精通Spark系列弹性分布式数据集RDD快速入门篇
Posted 大数据小禅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精通Spark系列弹性分布式数据集RDD快速入门篇相关的知识,希望对你有一定的参考价值。
🚀 作者 :“大数据小禅”
🚀文章简介:本篇文章属于Spark系列文章,专栏将会记录从spark基础到进阶的内容,,内容涉及到Spark的入门集群搭建,核心组件,RDD,算子的使用,底层原理,SparkCore,SparkSQL,SparkStreaming等,Spark专栏地址.欢迎小伙伴们订阅💪

RDD入门导航
1.RDD是什么?
RDD(Resilient Distributed Datasets),弹性分布式数据集, 是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建。
1.2 RDD的特点
1.RDD是一个编程模型
- RDD允许用户显式指定数据存放在内存或者磁盘
- RDD是分布式的,用户可以控制RDD的分区
- RDD提供了map,FlatMap,Filter,reduceByKey,groupByKey等操作符用于操作Key-Value型数据
- RDD提供了max,min等操作符用以操作数字型数据
2.RDD是混合型变成模型,可以支持迭代计算,关系查询,MapReduce,流计算
3.RDD是只读的
4.RDD之间有依赖关系,根据执行操作符的不同,依赖关系可以分成宽依赖和窄依赖,如果RDD的每个分区最多只能被一个子RDD的一个分区使用,则 称之为窄依赖。若被多个子RDD的分区依赖,则称之为宽依赖。例如Map操作产生窄依赖,而join操作则产生宽依赖
1.3 RDD在哪?
在IDEA中编码按住Alt+Enter可以显示变量的类型,这里可以看到RDD在哪
1.3 弹性分布式数据集怎么理解
分布式
RDD 支持分区, 可以运行在集群中
弹性
- RDD 支持高效容错
- RDD 中的数据即可以缓存在内存中, 也可以缓存在磁盘中, 也可以缓存在外部存储中
数据集
- RDD 可以不保存具体数据, 只保留创建自己的必备信息, 例如依赖和计算函数
- RDD 也可以缓存起来, 相当于存储具体数据
2.RDD代码编写与创建方式
Spark的入口SparkContext
SparkContext是spark-core的入口组件,作为Spark程序的入口,在Spark0.x版本就存在了,是一个元老级API。主要作用是链接集群,创建RDD,累加器,广播变量等
val conf = new SparkConf().setMaster("local[6]").setAppName("rdd")
val sc = new SparkContext(conf)
创建RDD的三种方式
RDD的创建方式主要有三种
- 1.通过本地集合创建RDD,词频统计的代码就是通过读取一个文件创建了RDD
- 2.通过外部数据创建RDD
- 3.通过RDD衍生新的RDD
代码演示:
//从本地集合创建
def rddLocal(): Unit =
val seq=Seq(1,2,3,4)
//2是指定的分区数,两个创建集合的区别就是parallelize可以不指定分区数
val rdd1=sc.parallelize(seq,2)
sc.parallelize(seq)
val rdd2=sc.makeRDD(seq,2)
rdd2.foreach(println(_))
//从文件创建
def rddnFiles(): Unit =
val value = sc.textFile("file:\\\\\\")
//从RDD衍生
def rddAddRDD(): Unit =
val rdd1=sc.parallelize(Seq(1,2,3))
//通过在rdd上执行算子操作,会生成新的rdd
//原地计算
//str.substr 返回新的字符串,非原地计算
//RDD不可变
val rdd2=rdd1.map(item=>item)
3.深入理解RDD
3.1:RDD为什么会出现
在RDD出现之前,MapReduce 是比较主流的,但是MapReduce任务没有基于内存的数据共享方式,每一次都需要通过磁盘来进行数据共享,这种方式明显是比较低效的。
MapReduce 是如何执行迭代任务的?
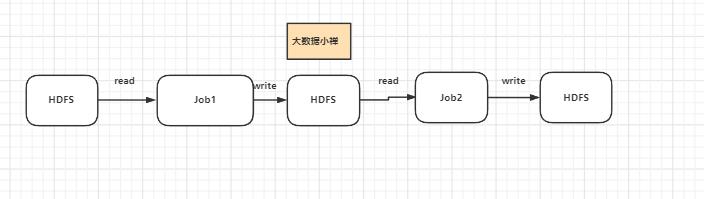
RDD如何解决迭代计算低效的问题?

在spark中 整个计算过程是共享内存的,不需要把中间计算出来的结果先存放到文件系统。这种方式就显得更加的灵活,也拥有更快的执行速度。
4:RDD有什么特点
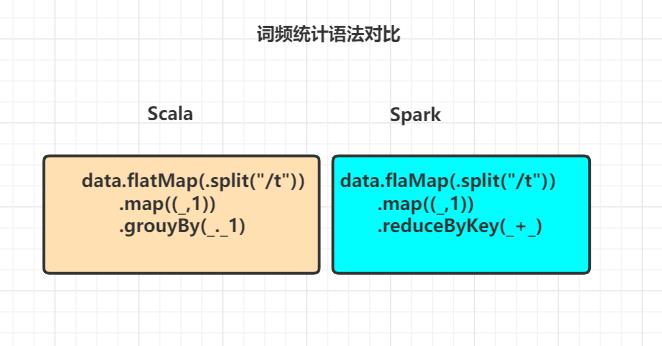
1.RDD 不仅是数据集, 也是编程模型
- RDD 也是一种数据结构, 同时也提供了上层 API, RDD 的 API 跟Scala 中对集合运算的 API 很相似
- scala跟spark的相关API都可以通过链式进行调用
- 都可以通过算子与传入函数来对数据进行相关的操作
2.RDD是可以分区的
- RDD作为一个分布式的计算框架,肯定是具备了分区计算能力的,能利用集群的资源进行并行计算
- RDD不需要始终被具体化,RDD中可以没有数据,知道自己是从哪个RDD计算得来的就可以,是一种高效的容错方式

3.RDD是只读的
RDD是只读的,不允许被修改。为什么要设计成是只读的?
- RDD需要可以容错,可惰性求值,可移动计算,很难支持修改。设计成只读的就显著降低了问题的复杂性,
- 如果想要设计成支持修改,而且必须要保存数据的话,如果保证容错?
- 想要修改的话,如何定位到要修改的那行?RDD的转换为粗粒度吗,并不能准确感知具体要修改的在哪一行
- 结论:RDD生成后就不可以修改变化
4.RDD可以容错
RDD的容错方式
- 可以保存RDD之间的依赖关系,比如说RDD1经过计算得到RDD2,这个时候RDD1与RDD2存在依赖关系。再保存计算函数,如果出现错误就重新计算
- 可以把RDD的数据直接存放到外部的存储系统,比如HDFS,出现错误的话重新读取Checkpoint检查点
🚀文章源码获取 :与本文相关的安装包,大数据交流群,小伙伴们可以关注文章底部的公众号,点击“联系我”备注对应内容获取。
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬
以上是关于精通Spark系列弹性分布式数据集RDD快速入门篇的主要内容,如果未能解决你的问题,请参考以下文章