数据库"范式"
Posted 杨龙飞的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库"范式"相关的知识,希望对你有一定的参考价值。
1.为什么要学习数据库”范式”?
当我们独立去完成一个自己的小项目的时候,肯定要去设计”合适”的数据模型即逻辑架构,那么,我们怎么知道自己设计的数据模型是最”合适”的呢?肯定得有一个标准去衡量自己设计的数据模型,看到这里,大家知道为什么要学习范式了.
2.”范式”能解决什么问题?
刚才说过,学习范式是为了去设计一个”合适的”数据模型,那么,一个”合适”的数据模型,它能解决什么问题呢?
1.消除数据冗余.
2.消除更新异常.
3.消除插入异常
4.消除删除异常.
3.范式的概念
范式是符合某一种级别的关系模式的集合,它是关系数据库理论的基础,也是我们在设计数据库结构中所要尊循的规则和指导方法. 数据库有5个基本的范式:即第一范式(1NF),第二范式(2NF),第三范式(3NF),BCNF(BC范式),第四范式(4NF)。甚至还有5NF,6NF,DK范式,本文只讨论前面五种范式,这五种范式,就是为了解决第二个点中所说的问题.从1NF到4NF逐级提高标准,大家可以把它理解为猿到人的进化过程。
4.具体的例子
用一个具体的例子来分析这几种范式.
| 学号 | 姓名 | 系名 | 宿舍楼 | 课程号 | 成绩 |
|---|---|---|---|---|---|
| 03001 | 周毅 | 电信系 | A楼 | 语文 | 95 |
| 03001 | 周毅 | 电信系 | A楼 | 数学 | 89 |
| 04015 | 崔勇 | 计算机系 | C楼 | 大物 | 70 |
| 04015 | 崔勇 | 计算机系 | C楼 | 英语 | 85 |
| 03018 | 王文涛 | 电信系 | A楼 | 语文 | 87 |
| 03019 | 马季军 | 法律系 | B楼 | 大物 | 88 |
| 03019 | 贺智平 | 法律系 | B楼 | 大物 | 56 |
在上面提到了关系模式.而这张表的关系有
1.学号(x)–>姓名(y).
2.学号(x)–>系名(y).
3.系名(x)–>宿舍楼(y).
4.(学号,课程)(x)–>成绩(y).
怎样去理解上面的关系呢?它们的关系就是y=x^2,当x确定时,y一定有唯一值,即x唯一确定y.
4.几种特殊的函数依赖
1.平凡函数依赖:如果A属性组唯一确定B,并且B属性属于A属性组,那么A–>B是平凡函数依赖。eg:在上表中(学号,课程)—>课程.课程属于(学号,课程)这个属性组. 对于任以关系模式,平凡函数依赖都是成立的。所以,讨论它是,没有意义的,所以大家了解就行.
2.非平凡函数依赖:如果A属性组唯一确定B,并且B属性不属于A属性组,那么A—>B是非平凡函数依赖.eg:在上表中(学号,课程)—->成绩,成绩不属于(学号,课程)这个属性组,所以是非平凡函数依赖.
3.部分函数依赖:A属性组可以确定B,但是B不完全依赖于X,什么意思呢,eg(学号,课程)—>姓名.(学号,课程)可以唯一确定姓名,但是姓名只需要一个学号就能唯一确定,没有课程也可以,这就称B部分依赖A.
4.完全函数依赖:A属性组唯一确定B,并且A属性组的任何一个真子集不能唯一确定B。那么称B完全依赖于A.eg: (学号,课程)–>成绩.(学号,课程中的任何一个都不能唯一确定成绩),所以说成绩完全依赖于(学号,课程);
5.传递函数依赖:如果属性A–>B,B–>C,那么A–>C.且B不属于A,B也不能唯一确定A,那么A–>C.eg:学号—>系名,系名—>宿舍楼. 那么学号—>宿舍楼.为传递函数依赖.
