机器学习基础4--评估线性分类
Posted redheat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基础4--评估线性分类相关的知识,希望对你有一定的参考价值。
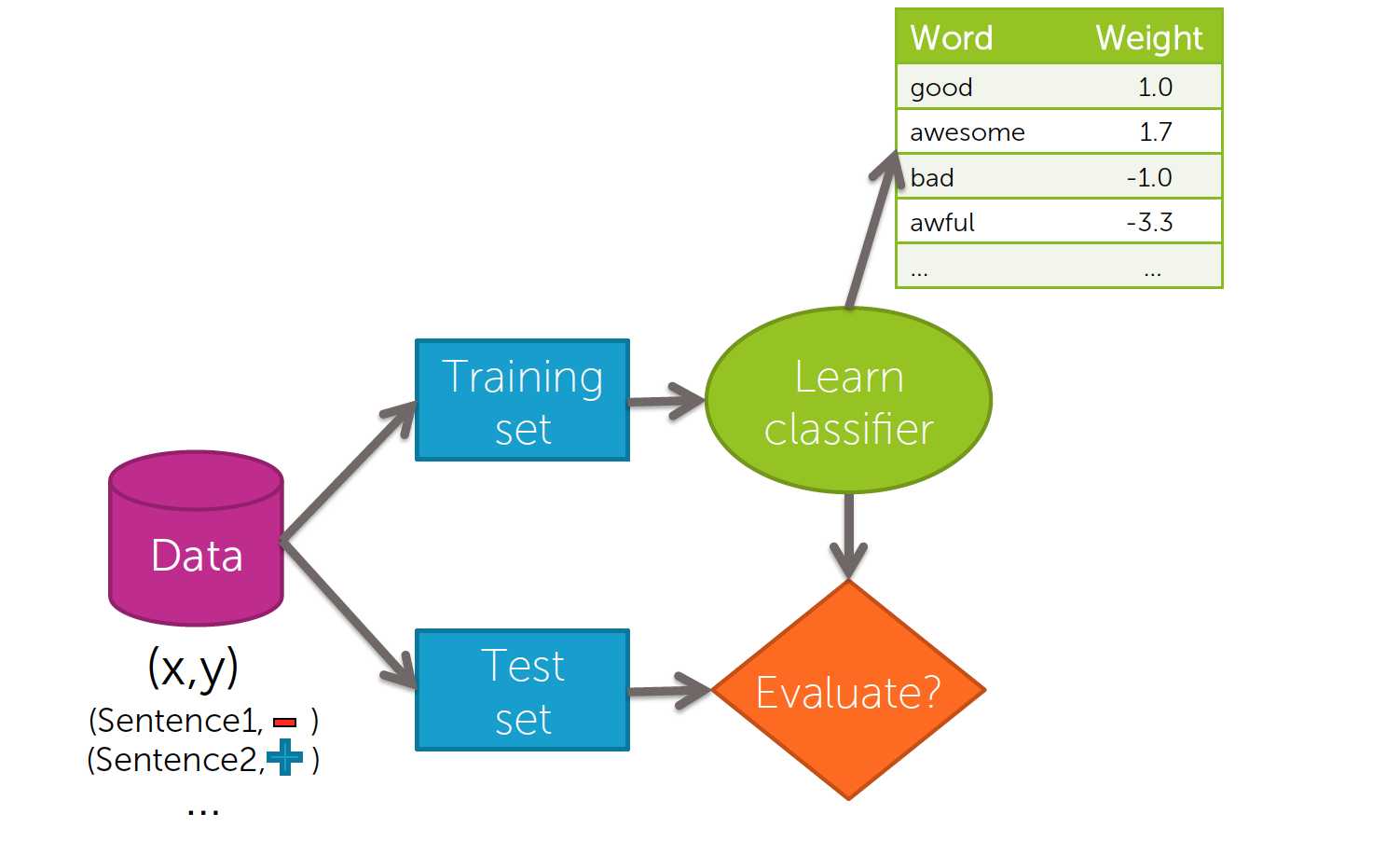
如线性回归一样,我们也分成了训练集和测试集.
用训练集进行分类器的学习,用测试集来评估分类错误.
