机器学习基础笔记:最简单的线性分类器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基础笔记:最简单的线性分类器相关的知识,希望对你有一定的参考价值。
监督学习多用来解决分类问题,输入的数据由特征和标签两部分构成。我们由浅入深地介绍一些经典的有监督的机器学习算法。
这里介绍一些比较简单容易理解的处理线性分类问题的算法。
线性可分&线性不可分
首先,什么是线性分类问题?线性分类问题是指,根据标签确定的数据在其空间中的分布,可以使用一条直线(或者平面,超平面)进行分割。如下图就是一个线性分类问题。这样的问题也叫做线性可分的。

当然,也存在着许多线性不可分的情况,例如下图所示
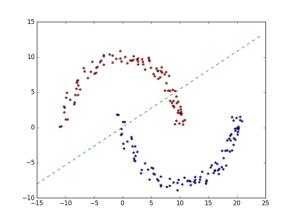
解决线性不可分问题往往相对复杂,我们从简单的线性可分问题开始探讨。
最简单的线性分类器——决策树桩
线性分类器,简单来说就是一些可以用来解决线性可分问题的机器学习算法,这些算法生成的模型往往都是一个线性函数,因此不一定能很好的解决线性不可分的问题。
决策树桩,可以说是最简单的线性分类器了,它的分类原理很简单:
1、决定一个阈值
2、大于这个阈值的是第一类,小于这个阈值的是第二类。(等于阈值的情况任意取舍即可)
决策树桩能解决的问题很有限,但是也并不是全无用途。例如我们对如下数据进行分类
数据:5个拉拉队员的数据
| 拉拉队员 | 身高 | 体重 | 性别 |
| 1 | 170 | 55 | 男 |
| 2 | 160 | 45 | 女 |
| 3 | 180 | 65 | 男 |
| 4 | 165 | 50 | 女 |
| 5 | 170 | 50 | 女 |
如果说我们想根据拉拉队员的身高体重队其性别进行分类,那么很明显,体重大于50的都是男队员,小于或等于50的都是女队员。因此决策树桩是完全可以解决这个问题的,那么剩下的工作就是如何让机器根据这些数据自己学习到合适的阈值。设计出来的算法就是决策树桩的学习算法了。
为此我们将问题更加细化一下,我们使用体重作为特征(X),性别作为标签进行分类(Y = 1 判断性别为男,Y = 0判断为女)
决策树桩的模型是一个一维的线性模型,因此其模型函数可以看做是 f(x) = (x - t), 其中t是阈值,我们规定,当f(x)>0时, 预测Y = 1,否则,预测Y = 0。为了找到一个合适的t使用最简单的线性搜索就可以解决。算法如下:
input: 特征x,真实标签Y,学习步长L
L = 1; minErr = 99999;
for t = min(x) to max(x) by L do
numErr = numberOfErrors(t)
if numErr <= minErr
minErr = numErr
tbest = t
end if
end for
return tbest
在这个算法中,我们从x的最小值开始搜索,直到x的最大值。每次更新t时给t增加L这么大。numberOfErrors 函数用来统计我们在t作为阈值的情况下,分类的错误数目,这样搜索了一遍后,就能找到一个错误最少的tbest作为我们决策树桩的阈值。
其中学习步长L的作用十分重要,如果L过大的话,可能会不小心错过最优解,但是L过小的话,又会导致算法运行时间过长。因此调整一个合适的L值是十分必要的。
以上是关于机器学习基础笔记:最简单的线性分类器的主要内容,如果未能解决你的问题,请参考以下文章