6.码:一个属性或者属性组能唯一确定本属性或属性组之外的所有属性,即其它属性完全依赖此属性或属性组.eg(学号,课程)唯一确定(姓名,系名,宿舍楼,成绩),那么,怎样去找码呢,如果有n个属性列,那么所有的组合,一个属性的组合n种,二个属性的组合,Cn2(代表从n个中任意取两个),三个属性的组合Cn3(代表从n个中任意取三个)……….当然,不可能一个一个去试.那是有技巧的,当你已经知道(学号,课程)是码,那么以后,包含这个列的组成直接忽略.因为码是完全函数依赖.
7.主属性:码中包含的属性叫做主属性.
8.非主属性:除过码中包含的属性之外的所有属性.
9.单码:单个属性是码.
10.全码:整个属性组是码,称为全码.
6.第一范式(1NF)
如果关系模式R中不包含多值属性,则R满足第一范式.并且,关系模式中所有的属性都是不可再分事务数据项,第一范式是对关系模式的最低要求,不满足第一范式的数据库模式称为关系型数据库. 具体来看个例子吧:
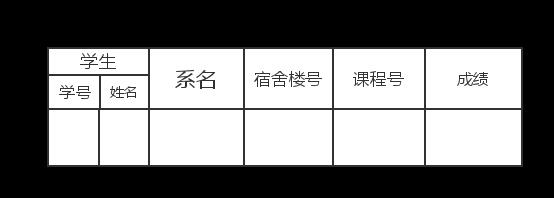
在上面这个表中,学生对应(学号,姓名),明显学生既对应学号,又对应姓名.所以,这应该分开做出调整,第一张(下面这张表就满足第一范式).
| 学号 | 姓名 | 系名 | 宿舍楼 | 课程号 | 成绩 |
|---|---|---|---|---|---|
| 03001 | 周毅 | 电信系 | A楼 | 语文 | 95 |
| 03001 | 周毅 | 电信系 | A楼 | 数学 | 89 |
| 04015 | 崔勇 | 计算机系 | C楼 | 大物 | 70 |
| 04015 | 崔勇 | 计算机系 | C楼 | 英语 | 85 |
| 03018 | 王文涛 | 电信系 | A楼 | 语文 | 87 |
| 03019 | 马季军 | 法律系 | B楼 | 大物 | 88 |
| 03020 | 贺智平 | 法律系 | B楼 | 大物 | 56 |
在看上面我们提到的4个范式我们要解决的4个问题,第一范式是否解决了上面的问题,解决了几个:
* 数据冗余可以看到姓名,系名,宿舍楼大量的重复.
* 更新异常:如果一个学生改名,则关于这个学生的所有的选课元组都得更新(eg:如果周毅改名,则需要去改两列).
* 删除异常:如果计算机的系的学生全部毕业,相应的计算机系以及C楼的信息也会被删除.
* 插入异常:如果学校新开了某个系,但是没有招学生,这个系就无法插入.
7.第二范式(2NF)
在第一范式的基础上,如果每个非主属性对主属性都达到了完全函数依赖,则满足第二范式的要求(2NF),换去话说,就是消除所有非主属性对主属性的部分函数依赖(ps:这是第二范式的要求),那么,怎么去分析呢?看我们上面的例子:
主属性:(学号,课程); ps:主属性必须是码哦.
非主属性:姓名,系,宿舍楼,成绩.
(学号,课程)—>姓名: 姓名由学号就能唯一确定,所以姓名对(学号,课程)是部分函数依赖.
(学号,课程)—>系:系和姓名一样,由学号能唯一确定.
为了消除关系模式中的部分函数依赖,采用投影分解法,将部分函数依赖从关系模式中分离出来,得到以下两张表.
