eclipse下进行spark开发(已实践)
Posted 霏霏暮雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了eclipse下进行spark开发(已实践)相关的知识,希望对你有一定的参考价值。
开发准备:
jdk1.8.45
spark-2.0.0-bin-hadoop2.7(windows下和linux个留一份)
Linux系统(centos或其它)
spark安装环境
hadoop-2.7.2(linux一份)
Hadoop安装环境
开发环境搭建步骤如下:
1. 下载scala-SDK-4.4.1-vfinal-2.11-win32.win32.x86_64.tgz
2. 解压压缩包,直接运行里面的eclipse
3. 创建scala project,并创建scala类WordCount

4. 右键工程属性,添加spark-2.0.0-bin-hadoop2.7下面所有的库,可自定义库放进来:
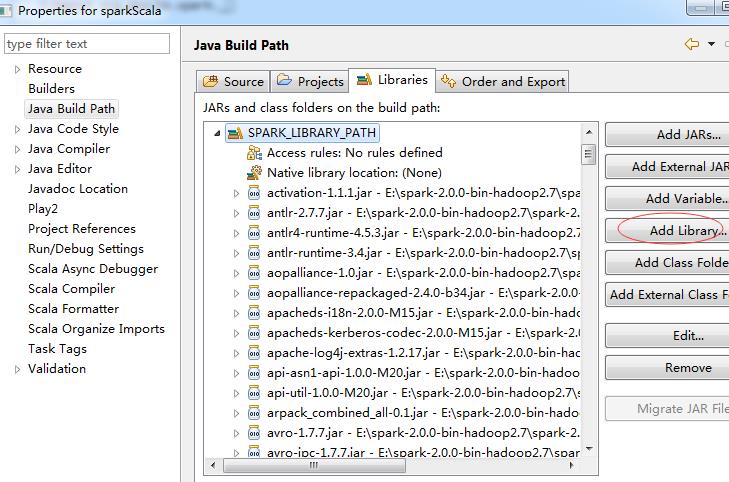
5. 编辑代码如下:
import org.apache.spark._
import SparkContext._
object WordCount {
def main(args: Array[String]) {
if (args.length != 3 ){
println("usage is org.test.WordCount <master> <input> <output>")
return
}
val sc = new SparkContext(args(0), "WordCount",
System.getenv("SPARK_HOME"), Seq(System.getenv("SPARK_TEST_JAR")))
val textFile = sc.textFile(args(1))
val result = textFile.flatMap(line => line.split("\\\\s+"))
.map(word => (word, 1)).reduceByKey(_ + _)
result.saveAsTextFile(args(2))
}
}
6. 右键类,导出jar文件:
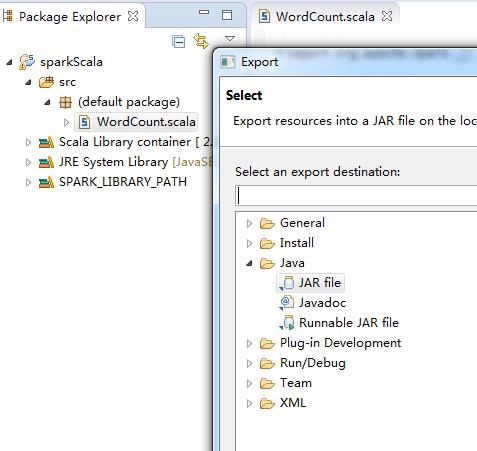
7. 在spark部署路径执行(可以通过spark的日志找到spark的master地址):
./spark-submit --num-executors 1 --executor-memory 1g --class WordCount --master spark://10.130.41.59:7077 spark-wordcount-in-scala.jar spark://10.130.41.59:7077 hdfs://hadoop:9000/user/hadoop/input hdfs://hadoop:9000/user/hadoop/outspark
8. 参数解析:
可以执行./spark-submit --help获得帮助
以上是关于eclipse下进行spark开发(已实践)的主要内容,如果未能解决你的问题,请参考以下文章
spark-windows(含eclipse配置)下本地开发环境搭建
eclipse开发spark应用程序 spark2.1.0 导入哪个jar包
无法启动 Eclipse - Java 已启动但返回退出代码 = 13