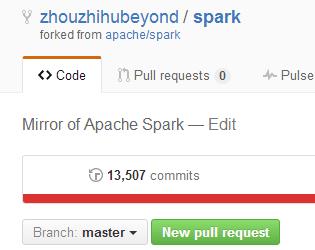
(3)按提交次数进行降序排序
scala>df.groupBy("author").count.sort($"count".desc).show
+--------------------+-----+
| author|count|
+--------------------+-----+
| Matei Zaharia| 1590|
| Reynold Xin| 1071|
| Patrick Wendell| 857|
| Tathagata Das| 416|
| Josh Rosen| 348|
| Mosharaf Chowdhury| 290|
| Andrew Or| 287|
| Xiangrui Meng| 285|
| Davies Liu| 281|
| Ankur Dave| 265|
| Cheng Lian| 251|
| Michael Armbrust| 243|
| zsxwing| 200|
| Sean Owen| 197|
| Prashant Sharma| 186|
| Joseph E. Gonzalez| 185|
| Yin Huai| 177|
|Shivaram Venkatar...| 173|
| Aaron Davidson| 164|
| Marcelo Vanzin| 142|
+--------------------+-----+
only showing top 20 rows
4. DataFrame注册成临时表使用实战
使用下列语句将DataFrame注册成表
scala> val commitLog=df.registerTempTable("commitlog")
(1)显示前2行数据
scala> sqlContext.sql("SELECT * FROM commitlog").show(2)
+----------------+--------------------+--------------------+--------------------+--------------------+
| author| author_email| commit| date| message|
+----------------+--------------------+--------------------+--------------------+--------------------+
| Josh Rosen|[email protected]|30b706b7b36482921...|Fri Nov 6 18:17:3...|SPARK-11389-CORE-...|
|Michael Armbrust|[email protected]|105732dcc6b651b97...|Fri Nov 6 17:22:3...|HOTFIX-Fix-python...|
+----------------+--------------------+--------------------+--------------------+--------------------+
(2)计算总提交次数
scala> sqlContext.sql("SELECT count(*) as TotalCommitNumber FROM commitlog").show
+-----------------+
|TotalCommitNumber|
+-----------------+
| 13507|
+-----------------+
(3)按提交次数进行降序排序
scala> sqlContext.sql("SELECT author,count(*) as CountNumber FROM commitlog GROUP BY author ORDER BY CountNumber DESC").show
+--------------------+-----------+
| author|CountNumber|
+--------------------+-----------+
| Matei Zaharia| 1590|
| Reynold Xin| 1071|
| Patrick Wendell| 857|
| Tathagata Das| 416|
| Josh Rosen| 348|
| Mosharaf Chowdhury| 290|
| Andrew Or| 287|
| Xiangrui Meng| 285|
| Davies Liu| 281|
| Ankur Dave| 265|
| Cheng Lian| 251|
| Michael Armbrust| 243|
| zsxwing| 200|
| Sean Owen| 197|
| Prashant Sharma| 186|
| Joseph E. Gonzalez| 185|
| Yin Huai| 177|
|Shivaram Venkatar...| 173|
| Aaron Davidson| 164|
| Marcelo Vanzin| 142|
+--------------------+-----------+
更多复杂的玩法,大家可以自己去尝试,这里给出的只是DataFrame方法与临时表SQL语句的用法差异,以便于有整体的认知。
以上是关于Spark修炼之道(进阶篇)——Spark入门到精通:第十节 Spark SQL案例实战的主要内容,如果未能解决你的问题,请参考以下文章