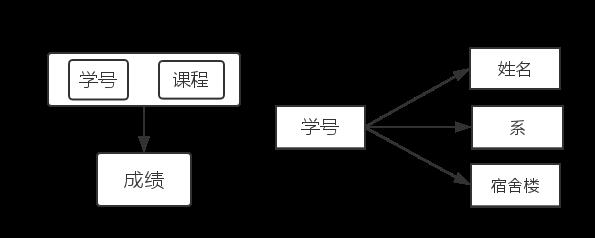
SC(学号,课程,成绩);
SL(学号,姓名,系名,宿舍楼);
得到两张表分别为:
SC表
| 学号 | 课程 | 成绩 |
|---|---|---|
| 03001 | 语文 | 95 |
| 03001 | 数学 | 89 |
| 04015 | 大物 | 70 |
| 04015 | 英语 | 85 |
| 03018 | 语文 | 87 |
| 03019 | 大物 | 88 |
| 03020 | 大物 | 56 |
S表
| 学号 | 姓名 | 系名 | 宿舍楼 |
|---|---|---|---|
| 03001 | 周毅 | 电信系 | A楼 |
| 04015 | 崔勇 | 计算机系 | C楼 |
| 03018 | 王文涛 | 电信系 | A楼 |
| 03019 | 马季军 | 法律系 | B楼 |
| 03020 | 贺智平 | 法律系 | B楼 |
在看上面提到的4个问题我们解决了几个:
数据冗余:明显的可以看出姓名,系名,系主任的数据冗余得到了明显的改善.
更新异常:现在,一个学生改名,,只需要改S表中的姓名,而没有必要改他的每一条选课记录.
插入异常:如果现在学校新开设一个系,在没有招生的情况下,系还是不能插入到S表中,因为学号是主属性.()
删除异常:一个系的所有学生毕业,再删除所有学生信息的同时,会连带着删掉所有系的信息.
既然第二范式只是降低了数据冗余度,其它的并没有得到提高. 那么,接着,我们一起来看第三范式:
8.第三范式(3NF)
同样,第三范式是建立在第二范式的基础上.而第三范式的目的是消除非主属性对主属性的传递函数依赖.
在第二范式中,我们得到了两张表:
SC表:选课(学号,课程,成绩).
S表:(学号,姓名,系名,宿舍楼)
还记得什么是传递函数依赖吧,如果忘了,翻到上面去看看.分析SC表,我们发现,不存在传递函数依赖,而在S表(学号)–>(系名) (系名)—>(宿舍楼)存在传递函数依赖,那我们就解决了这个传递函数依赖,看看上面的问题能不能得到改善呢?
SC表:选课(学号,课程,分数)
S表:学生(学号,姓名,系名);
D表:系(系,宿舍楼);
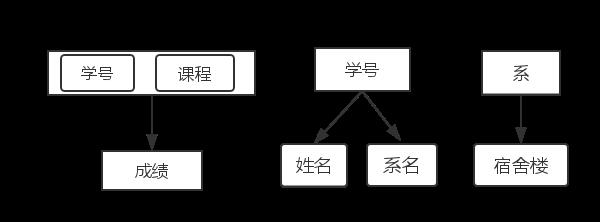
得到三张表
SC表
| 学号 | 课程 | 成绩 |
|---|---|---|
| 03001 | 语文 | 95 |
| 03001 | 数学 | 89 |
| 04015 | 大物 | 70 |
| 04015 | 英语 | 85 |
| 03018 | 语文 | 87 |
| 03019 | 大物 | 88 |
| 03020 | 大物 | 56 |
S表
| 学号 | 姓名 | 系名 |
|---|---|---|
| 03001 | 周毅 | 电信系 |
| 04015 | 崔勇 | 计算机系 |
| 03018 | 王文涛 | 电信系 |
| 03019 | 马季军 | 法律系 |
| 03020 | 贺智平 | 法律系 |
D表
| 系 | 宿舍楼 |
|---|---|
| 电信系 | A楼 |
| 法律系 | B楼 |
| 计算机系 | C楼 |
再看上面的问题我们第三范式解决了几个:
插入异常:如果现在学校新开设一个系.就算没有纳入招生计划,此系还是可以插入到D表中.
删除异常,就算现在一个系中的所有学生都毕业了,删除这个系的所有学生的信息,这个系的信息也不会被删除。
大家可以发现,到现在为止,数据冗余,更新异常,插入异常,删除异常都得到了改善.它已经能基本满足我们的需要了.