分类错误:
测试集 -> 隐藏类型标签 -> 放到分类器进行处理 -> 得出结果 -> 与定义好的类型标签进行比较
错误率:
分类错误数/总句子数
正确率:
分类正确数/总句子数
那么,什么样的正确率才是好的?
至少要比随机猜测效果要好.
如果有k个分类,那么正确率至少要大于等于1/k
同时要关注是否有意义:
2010年,全球有90%的邮件是垃圾邮件.而只要说所有邮件都是垃圾邮件,就有90%的正确率!
错误:
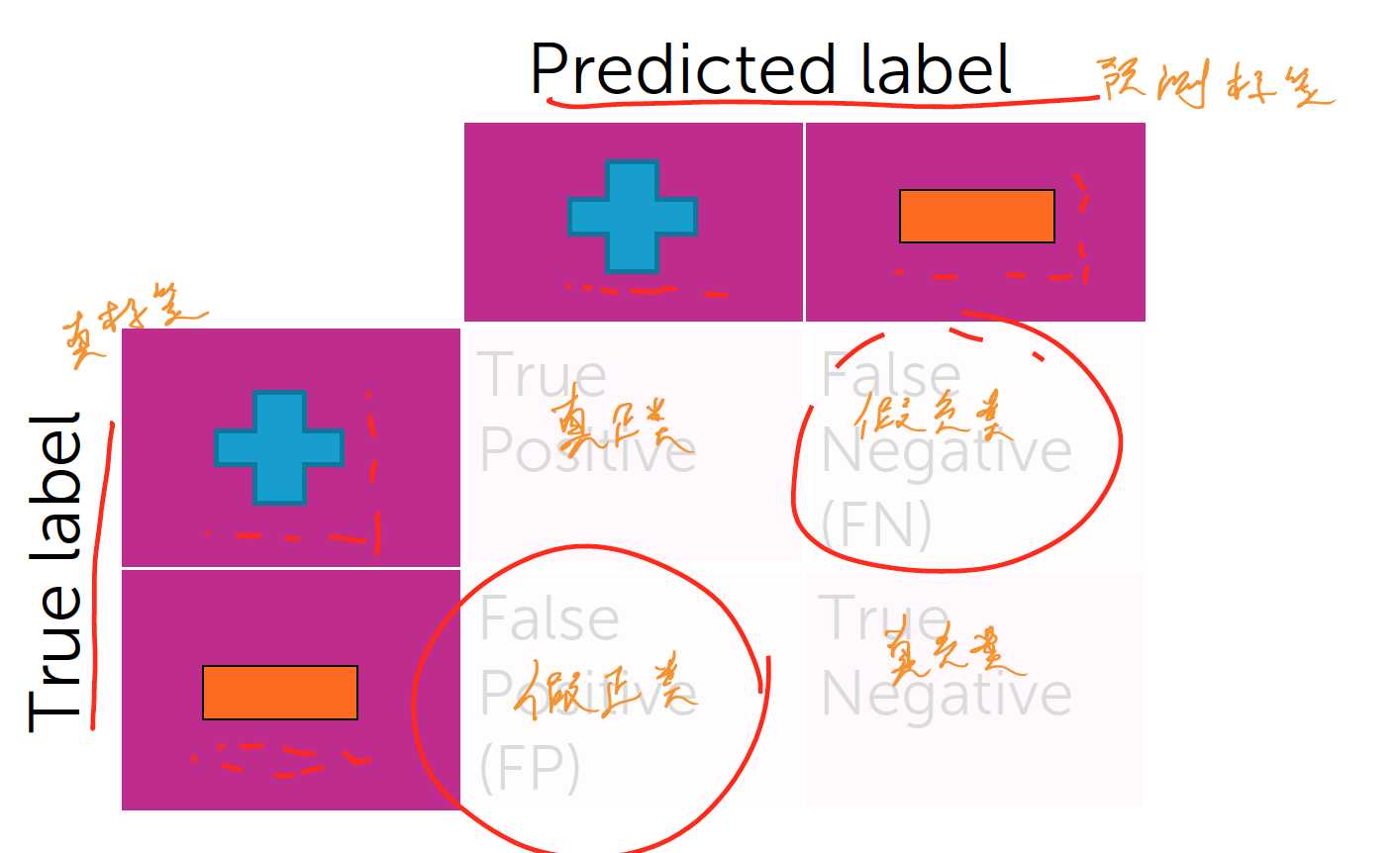
偏差:
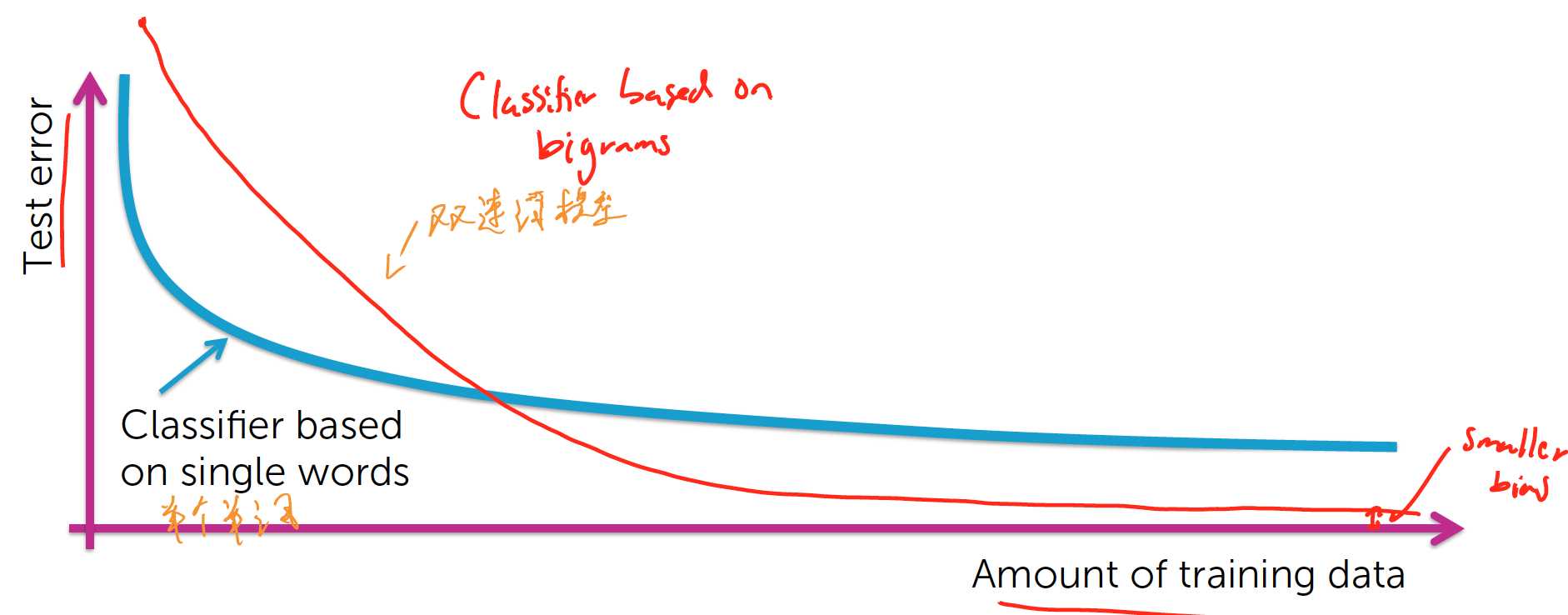
通常来说,数据量越大,偏差就会越小.
但是,即使有无限多的数据,偏差也不会为0.

那么,前文我们提到的good和not good呢?
即使再多的数据,也永远分辨不出这句话:
The sushi was not good.
双连词模型:
在大数据量训练的情况下,双连词模型拥有更小的偏差.
但是,一个句子不可能只包含正面和负面的预测,还应该包括对这个预测的信心有多大.
“The sushi & everything else were awesome!” P(y=+|x) = 0.99
“The sushi was good, the service was OK.” P(y=+|x) = 0.55
即:概率是多大.
end
课程:机器学习基础:案例研究(华盛顿大学)
视频链接:https://www.coursera.org/learn/ml-foundations/home/welcome
week3 Evaluating classification models
以上是关于机器学习基础4--评估线性分类的主要内容,如果未能解决你的问题,请参考以下文章