eclipse开发spark应用程序 spark2.1.0 导入哪个jar包
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了eclipse开发spark应用程序 spark2.1.0 导入哪个jar包相关的知识,希望对你有一定的参考价值。
在“File|ProjectStructure|Libraries”窗体中点击绿色+号,选择“Java”,在弹出的窗体中选择“Spark”的安装目录,定位到Spark\jars目录,点击“OK”,把全部jar文件引入到项目中。网上和目前出版的书中讲解是spark2.0以下版本,采用的是把sparkle核心文件(如:“spark-assembly-1.3.0-hadoop2.4.0.jar”)拷贝到InterllijIDEA安装目录下的Lib目录下,再使用Spark。由于Spark2.1.0已经取消了该文件,因此无法用原先的方法。 参考技术A 在eclipse中,依次选择“File”–>“New”–>“Other…”–>“ScalaWizard”–>“ScalaProject”,创建一个Scala工程,并命名为“SparkScala”。右击“SaprkScala”工程,选择“Properties”,在弹出的框中,按照下图所示,依次选择“JavaBuildPath”–>“Libraties”–>“AddExternalJARs…”,导入文章“ApacheSpark:将Spark部署到Hadoop2.2.0上”中给出的assembly/target/scala-2.9.3/目录下的spark-assembly-0.8.1-incubating-hadoop2.2.0.jar,这个jar包也可以自己编译spark生成,放在spark目录下的assembly/target/scala-2.9.3/目录中。在Windows下用Eclipse开发和运行Spark程序
我们想现在windows环境下开发调试好spark程序,然后打包,最后放到linux spark集群环境去运行。
Windows环境准备
准备好Eclipse开发环境,最好是支持scala语言的。可以到scala的官网上下载:http://scala-lang.org/download/

下载Spark的assembly开发jar包:http://spark.apache.org/downloads.html

解压后,找到spark-1.5.0-bin-hadoop2.6\\lib\\spark-assembly-1.5.0-hadoop2.6.0.jar,创建spark工程的时候需要导入下载Hadoop的bin包:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.0/ ,解压后,在windows中增加环境变量HADOOP_HOME,值为解压后的目录

下载winutils.exe:http://download.csdn.net/detail/luoyepiaoxin/8860031 ,将其放到$HADOOP_HOME/bin/目录下
Windows本地测试运行
可以参考文章:http://blog.csdn.net/pangjiuzala/article/details/50389823,其中logFile指定的地址根据你Hadoop环境上的地址和端口进行修改
打包
为了可以选择哪些第三方库打进jar包,我们需要安装Fat Jar Eclipse插件。
- 由于我们下载的Scala Eclipse版本较高,最新的Fat Jar不支持,请参考这篇文章进行安装 Fat Jar:http://blog.csdn.net/gfxjj123/article/details/51163453 。安装插件的时候,请注意看Eclipse右下角的进度条。
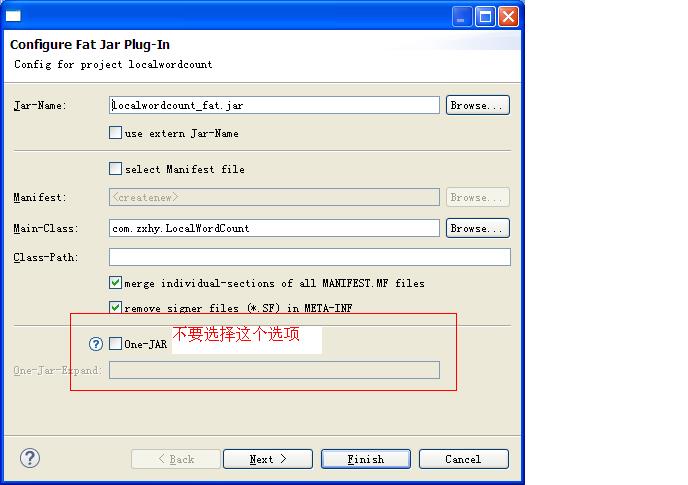
- 安装好Fat Jar之后,具体怎么打包,可以参考这篇文章:http://jingyan.baidu.com/article/da1091fbd7dae1027849d63b.html 。 这里需要注意,我们打完jar包后,是通过spark-submit脚本提交给spark集群,在Fat Jar打包界面中,不要选择One-JAR选项。
提交Spark集群
在spark集群中的一台机器上执行类似于这样的命令:
spark-submit --class com.zxhy.LocalWordCount --master yarn --deploy-mode client --executor-memory 1g --num-executors 3 --name wordcount --conf "spark.app.id=Localwordcount" /home/hadoop/localwordcount_fat.jarspark-submit参数的含义请参考官方文档:http://spark.apache.org/docs/latest/submitting-applications.html
以上是关于eclipse开发spark应用程序 spark2.1.0 导入哪个jar包的主要内容,如果未能解决你的问题,请参考以下文章
spark2.x由浅入深深到底系列五之python开发spark环境配置
01_PC单机Spark开发环境搭建_JDK1.8+Spark2.3.1+Hadoop2.7.1
大数据开发岗面试复习30天冲刺 - 日积月累,每日五题Day15——Spark2