9.BC范式(BCNF)
BC范式:BC范式是在第三范式的基础上的一种特殊情况,既每个表只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键)。
每一个决定因素都为键,则R一定属于BC范式,对于BCNF的关系模式,具有以下性质:
(1)所有非主属性都完全依赖于每个主属性.(在第二范式2NF中已经实现)
(2)所有主属性对每一个不包含它的主属性都是完全函数依赖;
(3)没有任何属性完全函数依赖于非主属性中任何一组属性. (第三范式中已经实现)
那么,BC范式就是完全针对主属性而言的,即上面所说的第二条.所有主属性对每一个不包含它的主属性都是完全函数依赖;
看个具体的例子
假设仓库管理关系表为storehourseMange(仓库ID,存储物品ID,管理员ID,数量).
| 仓库ID | 存储物品ID | 管理员ID | 数量 |
|---|---|---|---|
| A1 | S1 | C1 | 20 |
| A1 | S2 | C1 | 30 |
| A2 | S3 | C2 | 40 |
| A2 | S4 | C2 | 50 |
| A2 | S5 | C2 | 60 |
此表满足:
- 一个管理员只在一个仓库工作
- 一个仓库可以存储多种物品
这个数据库表存在如下决定关系:
(仓库ID,存储物品ID)—->(管理员ID,数量)
(管理员ID,存储物品ID)—>(仓库ID,数量)
主属性:仓库ID,存储物品ID,管理员ID.
非主属性:数量.
码(还记得码的概念吧,不记得了翻上去看看):(仓库ID,存储物品ID),(管理员ID,存储物品ID).
先来确定这个张表是否满足第三范式(3NF),因为BCNF范式是建立在第三范式的基础之上的.
分析表可以看出.不存在非主属性对对主属性的部分函数依赖和传递函数依赖.满足第三范式.
那么先来看看上面提到的四个问题:
数据冗余:看表很明显这个问题不存在.
插入异常:如果现在新建一个仓库,但是不给这个仓库中存任何物品,那么,此条数据无法存入.
删除异常:如果某个仓库的物品全部出库,删除这个物品的同时,对应的仓库也会被删除.
更新异常:如果某个仓库换了管理员,则要改多条数据.
原因是什么呢?
看这个关系(仓库ID,)
(管理员ID,存储物品ID)—->(仓库ID);看这个关系,三个属性都是主属性,但是(管理员ID就能唯一确定仓库ID),所以仓库ID对(管理员ID,存储物品ID)存在部分函数依赖.
分解表得到:
仓库:(仓库ID,管理员ID);
物品:(仓库ID,存储物品ID,数量);
仓库:
| 仓库ID | 管理员ID |
|---|---|
| A1 | C1 |
| A2 | C2 |
物品:
| 仓库ID | 存储物品ID | 数量 |
|---|---|---|
| A1 | S1 | 20 |
| A1 | S2 | 30 |
| A2 | S3 | 40 |
| A2 | S4 | 50 |
| A2 | S5 | 60 |
再看刚才的问题:
- 插入异常: 新建一个仓库,就算里面没有东西,也可以插入仓库表.
- 更新异常:,某个仓库的管理员换了,则只需要改仓库表中的一条数据.
- 删除异常:某个仓库的物品全部出库,此仓库也不会被删除.
10.第四范式(4NF)
上面解决的是在函数依赖的范畴内有关关系模式的规范化问题,如果一个关系模式达到了BCNF,是否就完美了。看下面这个例子:
在一个教学管理系统中,有一个关系模式Teaching(C,T,B),其中C表示课程,T表示教师,B表示参考书.
存在如下关系:
- 一门课程由多个老师讲授,它们使用同一套参考书.
- 每个老师可以讲授多门课程,每本参考书可以供多门课程使用.
| 课程C | 教师T | 参考书B |
|---|---|---|
| 数据库原理及应用 | 邓宇 | 数据库系统概论 |
| 数据库原理及应用 | 邓宇 | SQL Server2000 |
| 数据库原理及应用 | 邓宇 | 离散数学 |
| 数据库原理及应用 | 孙泽 | 数据库系统概论 |
| 数据库原理及应用 | 孙泽 | 数据库系统概论 |
| 数据库原理及应用 | 孙泽 | 数据库系统概论 |
| 数据结构 | 孙泽 | 数据结构与算法 |
| 数据结构 | 孙泽 | 数据结构 |
| 数据结构 | 孙泽 | 离散数学 |
| 数据结构 | 曹鹏 | 数据结构与算法 |
| 数据结构 | 曹鹏 | 数据结构与算法 |
| 数据结构 | 曹鹏 | 离散数学 |
很显然:这张表是全键;
先来看上面所提到的4个问题:
- 数据冗余:课程,教师,参考书的有关信息大量重复存储.
- 插入异常:当某门课增加一个任课老师,必须插入多个元组.
- 更新异常:如果某门课换了老师,则必须修改多行值.
- 删除异常:若要删除某一本参考书,则需要删除多条记录.
这张表为什么会出现这样的问题呢?
大家先来看看这张表的关系:
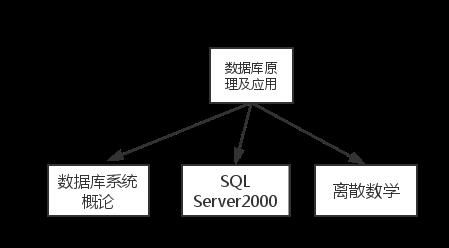
一门课程有多本参考书,很明显是一对多的关系. 也就是说课程对参考书有多值依赖关系。
刚才说到了多值依赖,那么,先来看看什么叫做多值依赖:
设R(U)是属性集U上的一个关系模式,X,Y,Z是U的子集,且Z=U-X-Y.关系模式R(U)中多值依赖X–>—>Y成立,当且仅当对R(U)的任一关系r,给定的一对(x,z)值,有一组Y的值.这组值仅仅决定x的值而与z的值无关.
eg: 在上面的关系模式中,对于一个(C,B)值(数据库原理及应用,SQL Server 2000),有一组T值{邓宇,孙泽},而这组值仅仅决定于课程C(数据库原理及应用),所以T的值与B的值无关m仅由C决定,C—>—>T;
将上表分解为两个关系模式:
T(课程C,教师T) ;
B(课程C,参考书) ;
关系T
| 课程C | 教师T |
|---|---|
| 数据库原理及应用 | 邓宇 |
| 数据库原理及应用 | 孙泽 |
| 数据结构 | 孙泽 |
| 数据结构 | 曹鹏 |
关系B
| 课程C | 参考书B |
|---|---|
| 数据库原理及应用 | 数据库系统概论 |
| 数据库原理及应用 | SQL Server2000 |
| 数据库原理及应用 | 离散数学 |
| 数据结构 | 数据结构与算法 |
| 数据结构 | 数据结构 |
| 数据结构 | 离散数学 |
看看上面的问题有没有得到改善:
- 信息冗余: 得到改善;
- 插入问题:某个课程增加老师季,只要在T表中添加一条记录就好了.
- 删除问题:删除一本书,也只要在BC表中删除一条记录即可.
总结一下:
- 上面对于数据库范式进行分解的过程中不难看出,应用的范式登记越高,则表越多。表多会带来很多问题:
- 查询时要连接多个表,增加了查询的复杂度.
- 查询时需要连接多个表,降低了数据库查询性能.
- 而现在的情况,磁盘空间成本基本可以忽略不计,所以数据冗余所造成的问题也并不是应用数据库范式的理由。
- 因此,并不是应用的范式越高越好,要看实际情况而定。第三范式已经很大程度上减少了数据冗余,并且减少了造成插入异常,更新异常,和删除异常了。我个人观点认为,大多数情况应用到第三范式已经足够,在一定情况下第二范式也是可以的。
以上是关于数据库"范式"的主要内容,如果未能解决你的问题,请参考以下文章